Lesson 10: Introduction to ANOVA
Lesson 10: Introduction to ANOVAOverview
In the previous lessons, we learned how to perform inference for a population mean from one sample and also how to compare population means from two samples (independent and paired). In this Lesson, we introduce Analysis of Variance or ANOVA. ANOVA is a statistical method that analyzes variances to determine if the means from more than two populations are the same. In other words, we have a quantitative response variable and a categorical explanatory variable with more than two levels. In ANOVA, the categorical explanatory is typically referred to as the factor.
Objectives
- Describe the logic behind analysis of variance.
- Set up and perform one-way ANOVA.
- Identify the information in the ANOVA table.
- Interpret the results from ANOVA output.
- Perform multiple comparisons and interpret the results, when appropriate.
10.1 - Introduction to Analysis of Variance
10.1 - Introduction to Analysis of VarianceLet's use the following example to look at the logic behind what an analysis of variance is after.
Application: Tar Content Comparisons
We want to see whether the tar contents (in milligrams) for three different brands of cigarettes are different. Two different labs took samples, Lab Precise and Lab Sloppy.
Lab Precise
Lab Precise took six samples from each of the three brands and got the following measurements:
| Sample | Brand A | Brand B | Brand C |
|---|---|---|---|
| 1 | 10.21 | 11.32 | 11.60 |
| 2 | 10.25 | 11.20 | 11.90 |
| 3 | 10.24 | 11.40 | 11.80 |
| 4 | 9.80 | 10.50 | 12.30 |
| 5 | 9.77 | 10.68 | 12.20 |
| 6 | 9.73 | 10.90 | 12.20 |
| Average | \(\bar{y}_1= 10.00\) | \(\bar{y}_2= 11.00\) | \(\bar{y}_3= 12.00\) |
Lab Precise Dotplot

Lab Sloppy
Lab Sloppy also took six samples from each of the three brands and got the following measurements:
| Sample | Brand A | Brand B | Brand C |
|---|---|---|---|
| 1 | 9.03 | 9.56 | 10.45 |
| 2 | 10.26 | 13.40 | 9.64 |
| 3 | 11.60 | 10.68 | 9.59 |
| 4 | 11.40 | 11.32 | 13.40 |
| 5 | 8.01 | 10.68 | 14.50 |
| 6 | 9.70 | 10.36 | 14.42 |
| Average | \(\bar{y}_1= 10.00\) | \(\bar{y}_2= 11.00\) | \(\bar{y}_3= 12.00\) |
Lab Sloppy Dotplot

The sample means from the two labs turned out to be the same and thus the differences in the sample means from the two labs are zero.
From which data set can you draw more conclusive evidence that the means from the three populations are different?
We need to compare the between-sample-variation to the within-sample-variation. Since the between-sample-variation from Lab Sloppy is large compared to the within-sample-variation for data from Lab Precise, we will be more inclined to conclude that the three population means are different using the data from Lab Precise. Since such analysis is based on the analysis of variances for the data set, we call this statistical method the Analysis of Variance (or ANOVA).
10.2 - A Statistical Test for One-Way ANOVA
10.2 - A Statistical Test for One-Way ANOVABefore we go into the details of the test, we need to determine the null and alternative hypotheses. Recall that for a test for two independent means, the null hypothesis was \(\mu_1=\mu_2\). In one-way ANOVA, we want to compare \(t\) population means, where \(t>2\). Therefore, the null hypothesis for analysis of variance for \(t\) population means is:
\(H_0\colon \mu_1=\mu_2=...\mu_t\)
The alternative, however, cannot be set up similarly to the two-sample case. If we wanted to see if two population means are different, the alternative would be \(\mu_1\ne\mu_2\). With more than two groups, the research question is “Are some of the means different?." If we set up the alternative to be \(\mu_1\ne\mu_2\ne…\ne\mu_t\), then we would have a test to see if ALL the means are different. This is not what we want. We need to be careful how we set up the alternative. The mathematical version of the alternative is...
\(H_a\colon \mu_i\ne\mu_j\text{ for some }i \text{ and }j \text{ where }i\ne j\)
This means that at least one of the pairs is not equal. The more common presentation of the alternative is:
\(H_a\colon \text{ at least one mean is different}\) or \(H_a\colon \text{ not all the means are equal}\)
Recall that when we compare the means of two populations for independent samples, we use a 2-sample t-test with pooled variance when the population variances can be assumed equal.
