Lesson 26: Best Critical Regions
Lesson 26: Best Critical RegionsIn this lesson, and the next, we focus our attention on the theoretical properties of the hypothesis tests that we've learned how to conduct for various population parameters, such as the mean \(\mu\) and the proportion p. Specifically, in this lesson, we will investigate how we know that the hypothesis tests we've learned use the best critical, that is, most powerful, regions.
26.1 - Neyman-Pearson Lemma
26.1 - Neyman-Pearson LemmaAs we learned from our work in the previous lesson, whenever we perform a hypothesis test, we should make sure that the test we are conducting has sufficient power to detect a meaningful difference from the null hypothesis. That said, how can we be sure that the T-test for a mean \(\mu\) is the "most powerful" test we could use? Is there instead a K-test or a V-test or you-name-the-letter-of-the-alphabet-test that would provide us with more power? A very important result, known as the Neyman Pearson Lemma, will reassure us that each of the tests we learned in Section 7 is the most powerful test for testing statistical hypotheses about the parameter under the assumed probability distribution. Before we can present the lemma, however, we need to:
- Define some notation
- Learn the distinction between simple and composite hypotheses
- Define what it means to have a best critical region of size \(\alpha\). First, the notation.
If \(X_1 , X_2 , \dots , X_n\) is a random sample of size n from a distribution with probability density (or mass) function \f(x; \theta)\), then the joint probability density (or mass) function of \(X_1 , X_2 , \dots , X_n\) is denoted by the likelihood function \(L (\theta)\). That is, the joint p.d.f. or p.m.f. is:
\(L(\theta) =L(\theta; x_1, x_2, ... , x_n) = f(x_1;\theta) \times f(x_2;\theta) \times ... \times f(x_n;\theta)\)
Note that for the sake of ease, we drop the reference to the sample \(X_1 , X_2 , \dots , X_n\) in using \(L (\theta)\) as the notation for the likelihood function. We'll want to keep in mind though that the likelihood \(L (\theta)\) still depends on the sample data.
Now, the definition of simple and composite hypotheses.
- Simple hypothesis
-
If a random sample is taken from a distribution with parameter \(\theta\), a hypothesis is said to be a simple hypothesis if the hypothesis uniquely specifies the distribution of the population from which the sample is taken. Any hypothesis that is not a simple hypothesis is called a composite hypothesis.
Example 26-1

Suppose \(X_1 , X_2 , \dots , X_n\) is a random sample from an exponential distribution with parameter \(\theta\). Is the hypothesis \(H \colon \theta = 3\) a simple or a composite hypothesis?
Answer
The p.d.f. of an exponential random variable is:
\(f(x) = \dfrac{1}{\theta}e^{-x/\theta} \)
for \(x ≥ 0\). Under the hypothesis \(H \colon \theta = 3\), the p.d.f. of an exponential random variable is:
\(f(x) = \dfrac{1}{3}e^{-x/3} \)
for \(x ≥ 0\). Because we can uniquely specify the p.d.f. under the hypothesis \(H \colon \theta = 3\), the hypothesis is a simple hypothesis.
Example 26-2

Suppose \(X_1 , X_2 , \dots , X_n\) is a random sample from an exponential distribution with parameter \(\theta\). Is the hypothesis \(H \colon \theta > 2\) a simple or a composite hypothesis?
Answer
Again, the p.d.f. of an exponential random variable is:
\(f(x) = \dfrac{1}{\theta}e^{-x/\theta} \)
for \(x ≥ 0\). Under the hypothesis \(H \colon \theta > 2\), the p.d.f. of an exponential random variable could be:
\(f(x) = \dfrac{1}{3}e^{-x/3} \)
for \(x ≥ 0\). Or, the p.d.f. could be:
\(f(x) = \dfrac{1}{22}e^{-x/22} \)
for \(x ≥ 0\). The p.d.f. could, in fact, be any of an infinite number of possible exponential probability density functions. Because the p.d.f. is not uniquely specified under the hypothesis \(H \colon \theta > 2\), the hypothesis is a composite hypothesis.
