Section 4: Bayesian Methods
Section 4: Bayesian Methods
All of the methods we have developed and used thus far in this course have been developed using what statisticians would call a "frequentist" approach. In this section, we revisit some of those methods using what statisticians would call a "Bayesian" approach. Specifically, we will:
- learn how a Bayesian would assign probabilities to certain events
- learn how a Bayesian would tackle the estimation of a parameter
- learn how a Bayesian would update the prior information she/he has about the value of a parameter
In case you are wondering, the picture to the right is that of the Reverend Thomas Bayes, after which the field of Bayesian statistics is aptly named.
Lesson 23: Probability, Estimation, and Concepts
Lesson 23: Probability, Estimation, and ConceptsWe'd need at least an entire semester, and perhaps more, to truly do any justice to the study of Bayesian statistics. The best we can do in this course is to dabble a bit and in doing so take just a tiny peak at the world through the eyes of a Bayesian. First, we'll take a look at an example that illustrates how a Bayesian might assign a (subjective) probability to an event given the information he or she has available. Then, we'll investigate how a Bayesian might estimate a parameter. Finally, we'll explore how a Bayesian might update the prior information he or she has about the value of a parameter.
23.1 - Subjective Probability
23.1 - Subjective ProbabilityExample 23-1
Here's an example that illustrates how a Bayesian might use available data to assign probabilities to particular events.
The following amounts, in dollars, are bet on horses A, B, C, and D to win a local race:
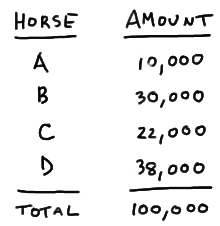
Determine the payout for winning with a \$2 bet on each of the four horses, if the track wants to take 17%, or \$17,000, from the amount collected.
Answer
The first thing we need to do is to determine the likelihood, that is, probability, that each of the horses wins. We could assign the probabilities based on our own "gut feeling." Geez.... I think horse A is gonna win today. In general, that's probably not a good idea. We'd probably be much better served if we used the information we have available, namely the "gut feeling" of all of the bettors! That is, if \$38,000 worth of bets came in for Horse D and only \$10,000 came in for Horse A, that tells us that more people think that Horse D is going to win than Horse A. It would behoove us, therefore, to use the amounts bet to assign the probabilities. That said, the probability that Horse A will win is then:
\(P(A) = \dfrac{10,000}{100,000}=0.10\)
And, the probability that Horse B will win is:
\(P(B) = \dfrac{30,000}{100,000}=0.30\)
And, the probability that Horse C will win is:
\(P(C) = \dfrac{22,000}{100,000}=0.22\)
And, the probability that Horse D will win is:
\(P(D) = \dfrac{38,000}{100,000}=0.38\)
Now having assigned a probability to the event that Horse A wins, we can determine the odds against horse A winning. It is:
\(\text{Odds against } A = \dfrac{1-0.10}{0.10}= 9 \text{ to } 1 \)
The odds against A tells us that the track will payout \$9 on a \$1 bet. Now, the odds against Horse B winning is:
\(\text{Odds against } B = \dfrac{1-0.30}{0.30}= \dfrac{7}{3} \text{ to } 1 \)
The odds against B tells us that the track will payout \(\frac{\$7}{3}=\$2.33\) on a \$1 bet. Now, the odds against Horse C winning is:
\(\text{Odds against } C = \dfrac{1-0.22}{0.22}= \dfrac{39}{11} \text{ to } 1 \)
The odds against C tells us that the track will payout \(\dfrac{\$39}{11}=\$3.55\) on a \$1 bet. Finally, the odds against Horse D winning is:
\(\text{Odds against } D = \dfrac{1-0.38}{0.38}= \dfrac{31}{19} \text{ to } 1 \)
The odds against D tells us that the track will payout \(\dfrac{\$31}{19}=\$1.63\) on a \$1 bet. Now, using the odds against Horse A winning, we can determine that the amount the track pays out on a \$2 bet on Horse A is:
\(\text{Payout for } A = $2 + 9($2) = $20 \)
That is, the bettor gets \$9 for each \$1 bet, that is, \$18, plus the \$2 he or she originally bet. Now, using the odds against Horse B winning, we can determine that the amount the track pays out on a \$2 bet on Horse B is:
\(\text{Payout for } B = $2 + \dfrac{7}{3}($2) = $6.67 \)
And, using the odds against Horse C winning, we can determine that the amount the track pays out on a \$2 bet on Horse C is:
\(\text{Payout for } C = $2 + \dfrac{39}{11}($2) = $9.09 \)
And, using the odds against Horse D winning, we can determine that the amount the track pays out on a \$2 bet on Horse D is:
\(\text{Payout for } D = $2 + \dfrac{31}{19}($2) = $5.26 \)
We're almost there. We just need to skim the 17% off for the race track to make sure that it makes some money off of the bettors. Multiplying each of the calculated payouts by 0.83, we get:
\(\text{Absolute payout for } A = $20.00(0.83) = $16.60 \)
\(\text{Absolute payout for } B = $6.67(0.83) = $5.54 \)
\(\text{Absolute payout for } C = $9.09(0.83) = $7.54 \)
\(\text{Absolute payout for } D = $5.26(0.83) = $4.37 \)
We can always check our work, too. Suppose, for example, that Horse A wins. Then the track would payout \$16.60 to the 5000 bettors who bet \$2 on Horse A, costing the track \$16.60(5000) = \$83,000. Given that that track brought in \$100,000 in bets, the track would indeed make its desired \$17,000. A similar check of our work can be made for Horses B, C, and D, although there may be some round-off errors because we did do some rounding in our payout calculations. Should still be very close to \$83,000 in each case though!
