Lesson 27: Likelihood Ratio Tests
Lesson 27: Likelihood Ratio TestsIn this lesson, we'll learn how to apply a method for developing a hypothesis test for situations in which both the null and alternative hypotheses are composite. That's not completely accurate. The method, called the likelihood ratio test, can be used even when the hypotheses are simple, but it is most commonly used when the alternative hypothesis is composite. Throughout the lesson, we'll continue to assume that we know the the functional form of the probability density (or mass) function, but we don't know the value of one (or more) of its parameters. That is, we might know that the data come from a normal distrbution, but we don't know the mean or variance of the distribution, and hence the interest in performing a hypothesis test about the unknown parameter(s).
27.1 - A Definition and Simple Example
27.1 - A Definition and Simple ExampleThe title of this page is a little risky, as there are few simple examples when it comes to likelihood ratio testing! But, we'll work to make the example as simple as possible, namely by assuming again, unrealistically, that we know the population variance, but not the population mean. Before we state the definition of a likelihood ratio test, and then investigate our simple, but unrealistic, example, we first need to define some notation that we'll use throughout the lesson.
We'll assume that the probability density (or mass) function of X is \(f(x;\theta)\) where \(\theta\) represents one or more unknown parameters. Then:
- Let \(\Omega\) (greek letter "omega") denote the total possible parameter space of \(\theta\), that is, the set of all possible values of \(\theta\) as specified in totality in the null and alternative hypotheses.
- Let \(H_0 : \theta \in \omega\) denote the null hypothesis where \(\omega\) (greek letter "omega") is a subset of the parameter space \(\Omega\).
- Let \(H_A : \theta \in \omega'\) denote the alternative hypothesis where \(\omega '\) is the complement of \(\omega\) with respect to the parameter space \(\Omega\).
Let's make sure we are clear about that phrase "where \(\omega '\) is the complement of \(\omega\) with respect to the parameter space \(\Omega\)."
Example 27-1
If the total parameter space of the mean \(\mu\) is \(\Omega = {\mu: −∞ < \mu < ∞}\) and the null hypothesis is specified as \(H_0: \mu = 3\), how should we specify the alternative hypothesis so that the alternative parameter space is the complement of the null parameter space?
Answer
If the null parameter space is \(\Omega = {\mu: \mu = 3}\), then the alternative parameter space is everything that is in \(\Omega = {\mu: −∞ < \mu < ∞}\) that is not in \(\Omega\). That is, the alternative parameter space is \(\Omega ' = {\mu: \mu ≠ 3}\). And, so the alternative hypothesis is:
\(H_A : \mu \ne 3\)
In this case, we'd be interested in deriving a two-tailed test.
Example 27-2
If the alternative hypothesis is \(H_A: \mu > 3\), how should we (technically) specify the null hypothesis so that the null parameter space is the complement of the alternative parameter space?
Answer
If the alternative parameter space is (\omega ' = {\mu: \mu > 3}\), then the null parameter space is \(\omega = {\mu: \mu ≤ 3}\). And, so the null hypothesis is:
\(H_0 : \mu \le 3\)
Now, the reality is that some authors do specify the null hypothesis as such, even when they mean \(H_0: \mu = 3\). Ours don't, and so we won't. (That's why I put that "technically" in parentheses up above.) At any rate, in this case, we'd be interested in deriving a one-tailed test.
Definition. Let:
-
\(L(\hat{\omega})\) denote the maximum of the likelihood function with respect to \(\theta\) when \(\theta\) is in the null parameter space \(\omega\).
-
\(L(\hat{\Omega})\) denote the maximum of the likelihood function with respect to \(\theta\) when \(\theta\) is in the entire parameter space \(\Omega\).
Then, the likelihood ratio is the quotient:
\(\lambda = \dfrac{L(\hat{\omega})}{L(\hat{\Omega})}\)
And, to test the null hypothesis \(H_0 : \theta \in \omega\) against the alternative hypothesis \(H_A : \theta \in \omega'\), the critical region for the likelihood ratio test is the set of sample points for which:
\(\lambda = \dfrac{L(\hat{\omega})}{L(\hat{\Omega})} \le k\)
where \(0 < k < 1\), and k is selected so that the test has a desired significance level \(\alpha\).