Example 26-3
Suppose \(X_1 , X_2 , \dots , X_n\) is a random sample from a normal distribution with mean \(\mu\) and unknown variance \(\sigma^2\). Is the hypothesis \(H \colon \mu = 12\) a simple or a composite hypothesis?
Answer
The p.d.f. of a normal random variable is:
\(f(x)= \dfrac{1}{\sigma\sqrt{2\pi}} exp \left[-\dfrac{(x-\mu)^2}{2\sigma^2} \right] \)
for \(−∞ < x < ∞, −∞ < \mu < ∞\), and \(\sigma > 0\). Under the hypothesis \(H \colon \mu = 12\), the p.d.f. of a normal random variable is:
\(f(x)= \dfrac{1}{\sigma\sqrt{2\pi}} exp \left[-\dfrac{(x-12)^2}{2\sigma^2} \right] \)
for \(−∞ < x < ∞\) and \(\sigma > 0\). In this case, the mean parameter \( \mu = 12\) is uniquely specified in the p.d.f., but the variance \(\sigma^2\) is not. Therefore, the hypothesis \(H \colon \mu = 12\) is a composite hypothesis.
And, finally, the definition of a best critical region of size \(\alpha\).
- Size of \(alpha\)
-
Consider the test of the simple null hypothesis \(H_0 \colon \theta = \theta_0\) against the simple alternative hypothesis \(H_A \colon \theta = \theta_a\). Let C and D be critical regions of size \(\alpha\), that is, let:
\(\alpha = P(C;\theta_0) \) and \(\alpha = P(D;\theta_0) \)
Then, C is a best critical region of size \(\alpha\) if the power of the test at \(\theta = \theta_a\) is the largest among all possible hypothesis tests. More formally, C is the best critical region of size \(\alpha\) if, for every other critical region D of size \(\alpha\), we have:
\(P(C;\theta_\alpha) \ge P(D;\theta_\alpha)\)
that is, C is the best critical region of size \(\alpha\) if the power of C is at least as great as the power of every other critical region D of size \(\alpha\). We say that C is the most powerful size \(\alpha\) test.
Now that we have clearly defined what we mean for a critical region C to be "best," we're ready to turn to the Neyman Pearson Lemma to learn what form a hypothesis test must take in order for it to be the best, that is, to be the most powerful test.
Suppose we have a random sample \(X_1 , X_2 , \dots , X_n\) from a probability distribution with parameter \(\theta\). Then, if C is a critical region of size \(\alpha\) and k is a constant such that:
\( \dfrac{L(\theta_0)}{L(\theta_\alpha)} \le k \) inside the critical region C
and:
\( \dfrac{L(\theta_0)}{L(\theta_\alpha)} \ge k \) outside the critical region C
then C is the best, that is, most powerful, critical region for testing the simple null hypothesis \(H_0 \colon \theta = \theta_0\) against the simple alternative hypothesis \(H_A \colon \theta = \theta_a\).
Proof
See Hogg and Tanis, pages 400-401 (8th edition pages 513-14).
