22.1 - The Test
22.1 - The TestBefore we can work on developing a hypothesis test for testing whether an empirical distribution function \(F_n (x)\) fits a hypothesized distribution function \(F (x)\) we better have a good idea of just what is an empirical distribution function \(F_n (x)\). Therefore, let's start with formally defining it.
- Empirical distribution function
-
Given an observed random sample \(X_1 , X_2 , \dots , X_n\), an empirical distribution function \(F_n (x)\) is the fraction of sample observations less than or equal to the value x. More specifically, if \(y_1 < y_2 < \dots < y_n\) are the order statistics of the observed random sample, with no two observations being equal, then the empirical distribution function is defined as:
That is, for the case in which no two observations are equal, the empirical distribution function is a "step" function that jumps \(1/n\) in height at each observation \(x_k\). For the cases in which two (or more) observations are equal, that is, when there are \(n_k\) observations at \(x_k\), the empirical distribution function is a "step" function that jumps \(n_k/n\) in height at each observation \(x_k\). In either case, the empirical distribution function \(F_n(x)\) is the fraction of sample values that are equal to or less than x.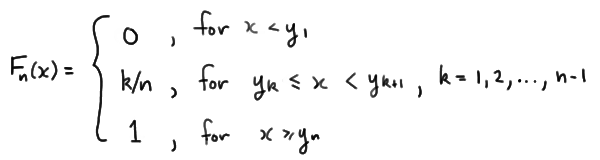
Such a formal definition is all well and good, but it would probably make even more sense if we took at a look at a simple example.
Example 22-1

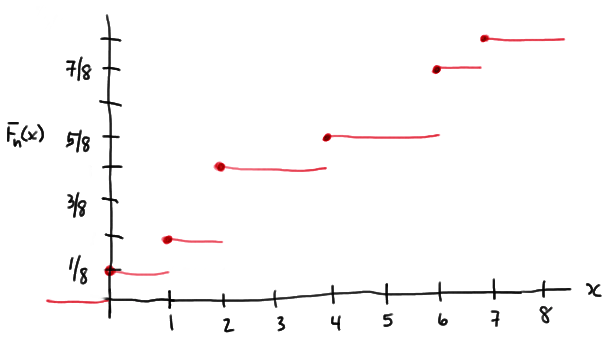
A random sample of n = 8 people yields the following (ordered) counts of the number of times they swam in the past month:
0 1 2 2 4 6 6 7
Calculate the empirical distribution function \(F_n (x)\).
Answer
As reported, the data are ordered, therefore the order statistics are \(y_1 = 0, y_2 = 1, y_3 = 2, y_4 = 2, y_5 = 4, y_6 = 6, y_7 = 6\) and \(y_8 = 7\). Therefore, using the definition of the empirical distribution function, we have:
\(F_n(x)=0 \text{ for } x < 0\)
and:
\(F_n(x)=\frac{1}{8} \text{ for } 0 \le x < 1\) and \(F_n(x)=\frac{2}{8} \text{ for } 1 \le x < 2\)
Now, noting that there are two 2s, we need to jump 2/8 at x = 2:
\(F_n(x)=\frac{2}{8}+\frac{2}{8}=\frac{4}{8} \text{ for } 2 \le x < 4\)
Then:
\(F_n(x)=\frac{5}{8} \text{ for } 4 \le x < 6\)
Again, noting that there are two 6s, we need to jump 2/8 at x = 6:
\(F_n(x)=\frac{5}{8}+\frac{2}{8}=\frac{7}{8} \text{ for } 6 \le x < 7\)
And, finally:
\(F_n(x)=\frac{7}{8}+\frac{1}{8}=\frac{8}{8}=1 \text{ for } x \ge 7\)
Plotting the function, it should look something like this then:
Now, with that behind us, let's jump right in and state and justify (not prove!) the Kolmogorov-Smirnov statistic for testing whether an empirical distribution fits a hypothesized distribution well.
- Kolmogorov-Smirnov test statistic
-
\[D_n=sup_x\left[ |F_n(x)-F_0(x)| \right]\]
is used for testing the null hypothesis that the cumulative distribution function \(F (x)\) equals some hypothesized distribution function \(F_0 (x)\), that is, \(H_0 : F(x)=F_0(x)\), against all of the possible alternative hypotheses \(H_A : F(x) \ne F_0(x)\). That is, \(D_n\) is the least upper bound of all pointwise differences \(|F_n(x)-F_0(x)|\).
The bottom line is that the Kolmogorov-Smirnov statistic makes sense, because as the sample size n approaches infinity, the empirical distribution function \(F_n (x)\) converges, with probability 1 and uniformly in x, to the theoretical distribution function \(F (x)\). Therefore, if there is, at any point x, a large difference between the empirical distribution \(F_n (x)\) and the hypothesized distribution \(F_0 (x)\), it would suggest that the empirical distribution \(F_n (x)\) does not equal the hypothesized distribution \(F_0 (x)\). Therefore, we reject the null hypothesis:
\[H_0 : F(x)=F_0(x)\]
if \(D_n\) is too large.