23.2 - Bayesian Estimation
23.2 - Bayesian EstimationThere's one key difference between frequentist statisticians and Bayesian statisticians that we first need to acknowledge before we can even begin to talk about how a Bayesian might estimate a population parameter \(\theta\). The difference has to do with whether a statistician thinks of a parameter as some unknown constant or as a random variable. Let's take a look at a simple example in an attempt to emphasize the difference.
Example 23-2

A traffic control engineer believes that the cars passing through a particular intersection arrive at a mean rate \(\lambda\) equal to either 3 or 5 for a given time interval. Prior to collecting any data, the engineer believes that it is much more likely that the rate \(\lambda=3\) than \(\lambda=5\). In fact, the engineer believes that the prior probabilities are:
\(P(\lambda = 3) = 0.7\) and \(P(\lambda = 5) = 0.3\)
One day, during a a randomly selected time interval, the engineer observes \(x=7\) cars pass through the intersection. In light of the engineer's observation, what is the probability that \(\lambda=3\)? And what is the probability that \(\lambda=5\)?
Answer
The first thing you should notice in this example is that we are talking about finding the probability that a parameter \(\lambda\) takes on a particular value. In one fell swoop, we've just turned everything that we've learned in Stat 414 and Stat 415 on its head! The next thing you should notice, after recovering from the dizziness of your headstand, is that we already have the tools necessary to calculate the desired probabilities. Just stick your hand in your probability tool box, and pull out Bayes' Theorem.
Now, simply by using the definition of conditional probability, we know that the probability that \(\lambda=3\) given that \(X=7\) is:
\(P(\lambda=3 | X=7) = \dfrac{P(\lambda=3, X=7)}{P(X=7)} \)
which can be written using Bayes' Theorem as:
\(P(\lambda=3 | X=7) = \dfrac{P(\lambda=3)P(X=7| \lambda=3)}{P(\lambda=3)P(X=7| \lambda=3)+P(\lambda=5)P(X=7| \lambda=5)} \)
We can use the Poisson cumulative probability table in the back of our text book to find \(P(X=7|\lambda=3)\) and \(P(X=7|\lambda=5)\). They are:
\( P(X=7|\lambda=3)=0.988-0.966=0.022 \) and \( P(X=7|\lambda=5)=0.867-0.762=0.105 \)
Now, we have everything we need to finalize our calculation of the desired probability:
\( P(\lambda=3 | X=7)=\dfrac{(0.7)(0.022)}{(0.7)(0.022)+(0.3)(0.105)}=\dfrac{0.0154}{0.0154+0.0315}=0.328 \)
Hmmm. Let's summarize. The initial probability, in this case, \(P(\lambda=3)=0.7\), is called the prior probability. That's because it is the probability that the parameter takes on a particular value prior to taking into account any new information. The newly calculated probability, that is:
\(P(\lambda=3|X=7)\)
is called the posterior probability. That's because it is the probability that the parameter takes on a particular value posterior to, that is, after, taking into account the new information. In this case, we have seen that the probability that \(\lambda=3\) has decreased from 0.7 (the prior probability) to 0.328 (the posterior probability) with the information obtained from the observation \(x=7\).
A similar calculation can be made in finding \(P(\lambda=5|X=7)\). In doing so, we see:
\( P(\lambda=5 | X=7)=\dfrac{(0.3)(0.105)}{(0.7)(0.022)+(0.3)(0.105)}=\dfrac{0.0315}{0.0154+0.0315}=0.672 \)
In this case, we see that the probability that \(\lambda=5\) has increased from 0.3 (the prior probability) to 0.672 (the posterior probability) with the information obtained from the observation \(x=7\).