- Test Statistic for One-Way ANOVA
-
For more than two populations, the test statistic, \(F\), is the ratio of between group sample variance and the within-group-sample variance. That is,
\(F=\dfrac{\text{between group variance}}{\text{within group variance}}\)
Under the null hypothesis (and with certain assumptions), both quantities estimate the variance of the random error, and thus the ratio should be close to 1. If the ratio is large, then we have evidence against the null, and hence, we would reject the null hypothesis.
In the next section, we present the assumptions for this test. In the following section, we present how to find the between group variance, the within group variance, and the F-statistic in the ANOVA table.
10.2.1 - ANOVA Assumptions
10.2.1 - ANOVA AssumptionsAssumptions for One-Way ANOVA Test
There are three primary assumptions in ANOVA:
- The responses for each factor level have a normal population distribution.
- These distributions have the same variance.
- The data are independent.
A general rule of thumb for equal variances is to compare the smallest and largest sample standard deviations. This is much like the rule of thumb for equal variances for the test for independent means. If the ratio of these two sample standard deviations falls within 0.5 to 2, then it may be that the assumption is not violated.
Example 10-1: Tar Content Comparisons
Recall the application from the beginning of the lesson. We wanted to see whether the tar contents (in milligrams) for three different brands of cigarettes were different. Lab Precise and Lab Sloppy each took six samples from each of the three brands (A, B and C). Check the assumptions for this example.
Lab Precise
- The sample size is small. We should check for obvious violations using the Normal Probability Plot.
The graph shows no obvious violations from Normal, but we should proceed with caution.
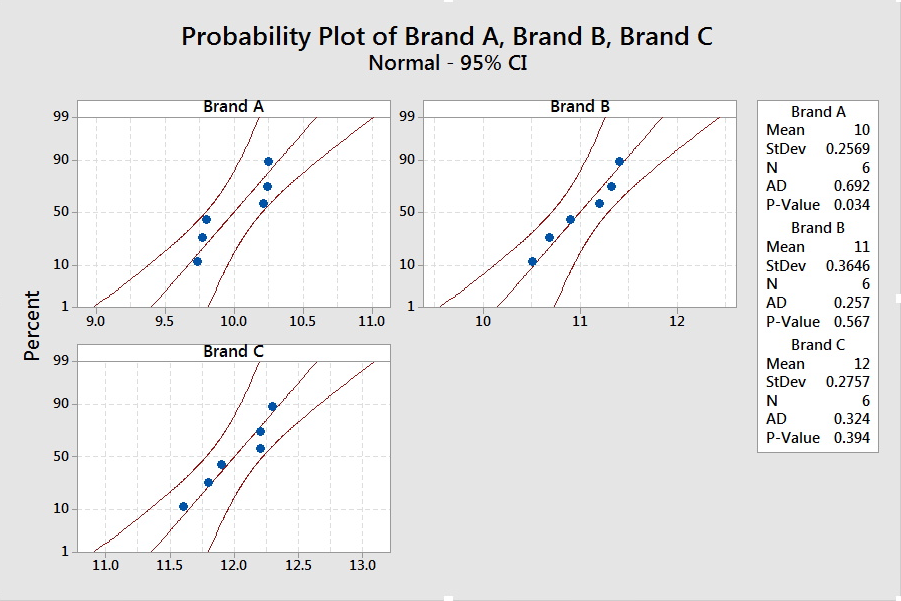
- The summary statistics for the three brands are presented.
Descriptive Statistics: Precise Brand A, Precise Brand B, Precise Brand C
Variable Mean
StDev
Precise Brand A
10.000
0.257
Precise Brand B
11.000
0.365
Precise Brand C
12.000
0.276
The smallest standard deviation is 0.257, and twice the value is 0.514. The largest standard deviation is less than this value. Since the sample sizes are the same, it is safe to assume the standard deviations (and thus the variances) are equal.
- The samples were taken independently, so there is no indication that this assumption is violated.
Lab Sloppy
-
The sample size is small. We should check for obvious violations using the Normal Probability Plot.