Now, how do we know that \(F_n (x)\) converges, with probability 1 and uniformly in x, to the theoretical distribution function \(F (x)\)? Well, unfortunately, we don't have the tools in this course to officially prove it, but we can at least do a bit of a hand-waving argument.
Let \(X_1 , X_2 , \dots , X_n\) be a random sample of size n from a continuous distribution \(F (x)\). Then, if we consider a fixed x, then \(W= F_n (x)\) can be thought of as a random variable that takes on possible values \(0, 1/n , 2/n , \dots , 1\). Now:
- nW = 1, if and only if exactly 1 observation is less than or equal to x, and n−1 observations are greater than x
- nW = 2, if and only if exactly 2 observations are less than or equal to x, and n−2 observations are greater than x
- and in general...
- nW = k, if and only if exactly k observations are less than or equal to x, and n−k observations are greater than x
If we treat a success as an observation being less than or equal to x, then the probability of success is:
\(P(X_i ≤ x) = F(x)\)
Do you see where this is going? Well, because \(X_1 , X_2 , \dots , X_n\) are independent random variables, the random variable nW is a binomial random variable with n trials and probability of success p = F(x). Therefore:
\[ P\left(W = \frac{k}{n}\right) = P(nW=k) = \binom{n}{k}[F(x)]^k[1-F(x)]^{n-k}\]
And, the expected value and variance of nW are:
\(E(nW)=np=nF(x)\) and \(Var(nW)=np(1-p)=n[F(x)][1-F(x)]\)
respectively. Therefore, the expected value and variance of W are:
\(E(W)=n\frac{F(x)}{n}=F(x)\) and \(\displaystyle Var(W) =\frac{n[(F(x)][1-F(x)]}{n^2}=\frac{[(F(x)][1-F(x)]}{n}\)
We're very close now. We just now need to recognize that as n approaches infinity, the variance of W, that is, the variance of \(F_n (x)\) approaches 0. That means that as n approaches infinity the empirical distribution \(F_n (x)\) approaches its mean \(F (x)\). And, that's why the argument for rejecting the null hypothesis if there is, at any point x, a large difference between the empirical distribution \(F_n (x)\) and the hypothesized distribution \(F_0 (x)\). Not a mathematically rigorous argument, but an argument nonetheless!
Notice that the Kolmogorov-Smirnov (KS) test statistic is the supremum over all real \(x\)---a very large set of numbers! How then can we possibly hope to compute it? Well, fortunately, we don't have to check it at every real number but only at the sample values, since they are the only points at which the supremum can occur. Here's why:
First the easy case. If \(x\ge y_n\), then \(F_n(x)=1\), and the largest difference between \(F_n(x)\) and \(F_0(x)\) occurs at \(y_n\). Why? Because \(F_0(x)\) can never exceed 1 and will only get closer for larger \(x\) by the monotonicity of distribution functions. So, we can record the value \(F_n(y_n)-F_0(y_n)=1-F_0(y_n)\) and safely know that no other value \(x\ge y_n\) needs to be checked.
The case where \(x<y_1\) is a little trickier. Here, \(F_n(x)=0\), and the largest difference between \(F_n(x)\) and \(F_0(x)\) would occur at the largest possible \(x\) in this range for a reason similar to that above: \(F_0(x)\) can never be negative and only gets farther from 0 for larger \(x\). The trick is that there is no largest \(x\) in this range (since \(x\) is strictly less than \(y_1\) ), and we instead have to consider lefthand limits. Since \(F_0(x)\) is continuous, its limit at \(y_1\) is simply \(F_0(y_1)\). However, the lefthand limit of \(F_n(y_1)\) is 0. So, the value we record is \(F_0(y_1)-0=F_0(y_1)\), and ignore checking any other value \(x<y_1\).
Finally, the general case \(y_{k-1}\le x <y_{k}\) is a combination of the two above. If \(F_0(x)<F_n(x)\), then \(F_0(y_{k-1})\le F_0(x)<F_n(x)=F_n(y_{k-1})\), so that \(F_n(y_{k-1})-F_0(y_{k-1})\) is at least as large as \(F_n(x)-F_0(x)\) (so we don't even have to check those \(x\) values). If, however, \(F_0(x)>F_n(x)\), then the largest difference will occur at the lefthand limits at \(y_{k}\). Again, the continuity of \(F_0\) allows us to use \(F_0(y_{k})\) here, while the lefthand limit of \(F_n(y_{k})\) is actually \(F_n(y_{k-1})\). So, the value to record is \(F_0(y_{k})-F_n(y_{k-1})\), and we may disregard the other \(x\) values.
Whew! That covers all real \(x\) values and leaves us a much smaller set of values to actually check. In fact, if we introduce a value \(y_0\) such that \(F_n(y_0)=0\), then we can summarize all this exposition with the following rule:
- Rule for computing the KS test statistic:
-
For each ordered observation \(y_k\) compute the differences
\(|F_n(y_k)-F_0(y_k)|\) and \(|F_n(y_{k-1})-F_0(y_k)|\).
The largest of these is the KS test statistic.
The easiest way to manage these calculations is with a table, which we now demonstrate with two examples.