Example 27-3

A food processing company packages honey in small glass jars. Each jar is supposed to contain 10 fluid ounces of the sweet and gooey good stuff. Previous experience suggests that the volume X, the volume in fluid ounces of a randomly selected jar of the company's honey is normally distributed with a known variance of 2. Derive the likelihood ratio test for testing, at a significance level of \(\alpha = 0.05\), the null hypothesis \(H_0: \mu = 10\) against the alternative hypothesis H_A: \mu ≠ 10\).
Answer
Because we are interested in testing the null hypothesis \(H_0: \mu = 10\) against the alternative hypothesis \(H_A: \mu ≠ 10\) for a normal mean, our total parameter space is:
\(\Omega =\left \{\mu : -\infty < \mu < \infty \right \}\)
and our null parameter space is:
\(\omega = \left \{10\right \}\)
Now, to find the likelihood ratio, as defined above, we first need to find \(L(\hat{\omega})\). Well, when the null hypothesis \(H_0: \mu = 10\) is true, the mean \(\mu\) can take on only one value, namely, \(\mu = 10\). Therefore:
\(L(\hat{\omega}) = L(10)\)
We also need to find \(L(\hat{\Omega})\) in order to define the likelihood ratio. To find it, we must find the value of \(\mu\) that maximizes \(L(\mu)\). Well, we did that back when we studied maximum likelihood as a method of estimation. We showed that \(\hat{\mu} = \bar{x}\) is the maximum likelihood estimate of \(\mu\). Therefore:
\(L(\hat{\Omega}) = L(\bar{x})\)
Now, putting it all together to form the likelihood ratio, we get:
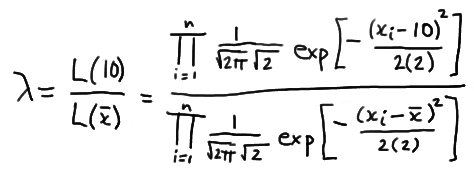
which simplifies to:
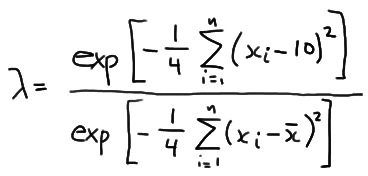
Now, let's step aside for a minute and focus just on the summation in the numerator. If we "add 0" in a special way to the quantity in parentheses:
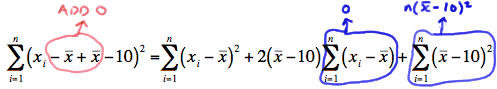
we can show that the summation can be written as:
\(\sum_{i=1}^{n}(x_i - 10)^2 = \sum_{i=1}^{n}(x_i - \bar{x})^2 + n(\bar{x} -10)^2 \)
Therefore, the likelihood ratio becomes:
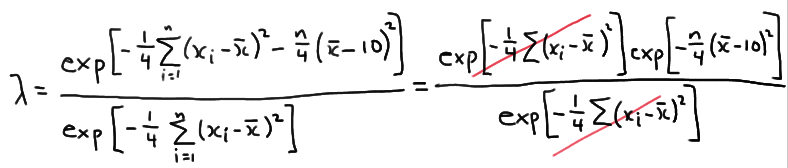
which greatly simplifies to:
\(\lambda = exp \left [-\dfrac{n}{4}(\bar{x}-10)^2 \right ]\)
Now, the likelihood ratio test tells us to reject the null hypothesis when the likelihood ratio \(\lambda\) is small, that is, when:
\(\lambda = exp\left[-\dfrac{n}{4}(\bar{x}-10)^2 \right] \le k\)
where k is chosen to ensure that, in this case, \(\alpha = 0.05\). Well, by taking the natural log of both sides of the inequality, we can show that \(\lambda ≤ k\) is equivalent to:
\( -\dfrac{n}{4}(\bar{x}-10)^2 \le \text{ln} k \)
which, by multiplying through by −4/n, is equivalent to:
\((\bar{x}-10)^2 \ge -\dfrac{4}{n} \text{ln} k \)
which is equivalent to:
\(\dfrac{|\bar{X}-10|}{\sigma / \sqrt{n}} \ge \dfrac{\sqrt{-(4/n)\text{ln} k}}{\sigma / \sqrt{n}} =k* \)
Aha! We should recognize that quantity on the left-side of the inequality! We know that:
\(Z = \dfrac{\bar{X}-10}{\sigma / \sqrt{n}} \)
follows a standard normal distribution when \(H_0: \mu = 10\). Therefore we can determine the appropriate \(k^*\) by using the standard normal table. We have shown that the likelihood ratio test tells us to reject the null hypothesis \(H_0: \mu = 10\) in favor of the alternative hypothesis \(H_A: \mu ≠ 10\) for all sample means for which the following holds:
\(\dfrac{|\bar{X}-10|}{ \sqrt{2} / \sqrt{n}} \ge z_{0.025} = 1.96 \)
Doing so will ensure that our probability of committing a Type I error is set to \(\alpha = 0.05\), as desired.