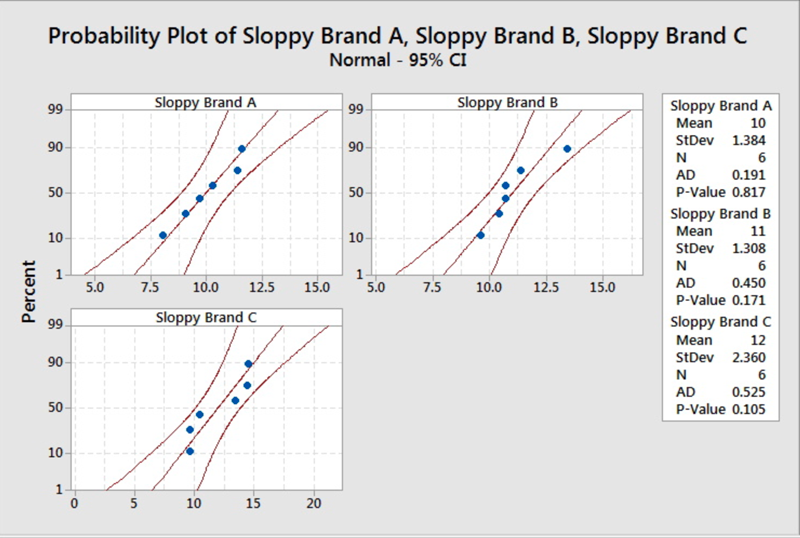
- The summary statistics for the three brands are presented.
Descriptive Statistics: Sloppy Brand A, Sloppy Brand B, Sloppy Brand C
Variable Mean
StDev
Sloppy Brand A
10.000
1.384
Sloppy Brand B
11.000
1.308
Sloppy Brand C
12.000
2.360
The smallest standard deviation is 1.308, and twice the value is 2.616. The largest standard deviation is less than this value. Since the sample sizes are the same, it is safe to assume the standard deviations (and thus the variances) are equal.
-
The samples were taken independently, so there is no indication that this assumption is violated.
10.2.2 - The ANOVA Table
10.2.2 - The ANOVA TableIn this section, we present the Analysis of Variance Table for a completely randomized design, such as the tar content example.
Data Table
Random samples of size \(n_1, …, n_t\) are drawn from the respective \(t\) populations. The data would have the following format:
|
Population |
Data |
Mean |
|||
|---|---|---|---|---|---|
|
1 |
\(y_{11}\) |
\(y_{12}\) |
... |
\(y_{1n_1}\) |
\(\bar{y}_{1.}\) |
|
2 |
\(y_{21}\) |
\(y_{22}\) |
... |
\(y_{2n_2}\) |
\(\bar{y}_{2.}\) |
|
⋮ |
⋮ |
⋮ |
⋮ |
⋮ |
⋮ |
|
\(t\) |
\(y_{t1}\) |
\(y_{t2}\) |
... |
\(y_{tn_t}\) |
\(\bar{y}_{t.}\) |
Notation
\(t\): The total number of groups
\(y_{ij}\): The \(j^{th}\) observation from the \(i^{th}\) population.
\(n_i\): The sample size from the \(i^{th}\) population.
\(n_T\): The total sample size: \(n_T=\sum_{i=1}^t n_i\).
\(\bar{y}_{i.}\): The mean of the sample from the \(i^{th}\) population.
\(\bar{y}_{..}\): The mean of the combined data. Also called the overall mean.
Recall that we want to examine the between group variation and the within group variation. We can find an estimate of the variations with the following:
- Sum of Squares for Treatment or the Between Group Sum of Squares
- \(\text{SST}=\sum_{i=1}^t n_i(\bar{y}_{i.}-\bar{y}_{..})^2\)
- Sum of Squares for Error or the Within Group Sum of Squares
- \(\text{SSE}=\sum_{i, j} (y_{ij}-\bar{y}_{i.})^2\)
- Total Sum of Squares
- \(\text{TSS}=\sum_{i,j} (y_{ij}-\bar{y}_{..})^2\)
It can be derived that \(\text{TSS } = \text{ SST } + \text{ SSE}\).
We can set up the ANOVA table to help us find the F-statistic. Hover over the light bulb to get more information on that item.