Well, okay, so perhaps the proof isn't all that particularly enlightening, but perhaps if we take a look at a simple example, we'll become more enlightened. Suppose X is a single observation (that's one data point!) from a normal population with unknown mean \(\mu\) and known standard deviation \(\sigma = 1/3\). Then, we can apply the Nehman Pearson Lemma when testing the simple null hypothesis \(H_0 \colon \mu = 3\) against the simple alternative hypothesis \(H_A \colon \mu = 4\). The lemma tells us that, in order to be the most powerful test, the ratio of the likelihoods:
\(\dfrac{L(\mu_0)}{L(\mu_\alpha)} = \dfrac{L(3)}{L(4)} \)
should be small for sample points X inside the critical region C ("less than or equal to some constant k") and large for sample points X outside of the critical region ("greater than or equal to some constant k"). In this case, because we are dealing with just one observation X, the ratio of the likelihoods equals the ratio of the normal probability curves:
\( \dfrac{L(3)}{L(4)}= \dfrac{f(x; 3, 1/9)}{f(x; 4, 1/9)} \)
Then, the following drawing summarizes the situation:
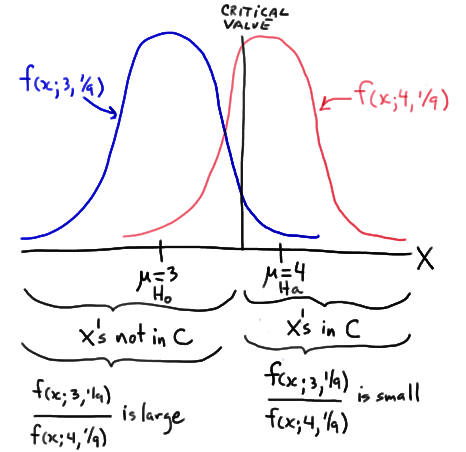
In short, it makes intuitive sense that we would want to reject \(H_0 \colon \mu = 3\) in favor of \(H_A \colon \mu = 4\) if our observed x is large, that is, if our observed x falls in the critical region C. Well, as the drawing illustrates, it is those large X values in C for which the ratio of the likelihoods is small; and, it is for the small X values not in C for which the ratio of the likelihoods is large. Just as the Neyman Pearson Lemma suggests!
Well, okay, that's the intuition behind the Neyman Pearson Lemma. Now, let's take a look at a few examples of the lemma in action.
Example 26-4
Suppose X is a single observation (again, one data point!) from a population with probabilitiy density function given by:
\(f(x) = \theta x^{\theta -1}\)
for 0 < x < 1. Find the test with the best critical region, that is, find the most powerful test, with significance level \(\alpha = 0.05\), for testing the simple null hypothesis \(H_{0} \colon \theta = 3 \) against the simple alternative hypothesis \(H_{A} \colon \theta = 2 \).
Answer
Because both the null and alternative hypotheses are simple hypotheses, we can apply the Neyman Pearson Lemma in an attempt to find the most powerful test. The lemma tells us that the ratio of the likelihoods under the null and alternative must be less than some constant k. Again, because we are dealing with just one observation X, the ratio of the likelihoods equals the ratio of the probability density functions, giving us:
\( \dfrac{L(\theta_0)}{L(\theta_\alpha)}= \dfrac{3x^{3-1}}{2x^{2-1}}= \dfrac{3}{2}x \le k \)
That is, the lemma tells us that the form of the rejection region for the most powerful test is:
\( \dfrac{3}{2}x \le k \)
or alternatively, since (2/3)k is just a new constant \(k^*\), the rejection region for the most powerful test is of the form:
\(x < \dfrac{2}{3}k = k^* \)
Now, it's just a matter of finding \(k^*\), and our work is done. We want \(\alpha\) = P(Type I Error) = P(rejecting the null hypothesis when the null hypothesis is true) to equal 0.05. In order for that to happen, the following must hold:
\(\alpha = P( X < k^* \text{ when } \theta = 3) = \int_{0}^{k^*} 3x^2dx = 0.05 \)
Doing the integration, we get:
\( \left[ x^3\right]^{x=k^*}_{x=0} = (k^*)^3 =0.05 \)
And, solving for \(k^*\), we get:
\(k^* =(0.05)^{1/3} = 0.368 \)
That is, the Neyman Pearson Lemma tells us that the rejection region of the most powerful test for testing \(H_{0} \colon \theta = 3 \) against \(H_{A} \colon \theta = 2 \), under the assumed probability distribution, is:
\(x < 0.368 \)
That is, among all of the possible tests for testing \(H_{0} \colon \theta = 3 \) against \(H_{A} \colon \theta = 2 \), based on a single observation X and with a significance level of 0.05, this test has the largest possible value for the power under the alternative hypohthesis, that is, when \(\theta = 2\).