27.2 - The T-Test For One Mean
27.2 - The T-Test For One MeanWell, geez, now why would we be revisiting the t-test for a mean \(\mu\) when we have already studied it back in the hypothesis testing section? Well, the answer, it turns out, is that, as we'll soon see, the t-test for a mean \(\mu\) is the likelihood ratio test! Let's take a look!
Example 27-4

Suppose that a random sample \(X_1 , X_2 , \dots , X_n\) arises from a normal population with unknown mean \(\mu\) and unknown variance \(\sigma^2\). (Yes, back to the realistic situation, in which we don't know the population variance either.) Find the size \(\alpha\) likelihood ratio test for testing the null hypothesis \(H_0: \mu = \mu_0\) against the two-sided alternative hypothesis \(H_A: \mu ≠ \mu_0\).
Answer
Our unrestricted parameter space is:
\( \Omega = \left\{ (\mu, \sigma^2) : -\infty < \mu < \infty, 0 < \sigma^2 < \infty \right\} \)
Under the null hypothesis, the mean \(\mu\) is the only parameter that is restricted. Therefore, our parameter space under the null hypothesis is:
\( \omega = \left\{(\mu, \sigma^2) : \mu =\mu_0, 0 < \sigma^2 < \infty \right\}\)
Now, first consider the case where the mean and variance are unrestricted. We showed back when we studied maximum likelihood estimation that the maximum likelihood estimates of \(\mu\) and \(\sigma^2\) are, respectively:
\(\hat{\mu} = \bar{x} \text{ and } \hat{\sigma}^2 = \dfrac{1}{n}\sum_{i=1}^{n}(x_i - \bar{x})^2 \)
Therefore, the maximum of the likelihood function for the unrestricted parameter space is:
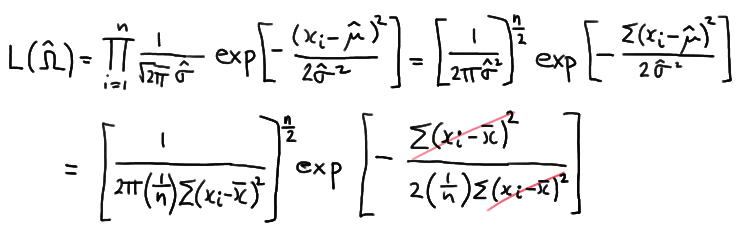
which simplifies to:
\( L(\hat{\Omega})= \left[\dfrac{ne^{-1}}{2\pi \Sigma (x_i - \bar{x})^2} \right]^{n/2} \)
Now, under the null parameter space, the maximum likelihood estimates of \(\mu\) and \(\sigma^2\) are, respectively:
\( \hat{\mu} = \mu_0 \text{ and } \hat{\sigma}^2 = \dfrac{1}{n}\sum_{i=1}^{n}(x_i - \mu_0)^2 \)
Therefore, the likelihood under the null hypothesis is:
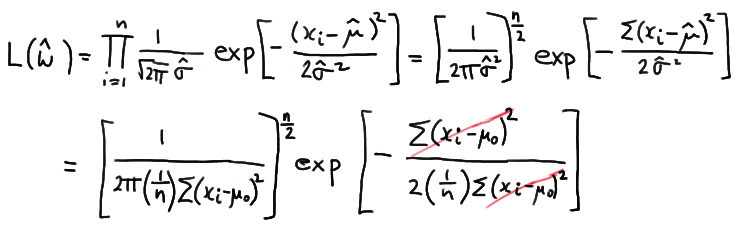
which simplifies to:
\( L(\hat{\omega})= \left[\dfrac{ne^{-1}}{2\pi \Sigma (x_i - \mu_0)^2} \right]^{n/2} \)
And now taking the ratio of the two likelihoods, we get:
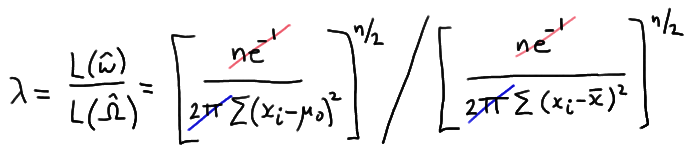
which reduces to:
\( \lambda = \left[ \dfrac{\sum_{i=1}^{n}(x_i - \bar{x})^2}{\sum_{i=1}^{n}(x_i - \mu_0)^2} \right] ^{n/2}\)