The ANOVA Table
|
Source |
Df |
SS |
MS |
F |
P-value |
|---|---|---|---|---|---|
|
Treatment |
\(t-1\) |
\(\text{SST}\) |
\(\text{MST}=\dfrac{\text{SST}}{t-1}\) |
\(\dfrac{\text{MST}}{\text{MSE}}\) |
|
|
Error |
\(n_T-t\) |
\(\text{SSE}\) |
\(\text{MSE}=\dfrac{\text{SSE}}{n_T-t}\) |
||
|
Total |
\(n_T-1\) |
\(\text{TSS}\) |
The p-value is found using the F-statistic and the F-distribution. We will not ask you to find the p-value for this test. You will only need to know how to interpret it. If the p-value is less than our predetermined significance level, we will reject the null hypothesis that all the means are equal.
The ANOVA table can easily be obtained by statistical software and hand computation of such quantities are very tedious.
10.3 - Multiple Comparisons
10.3 - Multiple ComparisonsIf our test of the null hypothesis is rejected, we conclude that not all the means are equal: that is, at least one mean is different from the other means. The ANOVA test itself provides only statistical evidence of a difference, but not any statistical evidence as to which mean or means are statistically different.
For instance, using the previous example for tar content, if the ANOVA test results in a significant difference in average tar content between the cigarette brands, a follow up analysis would be needed to determine which brand mean or means differ in tar content. Plus we would want to know if one brand or multiple brands were better/worse than another brand in average tar content. To complete this analysis we use a method called multiple comparisons.
Multiple comparisons conducts an analysis of all possible pairwise means. For example, with three brands of cigarettes, A, B, and C, if the ANOVA test was significant, then multiple comparison methods would compare the three possible pairwise comparisons:
- Brand A to Brand B
- Brand A to Brand C
- Brand B to Brand C
These are essentially tests of two means similar to what we learned previously in our lesson for comparing two means. However, the methods here use an adjustment to account for the number of comparisons taking place. Minitab provides three adjustment choices. We will use the Tukey adjustment which is an adjustment on the t-multiplier based on the number of comparisons.
Note! We don’t go in the theory behind the Tukey method. Just note that we only use a multiple comparison technique in ANOVA when we have a significant result.
In the next section, we present an example to walk through the ANOVA results.
Minitab®
Using Minitab to Perform One-Way ANOVA
If the data entered in Minitab are in different columns, then in Minitab we use:
- Stat > ANOVA > One-Way
- Select the format structure of the data in the worksheet.
- If the responses are in one column and the factors are in their own column, then select the drop down of 'Response data are in one column for all factor levels.'
- If the responses are in their own column for each factor level, then select 'Response data are in a separate column for each factor level.'
- Next, in case we have a significant ANOVA result, and we want to conduct a multiple comparison analysis, we preemptively click 'Comparisons', the box for Tukey, and verify that the boxes for 'Interval plot for differences of means' and 'Grouping Information' are also checked.
- Click OK and OK again.
Example: Tar Content (ANOVA)
Test the hypothesis that the means are the same vs. at least one is different for both labs. Compare the two labs and comment.
Lab Precise
We are testing the following hypotheses:
\(H_0\colon \mu_1=\mu_2=\mu_3\) vs \(H_a\colon\text{ at least one mean is different}\)
The assumptions were discussed in the previous example.
The following is the output for one-way ANOVA for Lab Precise:
One-way ANOVA: Precise A, Precise B, Precise C
Method
| Null Hypothesis | All means are equal |
|---|---|
| Alternative Hypothesis | Not all means are equal |
| Significance Level | \(\alpha\)= 0.05 |
Equal variances were assumed for the analysis.
Factor Information
| Factor | Levels | Values |
|---|---|---|
|
Factor |
3 | Precise A, Precise B, Precise C |
Analysis of Variance
| Source | DF | Adj SS | Adj MS | F-Value | P-Value |
|---|---|---|---|---|---|
|
Factor |
2 | 12.000 | 6.00000 | 65.46 | 0.000 |
| Error | 15 | 1.375 | 0.09165 | ||
| Total | 17 | 13.375 |
Model Summary
| S | R-sq | R-sq(adj) | R-sq(pred) |
|---|---|---|---|
| 0.302743 | 89.72% | 88.35% | 85.20% |
The p-value for this test is less than 0.0001. At any reasonable significance level, we would reject the null hypothesis and conclude there is enough evidence in the data to suggest at least one mean tar content is different.