Example 26-5

Suppose \(X_1 , X_2 , \dots , X_n\) is a random sample from a normal population with mean \(\mu\) and variance 16. Find the test with the best critical region, that is, find the most powerful test, with a sample size of \(n = 16\) and a significance level \(\alpha = 0.05\) to test the simple null hypothesis \(H_{0} \colon \mu = 10 \) against the simple alternative hypothesis \(H_{A} \colon \mu = 15 \).
Answer
Because the variance is specified, both the null and alternative hypotheses are simple hypotheses. Therefore, we can apply the Neyman Pearson Lemma in an attempt to find the most powerful test. The lemma tells us that the ratio of the likelihoods under the null and alternative must be less than some constant k:
\( \dfrac{L(10)}{L(15)}= \dfrac{(32\pi)^{-16/2} exp \left[ -(1/32)\sum_{i=1}^{16}(x_i -10)^2 \right]}{(32\pi)^{-16/2} exp \left[ -(1/32)\sum_{i=1}^{16}(x_i -15)^2 \right]} \le k \)
Simplifying, we get:
\(exp \left[ - \left( \dfrac{1}{32} \right) \left( \sum_{i=1}^{16}(x_i -10)^2 - \sum_{i=1}^{16}(x_i -15)^2 \right) \right] \le k \)
And, simplifying yet more, we get:
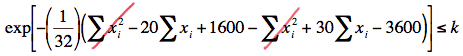
Now, taking the natural logarithm of both sides of the inequality, collecting like terms, and multiplying through by 32, we get:
\(-10\Sigma x_i +2000 \le 32ln(k)\)
And, moving the constant term on the left-side of the inequality to the right-side, and dividing through by −160, we get:
\(\dfrac{1}{16}\Sigma x_i \ge -\frac{1}{160}(32ln(k)-2000) \)
That is, the Neyman Pearson Lemma tells us that the rejection region for the most powerful test for testing \(H_{0} \colon \mu = 10 \) against \(H_{A} \colon \mu = 15 \), under the normal probability model, is of the form:
\(\bar{x} \ge k^* \)
where \(k^*\) is selected so that the size of the critical region is \(\alpha = 0.05\). That's simple enough, as it just involves a normal probabilty calculation! Under the null hypothesis, the sample mean is normally distributed with mean 10 and standard deviation 4/4 = 1. Therefore, the critical value \(k^*\) is deemed to be 11.645:
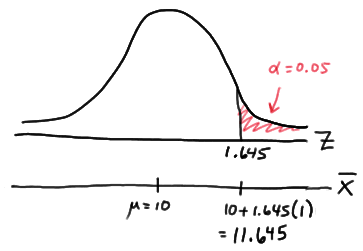
That is, the Neyman Pearson Lemma tells us that the rejection region for the most powerful test for testing \(H_{0} \colon \mu = 10 \) against \(H_{A} \colon \mu = 15 \), under the normal probability model, is:
\(\bar{x} \ge 11.645 \)
The power of such a test when \(\mu = 15\) is:
\( P(\bar{X} > 11.645 \text{ when } \mu = 15) = P \left( Z > \dfrac{11.645-15}{\sqrt{16} / \sqrt{16} } \right) = P(Z > -3.36) = 0.9996 \)
The power can't get much better than that, and the Neyman Pearson Lemma tells us that we shouldn't expect it to get better! That is, the Lemma tells us that there is no other test out there that will give us greater power for testing \(H_{0} \colon \mu = 10 \) against \(H_{A} \colon \mu = 15 \).
