9.8 - Polynomial Regression Examples
9.8 - Polynomial Regression ExamplesExample 9-5: How is the length of a bluegill fish related to its age?
In 1981, n = 78 bluegills were randomly sampled from Lake Mary in Minnesota. The researchers (Cook and Weisberg, 1999) measured and recorded the following data (Bluegills dataset):
- Response \(\left(y \right) \colon\) length (in mm) of the fish
- Potential predictor \(\left(x_1 \right) \colon \) age (in years) of the fish
The researchers were primarily interested in learning how the length of a bluegill fish is related to its age.
A scatter plot of the data:
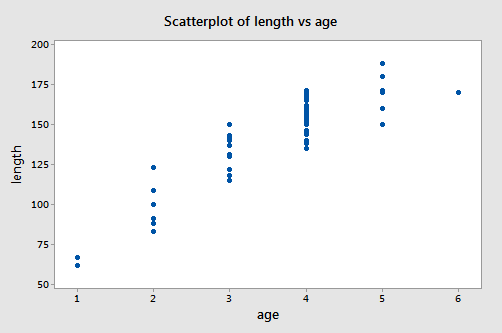
suggests that there is a positive trend in the data. Not surprisingly, as the age of bluegill fish increases, the length of the fish tends to increase. The trend, however, doesn't appear to be quite linear. It appears as if the relationship is slightly curved.
One way of modeling the curvature in these data is to formulate a "second-order polynomial model" with one quantitative predictor:
\(y_i=(\beta_0+\beta_1x_{i}+\beta_{11}x_{i}^2)+\epsilon_i\)
where:
- \(y_i\) is length of bluegill (fish) \(i\) (in mm)
- \(x_i\) is age of bluegill (fish) \(i\) (in years)
and the independent error terms \(\epsilon_i\) follow a normal distribution with mean 0 and equal variance \(\sigma^{2}\).
You may recall from your previous studies that the "quadratic function" is another name for our formulated regression function. Nonetheless, you'll often hear statisticians referring to this quadratic model as a second-order model, because the highest power on the \(x_i\) term is 2.
Incidentally, observe the notation used. Because there is only one predictor variable to keep track of, the 1 in the subscript of \(x_{i1}\) has been dropped. That is, we use our original notation of just \(x_i\). Also note the double subscript used on the slope term, \(\beta_{11}\), of the quadratic term, as a way of denoting that it is associated with the squared term of the one and only predictor.
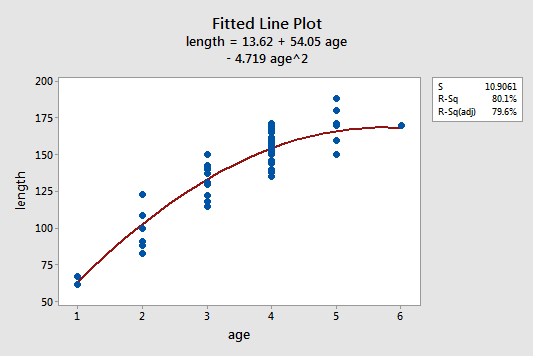
The estimated quadratic regression equation looks like it does a pretty good job of fitting the data:
To answer the following potential research questions, do the procedures identified in parentheses seem reasonable?
- How is the length of a bluegill fish related to its age? (Describe the "quadratic" nature of the regression function.)
- What is the length of a randomly selected five-year-old bluegill fish? (Calculate and interpret a prediction interval for the response.)
Among other things, the Minitab output:
Analysis of Variance
| Source | DF | Adj SS | Adj MS | F-Value | P-Value |
|---|---|---|---|---|---|
| Regression | 2 | 35938.0 | 17969.0 | 151.07 | 0.000 |
| age | 1 | 8252.5 | 8252.5 | 69.38 | 0.000 |
| age^2 | 1 | 2972.1 | 2972.1 | 24.99 | 0.000 |
| Error | 75 | 8920.7 | 118.9 | ||
| Lack-of-Fit | 3 | 108.0 | 360 | 0.29 | 0.829 |
| Pure Error | 72 | 88121.7 | 122.4 | ||
| Total | 77 | 44858.7 |
Model Summary
| S | R-sq | R-sq(adj) | R-sq(pred) |
|---|---|---|---|
| 10.9061 | 80.11% | 79.58% | 78.72% |
Coefficients
| Term | Coef | SE Coef | T-Value | P-Value | VIF |
|---|---|---|---|---|---|
| Constant | 13.6 | 11.0 | 1.24 | 0.220 | |
| age | 54.05 | 6.49 | 8.33 | 0.000 | 23.44 |
| age^2 | -4.719 | 0.944 | -5.00 | 0.000 | 23.44 |
Regression Equation
\(\widehat{length} = 13.6 + 54.05 age - 4.719 age^2\)
Predictions for length
| Variable | Setting |
|---|---|
| age | 5 |
| age^2 | 25 |
| Fit | SE Fit | 95% CI | 95% PI |
|---|---|---|---|
| 165.902 | 2.76901 | (160.386, 171.418) | (143.487, 188.318) |
tells us that:
- 80.1% of the variation in the length of bluegill fish is reduced by taking into account a quadratic function of the age of the fish.