But which ones are different? The next step is to examine the multiple comparisons. Minitab provides the following output:
Means
| Factor | N | Mean | StDev | 95% CI |
|---|---|---|---|---|
| Precise A | 6 | 10.000 | 0.257 | (9.737, 10.263) |
| Precise B | 6 | 11.000 | 0.365 | (10.737, 11.263) |
| Precise C | 6 | 12.000 | 0.276 | (11.737, 12.263) |
Pooled StDev = 0.302743
Tukey Pairwise Comparisons
Grouping Information Using the Tukey Method and 95% Confidence
| Factor | N | Mean | Grouping |
|---|---|---|---|
| Precise C | 6 | 12.000 | A |
| Precise B | 6 | 11.000 | B |
| Precise A | 6 | 10.000 | C |
Means that do not share a letter are significantly different.
The Tukey pairwise comparisons suggest that all the means are different. Therefore, Brand C has the highest tar content and Brand A has the lowest.
Lab Sloppy
We are testing the same hypotheses for Lab Sloppy as Lab Precise, and the assumptions were checked. The ANOVA output for Lab Sloppy is:
One-way ANOVA: Sloppy A, Sloppy B, Sloppy C
Method
| Null Hypothesis | All means are equal |
|---|---|
| Alternative Hypothesis | Not all means are equal |
| Significance Level | \(\alpha\)= 0.05 |
Equal variances were assumed for the analysis.
Factor Information
| Factor | Levels | Values |
|---|---|---|
|
Factor |
3 |
Sloppy A, Sloppy B, Sloppy C |
Analysis of Variance
| Source | DF | Adj SS | Adj MS | F-Value | P-Value |
|---|---|---|---|---|---|
|
Factor |
2 | 12.00 | 6.000 | 1.96 | 0.176 |
| Error | 15 | 45.98 | 3.065 | ||
| Total | 17 | 57.98 |
Model Summary
| S | R-sq | R-sq(adj) | R-sq(pred) |
|---|---|---|---|
| 1.75073 | 20.70% | 10.12% | 0.00% |
Comparison
The one-way ANOVA showed statistically significant results for Lab Precise but not for Lab Sloppy. Recall that ANOVA compares the within variation and the between variation. For Lab Precise, the within variation was small compared to the between variation. This resulted in a large F-statistic (65.46) and thus a small p-value. For Lab Sloppy, this ratio was small (1.96), resulting in a large p-value.
Try it!
20 young pigs are assigned at random among 4 experimental groups. Each group is fed a different diet. (This design is a completely randomized design.) The data are the pig's weight, in kilograms, after being raised on these diets for 10 months (pig_weights.txt). We wish to determine whether the mean pig weights are the same for all 4 diets.