Focusing only on the denominator for a minute, let's do that trick again of "adding 0" in just the right away. Adding 0 to the quantity in the parentheses, we get:
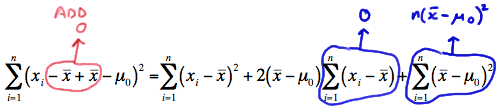
which simplifies to:
\( \sum_{i=1}^{n}(x_i - \mu_0)^2 = \sum_{i=1}^{n}(x_i - \bar{x})^2 +n(\bar{x} - \mu_0)^2 \)
Then, our likelihood ratio \(\lambda\) becomes:
\( \lambda = \left[ \dfrac{\sum_{i=1}^{n}(x_i - \bar{x})^2}{\sum_{i=1}^{n}(x_i - \mu_0)^2} \right] ^{n/2} = \left[ \dfrac{\sum_{i=1}^{n}(x_i - \bar{x})^2}{ \sum_{i=1}^{n}(x_i - \bar{x})^2 +n(\bar{x} - \mu_0)^2} \right] ^{n/2} \)
which, upon dividing through numerator and denominator by \( \sum_{i=1}^{n}(x_i - \bar{x})^2 \) simplifies to:
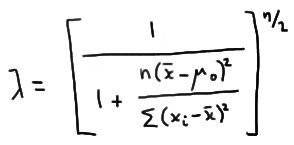
Therefore, the likelihood ratio test's critical region, which is given by the inequality \(\lambda ≤ k\), is equivalent to:
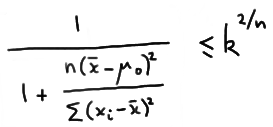
which with some minor algebraic manipulation can be shown to be equivalent to:
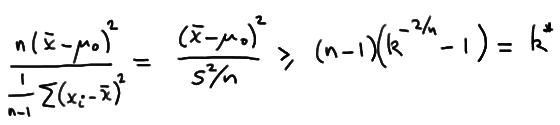
So, in a nutshell, we've shown that the likelihood ratio test tells us that for this situation we should reject the null hypothesis \(H_0: \mu= \mu_0\) in favor of the alternative hypothesis \(H_A: \mu ≠ \mu_0\) if:
\( \dfrac{(\bar{x}-\mu_0)^2 }{s^2 / n} \ge k^{*} \)
Well, okay, so I started out this page claiming that the t-test for a mean \(\mu\) is the likelihood ratio test. Is it? Well, the above critical region is equivalent to rejecting the null hypothesis if:
\( \dfrac{|\bar{x}-\mu_0| }{s / \sqrt{n}} \ge k^{**} \)
Does that look familiar? We previously learned that if \(X_1, X_2, \dots, X_n\) are normally distributed with mean \(\mu\) and variance \(\sigma^2\), then:
\( T = \dfrac{\bar{X}-\mu}{S / \sqrt{n}} \)
follows a T distribution with n − 1 degrees of freedom. So, this tells us that we should use the T distribution to choose \(k^{**}\). That is, set:
\(k^{**} = t_{\alpha /2, n-1}\)
and we have our size \(\alpha\) t-test that ensures the probability of committing a Type I error is \(\alpha\).
It turns out... we didn't know it at the time... but every hypothesis test that we derived in the hypothesis testing section is a likelihood ratio test. Back then, we derived each test using distributional results of the relevant statistic(s), but we could have alternatively, and perhaps just as easily, derived the tests using the likelihood ratio testing method.