- We can be 95% confident that the length of a randomly selected five-year-old bluegill fish is between 143.5 and 188.3 mm.
Example 9-6: Yield Data Set

This data set of size n = 15 (Yield data) contains measurements of yield from an experiment done at five different temperature levels. The variables are y = yield and x = temperature in degrees Fahrenheit. The table below gives the data used for this analysis.
| i | Temperature | Yield |
|---|---|---|
| 1 | 50 | 3.3 |
| 2 | 50 | 2.8 |
| 3 | 50 | 2.9 |
| 4 | 70 | 2.3 |
| 5 | 70 | 2.6 |
| 6 | 70 | 2.1 |
| 7 | 80 | 2.5 |
| 8 | 80 | 2.9 |
| 9 | 80 | 2.4 |
| 10 | 90 | 3.0 |
| 11 | 90 | 3.1 |
| 12 | 90 | 2.8 |
| 13 | 100 | 3.3 |
| 14 | 100 | 3.5 |
| 15 | 100 | 3.0 |
The figures below give a scatterplot of the raw data and then another scatterplot with lines pertaining to a linear fit and a quadratic fit overlayed. Obviously, the trend of this data is better suited to a quadratic fit.
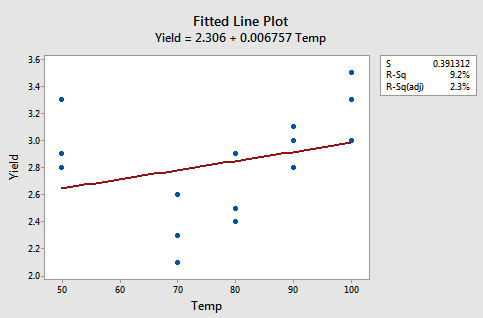
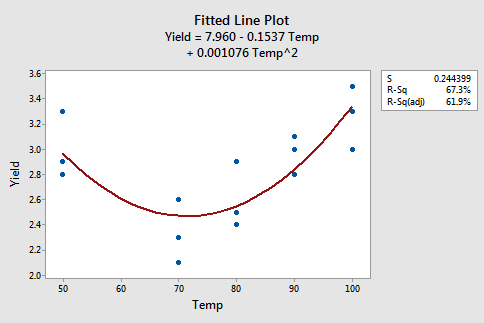
Here we have the linear fit results:
Regression Analysis: Yield versus Temp
Model Summary
| S | R-sq | R-sq(adj) | R-sq(pred) |
|---|---|---|---|
| 0.391312 | 9.24% | 2.26% | 0.00% |
Coefficients
| Term | Coef | SE Coef | T-Value | P-Value | VIF |
|---|---|---|---|---|---|
| Constant | 2.306 | 0.469 | 4.92 | 0.000 | |
| Temp | 0.00676 | 0.00587 | 1.15 | 0.271 | 1.00 |
Regression Equation
\(\widehat{Yield} = 2.306 + 0.00676 Temp\)
Here we have the quadratic fit results:
Polynomial Regression Analysis: Yield versus Temp
Model Summary
| S | R-sq | R-sq(adj) | R-sq(pred) |
|---|---|---|---|
| 0.244399 | 67.32% | 61.87% | 46.64% |
Coefficients
| Term | Coef | SE Coef | T-Value | P-Value | VIF |
|---|---|---|---|---|---|
| Constant | 7.96 | 1.26 | 6.32 | 0.000 | |
| Temp | -0.1537 | 0.0349 | -4.40 | 0.001 | 90.75 |
| Temp*Temp | 0.001076 | 0.000233 | 4.62 | 0.001 | 90.75 |
Regression Equation
\(\widehat{Yield} =7.96 - 0.1537 Temp + 0.001076 Temp*Temp\)
We see that both temperature and temperature squared are significant predictors for the quadratic model (with p-values of 0.0009 and 0.0006, respectively) and that the fit is much better than the linear fit. From this output, we see the estimated regression equation is \(y_{i}=7.960-0.1537x_{i}+0.001076x_{i}^{2}\). Furthermore, the ANOVA table below shows that the model we fit is statistically significant at the 0.05 significance level with a p-value of 0.001.