First, we set up our hypothesis test:
\(H_0\colon \mu_1=\mu_2=\mu_3=\mu_4\)
\(H_a\colon \text { at least one mean weight is different}\)
Here are the data that were obtained from the four experimental groups, as well as, their summary statistics:
| Feed 1 | Feed 2 | Feed 3 | Feed 4 |
|---|---|---|---|
| 60.8 | 68.3 | 102.6 | 87.9 |
| 57.1 | 67.7 | 102.2 | 84.7 |
| 65.0 | 74.0 | 100.5 | 83.2 |
| 58.7 | 66.3 | 97.5 | 85.8 |
| 61.8 | 69.9 | 98.9 | 90.3 |
Output from Minitab:
Descriptive Statistics: Feed 1, Feed 2, Feed 3, Feed 4
Statistics
| Variable |
N |
N* | Mean | StDev | Minimum | Maximum |
|---|---|---|---|---|---|---|
|
Feed 1 |
5 | 0 | 60.68 | 3.03 | 57.10 | 65.00 |
|
Feed 2 |
5 | 0 | 69.24 | 2.96 | 66.30 | 74.00 |
| Feed 3 | 5 | 0 | 100.34 | 2.16 | 97.50 | 102.60 |
| Feed 4 | 5 | 0 | 86.38 | 2.78 | 83.20 | 90.30 |
The smallest standard deviation is 2.16, and the largest is 3.03. Since the rule of thumb is satisfied here, we can say the equal variance assumption is not violated. The description suggests that the samples are independent. There is nothing in the description to suggest the weights come from a normal distribution. The normal probability plots are:
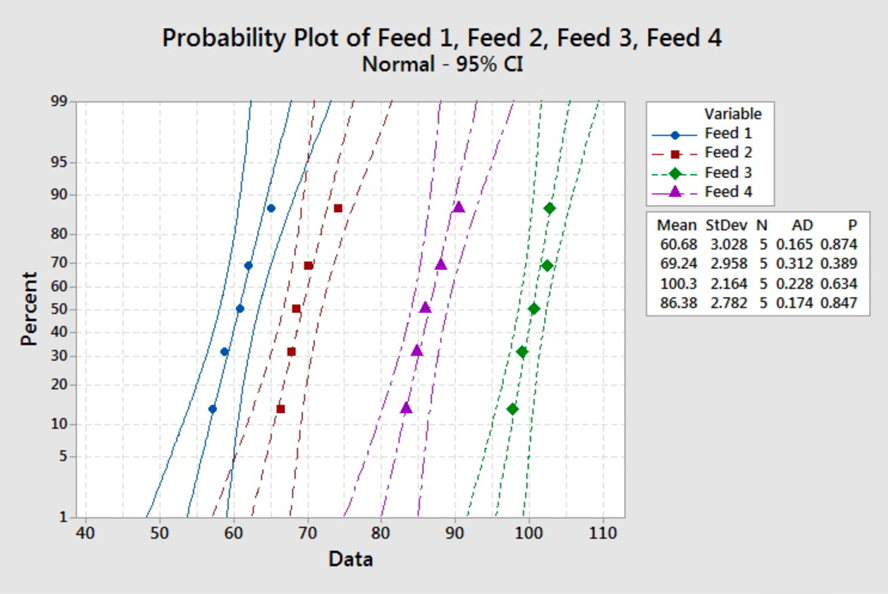
There are no obvious violations from the normal assumption, but we should proceed with caution as the sample sizes are very small.
The ANOVA output is:
One-way ANOVA: Feed 1, Feed 2, Feed 3, Feed 4
Method
| Null Hypothesis | All means are equal |
|---|---|
| Alternative Hypothesis | Not all means are equal |
| Significance Level | \(\alpha\)= 0.05 |
Equal variances were assumed for the analysis.
Factor Information
| Factor | Levels | Values |
|---|---|---|
|
Factor |
4 | Feed 1, Feed 2, Feed 3, Feed 4 |
Analysis of Variance
| Source | DF | Adj SS | Adj MS | F-Value | P-Value |
|---|---|---|---|---|---|
|
Factor |
3 | 4703.2 | 1567.73 | 206.72 | 0.000 |
| Error | 16 | 121.3 | 7.58 | ||
| Total | 19 | 4824.5 |
Model Summary
| S | R-sq | R-sq(adj) | R-sq(pred) |
|---|---|---|---|
| 2.75386 | 97.48% | 97.01% | 96.07% |
The p-value for the test is less than 0.001. With a significance level of 5%, we reject the null hypothesis. The data provide sufficient evidence to conclude that the mean weights of pigs from the four feeds are not all the same.
With a rejection of the null hypothesis leading us to conclude that not all the means are equal (i.e., at least the mean pig weight or one diet differs from the mean pig weight from the other diets) some follow up questions are:
- "Which diet type results in different average pig weights?", and
- "Is there one particular diet type that produces the largest/smallest mean weight?"
To answer these questions we analyze the multiple comparison output (the grouping information) and the interval graph.
