13.2.1 - Further Logistic Regression Examples
13.2.1 - Further Logistic Regression ExamplesExample 15-1: STAT 200 Dataset
Students in STAT 200 at Penn State were asked if they have ever driven after drinking (the dataset unfortunately no longer available). They also were asked, “How many days per month do you drink at least two beers?” In the following discussion, \(\pi\) = the probability a student says “yes” they have driven after drinking. This is modeled using X = days per month of drinking two beers. Results from Minitab were as follows.
| Variable | Value | Count |
|---|---|---|
| DrivDrnk | Yes | 122 (Event) |
| No | 127 | |
| Total | 249 |
| 95% CI | |||||||
|---|---|---|---|---|---|---|---|
| Coef | SE Coef | Z | P | Odds Ratio | Lower | Upper | |
| Constant | -1.5514 | 0.2661 | -5.83 | 0.000 | |||
| DaysBeer | 0.19031 | 0.02946 | 6.46 | 0.000 | 1.21 | 1.14 | 1.28 |
Some things to note from the results are:
- We see that in the sample 122/249 students said they have driven after drinking. (Yikes!)
- Parameter estimates, given under Coef are \(\hat{\beta}_0\) = −1.5514, and \(\hat{\beta}_1\) = 0.19031.
- The model for estimating \(\pi\) = the probability of ever having driven after drinking is
\(\hat{\pi}=\dfrac{\exp(-1.5514+0.19031X)}{1+\exp(-1.5514+0.19031X)}\)
- The variable X = DaysBeer is a statistically significant predictor (Z = 6.46, P = 0.000).
We can also obtain a plot of the estimated probability of ever having driven under the influence (\(\pi\)) versus days per month of drinking at least two beers.
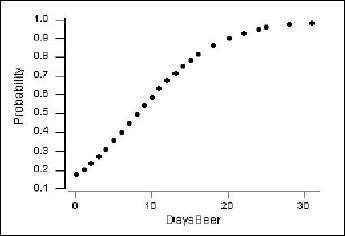
The vertical axis shows the probability of ever having driven after drinking. For example, if X = 4 days per month of drinking beer, then the estimated probability is calculated as:
\(\hat{\pi}=\dfrac{\exp(-1.5514+0.19031(4))}{1+\exp(-1.5514+0.19031(4))}=\frac{\exp(-0.79016)}{1+\exp(-0.79016)}=0.312\)
A few of these estimated probabilities are given in the following table:
| DaysBeer | 4 | 12 | 20 | 28 |
|---|---|---|---|---|
| \(\hat{\pi}\) | 0.312 | 0.675 | 0.905 | 0.97 |
In the results given above, we see that the estimate of the odds ratio is 1.21 for DaysBeer. This is given under Odds Ratio in the table of coefficients, standard errors, and so on. The sample odds ratio was calculated as \(e^{0.19031}\). The interpretation of the odds ratio is that for each increase of one day of drinking beer per month, the predicted odds of having ever driven after drinking are multiplied by 1.21.
Above we found that at X = 4, the predicted probability of ever driving after drinking is \(\hat{\pi}\) = 0.312. Thus when X = 4, the predicted odds of ever driving after drinking is 0.312/(1 − 0.312) = 0.453. To find the odds when X = 5, one method would be to multiply the odds at X = 4 by the sample odds ratio. The calculation is 1.21 × 0.453 = 0.549. (Another method is to just do the calculation as we did for X = 4.)
Notice also, that the results give a 95% confidence interval estimate of the odd ratio (1.14 to 1.28).
We now include Gender (male or female) as an x-variable (along with DaysBeer). Some Minitab results are given below. Under Gender, the row for male is explaining that the program created an indicator variable with a value of 1 if the student is male and a value of 0 if the student is female.
| 95% CI | |||||||
|---|---|---|---|---|---|---|---|
| Coef | SE Coef | Z | P | Odds Ratio | Lower | Upper | |
| Constant | -1.7736 | 0.2945 | -6.02 | 0.000 | |||
| DaysBeer | 0.18693 | 0.03004 | 6.22 | 0.000 | 1.21 | 1.14 | 1.28 |
|
Gender male |
0.6172 | 0.2954 | 2.09 | 0.037 | 1.85 | 1.04 | 3.31 |
Some things to note from the results are:
- The p-values are less than 0.05 for both DaysBeer and Gender. This is evidence that both x-variables are useful for predicting the probability of ever having driven after drinking.