Analysis of Variance
| Source | DF | Adj SS | Adj MS | F-Value | P-Value |
|---|---|---|---|---|---|
| Regression | 2 | 1.47656 | 0.738282 | 12.36 | 0.001 |
| Temp | 1 | 1.1560 | 1.15596 | 19.35 | 0.001 |
| Temp*Temp | 1 | 1.2739 | 1.27386 | 21.33 | 0.001 |
| Error | 12 | 0.71677 | 0.059731 | ||
| Lack-of-Fit | 2 | 0.1368 | 0.06838 | 1.18 | 0.347 |
| Pure Error | 10 | 0.5800 | 0.05800 | ||
| Total | 14 | 21.9333 |
Example 9-7: Odor Data Set
An experiment is designed to relate three variables (temperature, ratio, and height) to a measure of odor in a chemical process. Each variable has three levels, but the design was not constructed as a full factorial design (i.e., it is not a \(3^{3}\) design). Nonetheless, we can still analyze the data using a response surface regression routine, which is essentially polynomial regression with multiple predictors. The data obtained (Odor data) was already coded and can be found in the table below.
| Odor | Temperature | Ratio | Height |
|---|---|---|---|
| 66 | -1 | -1 | 0 |
| 58 | -1 | 0 | -1 |
| 65 | 0 | -1 | -1 |
| -31 | 0 | 0 | 0 |
| 39 | 1 | -1 | 0 |
| 17 | 1 | 0 | -1 |
| 7 | 0 | 1 | -1 |
| -35 | 0 | 0 | 0 |
| 43 | -1 | 1 | 0 |
| -5 | -1 | 0 | 1 |
| 43 | 0 | -1 | 1 |
| -26 | 0 | 0 | 0 |
| 49 | 1 | 1 | 0 |
| -40 | 1 | 0 | 1 |
| -22 | 0 | 1 | 1 |
First, we will fit a response surface regression model consisting of all of the first-order and second-order terms. The summary of this fit is given below:
Model Summary
| S | R-sq | R-sq(adj) | R-sq(pred) |
|---|---|---|---|
| 18.7747 | 86.83% | 76.95% | 47.64% |
Coefficients
| Term | Coef | SE Coef | T-Value | P-Value | VIF |
|---|---|---|---|---|---|
| Constant | -30.7 | 10.8 | -2.83 | 0.022 | |
| Temp | -12.13 | 6.64 | -1.83 | 0.105 | 1.00 |
| Ratio | -17.00 | 6.64 | -2.56 | 0.034 | 1.00 |
| Height | -21.37 | 6.64 | -3.22 | 0.012 | 1.00 |
| Temp2 | 32.08 | 9.77 | 3.28 | 0.011 | 1.01 |
| Ratio2 | 47.83 | 9.77 | 4.90 | 0.001 | 1.01 |
| Height2 | 6.08 | 9.77 | 0.62 | 0.551 | 1.01 |
As you can see, the square of height is the least statistically significant, so we will drop that term and rerun the analysis. The summary of this new fit is given below:
Model Summary
| S | R-sq | R-sq(adj) | R-sq(pred) |
|---|---|---|---|
| 18.1247 | 86.19% | 78.52% | 56.19% |
Coefficients
| Term | Coef | SE Coef | T-Value | P-Value | VIF |
|---|---|---|---|---|---|
| Constant | -26.92 | 8.71 | -3.09 | 0.013 | |
| Temp | -12.13 | 6.41 | -1.89 | 0.091 | 1.00 |
| Ratio | -17.00 | 6.41 | -2.65 | 0.026 | 1.00 |
| Height | -21.37 | 6.41 | -3.34 | 0.009 | 1.00 |
| Temp2 | 31.62 | 9.40 | 3.36 | 0.008 | 1.01 |
| Ratio2 | 47.37 | 9.40 | 5.04 | 0.001 | 1.01 |
The temperature main effect (i.e., the first-order temperature term) is not significant at the usual 0.05 significance level. However, the square of temperature is statistically significant. To adhere to the hierarchy principle, we'll retain the temperature main effect in the model.