Means
| Factor | N | Mean | StDev | 95% CI |
|---|---|---|---|---|
| Feed 1 | 5 | 60.68 | 3.03 | (58.07, 63.29) |
| Feed 2 | 5 | 69.24 | 2.96 | (66.63, 71.85) |
| Feed 3 | 5 | 100.340 | 2.164 | (97.729, 102.951) |
| Feed 4 | 5 | 86.38 | 2.78 | (83.77, 88.99) |
Pooled StDev = 2.75386
Tukey Pairwise Comparisons
Grouping Information Using the Tukey Method and 95% Confidence
| Factor | N | Mean | Grouping | ||||
|---|---|---|---|---|---|---|---|
| Feed 3 | 5 | 100.340 | A | ||||
| Feed 4 | 5 | 86.38 | B | ||||
| Feed 2 | 5 | 69.24 | C | ||||
| Feed 1 | 5 | 60.68 | D | ||||
Means that do not share a letter are significantly different.
Each of these factor levels are associated with a grouping letter. If any factor levels have the same letter, then the multiple comparison method did not determine a significant difference between the mean response. For any factor level that does not share a letter, a significant mean difference was identified. From the lettering we see each Diet Type has a different letter, i.e. no two groups share a letter. Therefore, we can conclude that all four diets resulted in statistically significant different mean pig weights. Furthermore, with the order of the means also provided from highest to lowest, we can say that Feed 3 resulted in the highest mean weight followed by Feed 4, then Feed 2, then Feed 1. This grouping result is supported by the graph of the intervals.
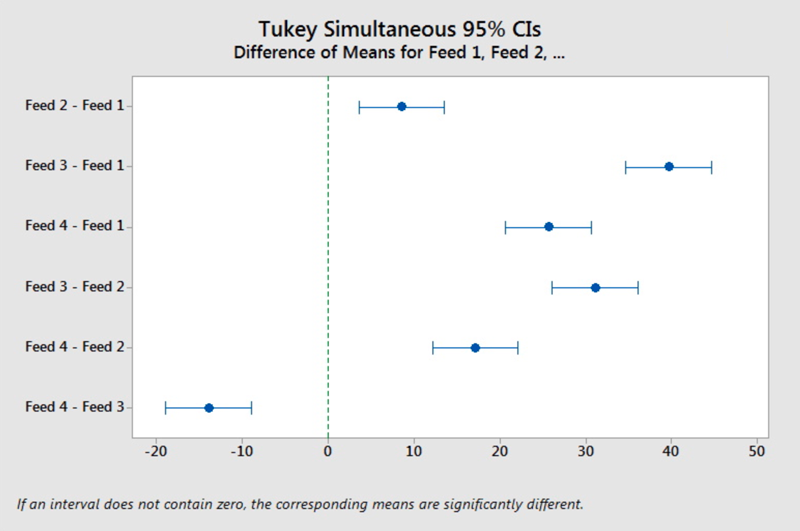
In analyzing the intervals, we reflect back on our lesson in comparing two means: if an interval contained zero, we could not conclude a difference between the two means; if the interval did not contain zero, then a difference between the two means was supported. With four factor levels, there are six possible pairwise comparisons. (Remember the binomial formula where we had the counter for the number of possible outcomes? In this case \(4\choose 2\) = 6). In inspecting each of these six intervals, we find that all six do NOT include zero. Therefore, there is a statistical difference between all four group means; the four types of diet resulted in significantly different mean pig weights.
10.4 - Two-Way ANOVA
10.4 - Two-Way ANOVAThe one-way ANOVA presented in the Lesson is a simple case. In practice, research questions are rarely this “simple.” ANOVA models become increasingly complex very quickly.
The two-way ANOVA model is briefly introduced here to give you an idea of what to expect in practice. Even two-way ANOVA can be too “simple” for practice.
In two-way ANOVA, there are two factors of interest. When there are two factors, the experimental units get a combination of treatments.
Suppose a researcher is interested in examining how different fertilizers affect the growth of plants. However, the researcher is also interested in the growth of different species of plant. Species is the second factor, making this a two-factor experiment. But... those of you with green thumbs say sometimes different fertilizers are more effective on different species of plants!
This is the idea behind two-way ANOVA. If you are interested in more complex ANOVA models, you should consider taking STAT 502 and STAT 503.
10.5 - Summary
10.5 - SummaryIn this Lesson, we introduced One-way Analysis of Variance (ANOVA). The ANOVA test tests the hypothesis that the population means for the groups are the same against the hypothesis that at least one of the means is different. If the null hypothesis is rejected, we need to perform multiple comparisons to determine which means are different.