That last example is good for illustrating the distinction between prior probabilities and posterior probabilities, but it falls a bit short as a practical example in the real world. That's because the parameter in the example is assumed to take on only two possible values, namely \(\lambda=3\) or \(\lambda=5\). In the case where the parameter space for a parameter \(\theta\) takes on an infinite number of possible values, a Bayesian must specify a prior probability density function \(h(\theta)\), say. Entire courses have been devoted to the topic of choosing a good prior p.d.f., so naturally, we won't go there! We'll instead assume we are given a good prior p.d.f. \(h(\theta)\) and focus our attention instead on how to find a posterior probability density function \(k(\theta|y)\), say, if we know the probability density function \(g(y|\theta)\) of the statistic \(Y\).
Well, if we know \(h(\theta)\) and \(g(y|\theta)\), we can treat:
\( k(y,\theta)=g(y|\theta)h(\theta)\)
as the joint p.d.f. of the statistic \(Y\) and the parameter \(\theta\). Then, we can find the marginal distribution of \(Y\) from the joint distribution \(k(y, \theta)\) by integrating over the parameter space of \(\theta\):
\(k_1(y)=\int_{-\infty}^{\infty}k(y,\theta)d\theta=\int_{-\infty}^{\infty}g(y|\theta)h(\theta)d\theta \)
And then, we can find the posterior p.d.f. of \(\theta\), given that \(Y=y\), by using Bayes' theorem. That is:
\(k(\theta|y)=\dfrac{k(y, \theta)}{k_1(y)}=\dfrac{g(y|\theta)h(\theta)}{k_1(y)}\)
Let's make this discussion more concrete by taking a look at an example.
Example 23-3

Suppose that \(Y\) follows a binomial distribution with parameters \(n\) and \(p=\theta\), so that the p.m.f. of \(Y\) given \(\theta\) is:
\(g(y|\theta) = \binom{n}{y}\theta^y(1-\theta)^{n-y} \)
for \(y=0, 1, \ldots, n\). Suppose that the prior p.d.f. of the parameter \(\theta\) is the beta p.d.f., that is:
\(h(\theta)=\dfrac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)}\theta^{\alpha-1}(1-\theta)^{\beta-1} \)
for \(0<\theta<1\). Find the posterior p.d.f of \(\theta\), given that \(Y=y\). That is, find \(k(\theta|y)\).
Answer
First, we find the joint p.d.f. of the statistic \(Y\) and the parameter \(\theta\) by multiplying the prior p.d.f. \(h(\theta)\) and the conditional p.m.f. of \(Y\) given \(\theta\). That is:
\(k(y,\theta)=g(y|\theta)h(\theta)=\binom{n}{y}\theta^y(1-\theta)^{n-y}\dfrac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)}\theta^{\alpha-1}(1-\theta)^{\beta-1} \)
over the support \(y=0, 1, 2, \ldots, n\) and \(0<\theta<1\). Simplifying by collecting like terms, we get that the joint p.d.f. of the statistic \(Y\) and the parameter \(\theta\) is:
\(k(y,\theta)=\binom{n}{y}\dfrac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)}\theta^{y+\alpha-1}(1-\theta)^{n-y+\beta-1} \)
over the support \(y=0, 1, 2, \ldots, n\) and \(0<\theta<1\).
Then, we find the marginal p.d.f. of \(Y\) by integrating \(k(y, \theta)\) over the parameter space of \(\theta\):
\(k_1(y)=\int_0^1 k(y, \theta)d\theta={n\choose y}\dfrac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)}\int_0^1 \theta^{y+\alpha-1}(1-\theta)^{n-y+\beta-1}d\theta\)
Now, if we multiply the integrand by 1 in a special way:
\(k_1(y)= {n\choose y}\dfrac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)} \left(\dfrac{\Gamma(y+\alpha)\Gamma(n-y+\beta)}{\Gamma(y+\alpha+n-y+\beta)}\right) \int_0^1\left(\dfrac{\Gamma(y+\alpha+n-y+\beta)}{\Gamma(y+\alpha)\Gamma(n-y+\beta)}\right) \theta^{y + \alpha - 1}(1-\theta)^{n-y+\beta-1}d\theta\)
we see that we get a beta p.d.f. with parameters \(y+\alpha\) and \(n-y+\beta\) that therefore, by the definition of a valid p.d.f., must integrate to 1. Simplifying we therefore get that the marginal p.d.f. of \(Y\) is:
\(k_1(y)={n\choose y}\dfrac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)} \left(\dfrac{\Gamma(y+\alpha)\Gamma(n-y+\beta)}{\Gamma(y+\alpha+n-y+\beta)}\right)\)
on the support \(y=0, 1, 2, \ldots, n\). Then, the posterior p.d.f. of \(\theta\), given that \(Y=y\) is:
\(k(\theta|y)=\dfrac{k(y, \theta)}{k_1(y)}=\dfrac{{n\choose y}\dfrac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)}\theta^{y+\alpha-1}(1-\theta)^{n-y+\beta-1}}{{n\choose y}\dfrac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)} \left(\dfrac{\Gamma(y+\alpha)\Gamma(n-y+\beta)}{\Gamma(y+\alpha+n-y+\beta)}\right)}\)
Because some things cancel out, we see that the posterior p.d.f. of \(\theta\), given that \(Y=y\) is:
\(k(\theta|y)=\dfrac{\Gamma(n+\alpha+\beta)}{\Gamma(\alpha+y)\Gamma(n+\beta-y)}\theta^{y+\alpha-1}(1-\theta)^{n-y+\beta-1}\)
for \(0<\theta<1\), which you might recognize as a beta p.d.f. with parameters \(y+\alpha\) and \(n-y+\beta\).