26.2 - Uniformly Most Powerful Tests
26.2 - Uniformly Most Powerful TestsThe Neyman Pearson Lemma is all well and good for deriving the best hypothesis tests for testing a simple null hypothesis against a simple alternative hypothesis, but the reality is that we typically are interested in testing a simple null hypothesis, such as \(H_0 \colon \mu = 10\) against a composite alternative hypothesis, such as \(H_A \colon \mu > 10\). The good news is that we can extend the Neyman Pearson Lemma to account for composite alternative hypotheses, providing we take into account each simple alternative specified in H_A. Doing so creates what is called a uniformly most powerful (or UMP) test.
- Uniformly Most Powerful (UMP) test
-
A test defined by a critical region C of size \(\alpha\) is a uniformly most powerful (UMP) test if it is a most powerful test against each simple alternative in the alternative hypothesis \(H_A\). The critical region C is called a uniformly most powerful critical region of size \(\alpha\).
Let's demonstrate by returning to the normal example from the previous page, but this time specifying a composite alternative hypothesis.
Example 26-6

Suppose \(X_1, X_2, \colon, X_n\) is a random sample from a normal population with mean \(\mu\) and variance 16. Find the test with the best critical region, that is, find the uniformly most powerful test, with a sample size of \(n = 16\) and a significance level \(\alpha\) = 0.05 to test the simple null hypothesis \(H_0: \mu = 10\) against the composite alternative hypothesis \(H_A: \mu > 10\).
Answer
For each simple alternative in \(H_A , \mu = \mu_a\), say, the ratio of the likelihood functions is:
\( \dfrac{L(10)}{L(\mu_\alpha)}= \dfrac{(32\pi)^{-16/2} exp \left[ -(1/32)\sum_{i=1}^{16}(x_i -10)^2 \right]}{(32\pi)^{-16/2} exp \left[ -(1/32)\sum_{i=1}^{16}(x_i -\mu_\alpha)^2 \right]} \le k \)
Simplifying, we get:
\(exp \left[ - \left(\dfrac{1}{32} \right) \left(\sum_{i=1}^{16}(x_i -10)^2 - \sum_{i=1}^{16}(x_i -\mu_\alpha)^2 \right) \right] \le k \)
And, simplifying yet more, we get:
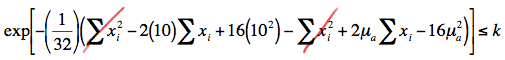
Taking the natural logarithm of both sides of the inequality, collecting like terms, and multiplying through by 32, we get:
\( -2(\mu_\alpha - 10) \sum x_i +16 (\mu_{\alpha}^{2} - 10^2) \le 32 ln(k) \)
Moving the constant term on the left-side of the inequality to the right-side, and dividing through by \(-16(2(\mu_\alpha - 10)) \), we get:
\( \dfrac{1}{16} \sum x_i \ge - \dfrac{1}{16(2(\mu_\alpha - 10))}(32 ln(k) - 16(\mu_{\alpha}^{2} - 10^2)) = k^* \)
In summary, we have shown that the ratio of the likelihoods is small, that is:
\(\dfrac{L(10)}{L(\mu_\alpha)} \le k \)
if and only if:
\( \bar{x} \ge k^*\)
Therefore, the best critical region of size \(\alpha\) for testing \(H_0: \mu = 10\) against each simple alternative \(H_A \colon \mu = \mu_a\), where \(\mu_a > 10\), is given by:
\( C= \left\{ (x_1, x_1, ... , x_n): \bar{x} \ge k^* \right\} \)
where \(k^*\) is selected such that the probability of committing a Type I error is \(\alpha\), that is:
\( \alpha = P(\bar{X} \ge k^*) \text{ when } \mu = 10 \)
Because the critical region C defines a test that is most powerful against each simple alternative \(\mu_a > 10\), this is a uniformly most powerful test, and C is a uniformly most powerful critical region of size \(\alpha\).