- For DaysBeer, the odds ratio is still estimated to equal 1.21 to two decimal places (calculated as \(e^{0.18693}\)).
- For Gender, the odds ratio is 1.85 (calculated as \(e^{0.6172}\)). For males, the odds of ever having driven after drinking is 1.85 times the odds for females, assuming DaysBeer is held constant.
Finally, the results for testing with respect to the multiple logistic regression model are as follows:
Log-Likelihood = -139.981
Test that all slopes are zero: G = 65.125, DF = 2, P-Value = 0.000
Notice that since we have a p-value of 0.000 for this chi-square test, we, therefore, reject the null hypothesis that all of the slopes are equal to 0.
Example 15-2: Toxicity Dataset

An experiment is done to test the effect of a toxic substance on insects. The data originate from the textbook, Applied Linear Statistical Models by Kutner, Nachtsheim, Neter, & Li.
At each of six dose levels, 250 insects are exposed to the substance and the number of insects that die is counted (Toxicity data). We can use Minitab to calculate the observed probabilities as the number of observed deaths out of 250 for each dose level.
A binary logistic regression model is used to describe the connection between the observed probabilities of death as a function of dose level. Since the data is in event/trial format the procedure in Minitab is a little different to before:
- Select Stat > Regression > Binary Logistic Regression > Fit Binary Logistic Model
- Select "Response is in event/trial format"
- Select "Deaths" for Number of events, "SampSize" for Number of trials (and type "Death" for Event name if you like)
- Select Dose as a Continuous predictor
- Click Results and change "Display of results" to "Expanded tables"
- Click Storage and select "Fits (event probabilities)"
The Minitab output is as follows:
Coefficients
| Term | Coef | SE Coef | 95% CI | Z | P | VIF |
|---|---|---|---|---|---|---|
| Constant | -2.644 | 0.156 | (-2.950, -2.338) | -16.94 | 0.000 | |
| Dose | 0.6740 | 0.0391 | (0.5973, 0.7506) | 17.23 | 0.000 | 1.00 |
Odds Ratios for Continuous Predictors
| Term | Odds Ratio | 95% CI |
|---|---|---|
| Dose | 1.9621 | (1.8173, 2.1184) |
Thus
\(\hat{\pi}=\dfrac{\exp(-2.644+0.674X)}{1+\exp(-2.644+0.674X)}\)
where X = Dose and \(\hat{\pi}\) is the estimated probability the insect dies (based on the model).
Predicted probabilities of death (based on the logistic model) for the six dose levels are given below (FITS). These probabilities closely agree with the observed values (Observed p) reported.
Data Display
| Row | Dose | SampSize | Deaths | Observed P | FITS |
|---|---|---|---|---|---|
| 1 | 1 | 250 | 28 | 0.112 | 0.122423 |
| 2 | 2 | 250 | 53 | 0.212 | 0.214891 |
| 3 | 3 | 250 | 93 | 0.372 | 0.349396 |
| 4 | 4 | 250 | 126 | 0.504 | 0.513071 |
| 5 | 5 | 250 | 172 | 0.688 | 0.673990 |
| 6 | 6 | 250 | 197 | 0.788 | 0.802229 |
As an example of calculating the estimated probabilities, for Dose 1, we have
\(\hat{\pi}=\dfrac{\exp(-2.644+0.674(1))}{1+\exp(-2.644+0.674(1))}=0.1224\)
The odds ratio for Dose is 1.9621, the value under Odds Ratio in the output. It was calculated as \(e^{0.674}\). The interpretation of the odds ratio is that for every increase of 1 unit in dose level, the estimated odds of insect death are multiplied by 1.9621.
As an example of odds and odds ratio:
- At Dose = 1, the estimated odds of death is \(\hat{\pi}/(1− \hat{\pi})\) = 0.1224/(1−0.1224) = 0.1395.
- At Dose = 2, the estimated odds of death is \(\hat{\pi}/(1− \hat{\pi})\) = 0.2149/(1−0.2149) = 0.2737.
- The Odds Ratio = \(\dfrac{0.2737}{0.1395}\), which is the ratio of the odds of death when Dose = 2 compared to the odds when Dose = 1.
A property of the binary logistic regression model is that the odds ratio is the same for any increase of one unit in X, regardless of the specific values of X.