Okay now, are you scratching your head wondering what this all has to do with Bayesian estimation, as the title of this page suggests it should? Well, let's talk about that then! Bayesians believe that everything you need to know about a parameter \(\theta\) can be found in its posterior p.d.f. \(k(\theta|y)\). So, if a Bayesian is asked to make a point estimate of \(\theta\), he or she is going to naturally turn to \(k(\theta|y)\) for the answer. But how? Well, the logical thing to do would be to use \(k(\theta|y)\) to calculate the mean or median of \(\theta\), as they would all be reasonable guesses of the value of \(\theta\). But, hmmm! Should he or she .... errrr, let's get rid of this he or she stuff.... let's make it a she for now... okay... should she calculate the mean or the median? Well, that depends on what it will cost her for using either. Huh? Cost? We're talking about estimating a parameter not buying groceries. Well, let's suppose she gets charged a certain amount for estimating the real value of the parameter \(\theta\) with her guess \(w(y)\). Well, this Bayesian woman would probably want the cost of her error to be as small as possible. Suppose, she is charged the square of the error between \(\theta\) and her guess \(w(y)\). That is, suppose her cost is:
\((\theta -w(y))^2 \)
Aha... there we have it! Because she wants her cost to be as small as possible, she should make her guess \(w(y)\) be the conditional mean \(E(\theta|y)\). That's because way back in Stat 414, we showed that if \(Z\) is a random variable, then the expected value of the squared error, that is, \(E\left[(Z-b)^2\right]\) is minimized at \(b=E(Z)\). In her case, the \(Z\) is the \(\theta\) and the \(b\) is the \(w(y)=E(\theta|y)\).
On the other hand, if she is charged the absolute value of the error between \(\theta\) and her guess \(w(y)\), that is:
\(|\theta-w(y)|\)
then in order to make her cost be as small as possible, she'll want to make her guess \(w(y)\) be the conditional median. That's because, again, way back in Stat 414, we showed that if \(Z\)is a random variable, then the expected value of the absolute value of the error, that is, \(E(|Z-b|]\) is minimized when \(b\) equals the median of the distribution.
Let's make this discussion concrete by returning to our binomial example.
Example 23-3 (continued)
Suppose that \(Y\) follows a binomial distribution with parameters \(n\) and \(p=\theta\), so that the p.m.f. of \(Y\) given \(\theta\) is:
\(g(y|\theta)={n\choose y}\theta^y(1-\theta)^{n-y}\)
for \(y=0, 1, 2, \ldots, n\). Suppose that the prior p.d.f. of the parameter \(\theta\) is the beta p.d.f., that is:
\(h(\theta)=\dfrac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)}\theta^{\alpha-1}(1-\theta)^{\beta-1} \)
for \(0<\theta<1\). Estimate the parameter \(\theta\) using the squared error loss function.
Answer
We've previously shown that the posterior p.d.f. of \(\theta\) given \(Y=y\) is the beta p.d.f. with with parameters \(y+\alpha\) and \(n-y+\beta\). The previous discussion tells us that in order to minimize the squared error loss function:
\( (\theta -w(y))^2 \)
we should use the conditional mean \(w(y)=E(\theta|y)\) as an estimate of the parameter \(\theta\). Well, in general, the mean of a beta p.d.f with parameters \(\alpha\) and \(\beta\) is:
\( \dfrac{\alpha}{\alpha + \beta} \)
In our case, the posterior p.d.f. of \(\theta\) given \(Y=y\) is the beta p.d.f. with parameters \(y+\alpha\) and \(n-y+\beta\). Therefore, the conditional mean is:
\( w(y)=E(\theta|y)=\dfrac{\alpha+y}{\alpha+y+n-y+\beta}=\dfrac{\alpha+y}{\alpha+n+\beta} \)
And, it serves, in this situation, as a Bayesian's best estimate of \(\theta\) when using the squared error loss function.