10.3 - Best Subsets Regression, Adjusted R-Sq, Mallows Cp
10.3 - Best Subsets Regression, Adjusted R-Sq, Mallows CpIn this section, we learn about the best subsets regression procedure (also known as the all possible subsets regression procedure). While we will soon learn the finer details, the general idea behind best subsets regression is that we select the subset of predictors that do the best at meeting some well-defined objective criterion, such as having the largest \(R^{2} \text{-value}\) or the smallest MSE.
Again, our hope is that we end up with a reasonable and useful regression model. There is one sure way of ending up with a model that is certain to be underspecified — and that's if the set of candidate predictor variables doesn't include all of the variables that actually predict the response. Therefore, just as is the case for the stepwise regression procedure, a fundamental rule of the best subsets regression procedure is that the list of candidate predictor variables must include all of the variables that actually predict the response. Otherwise, we are sure to end up with a regression model that is underspecified and therefore misleading.
The procedure
A regression analysis utilizing the best subsets regression procedure involves the following steps:
Step #1
First, identify all of the possible regression models derived from all of the possible combinations of the candidate predictors. Unfortunately, this can be a huge number of possible models.
For the sake of example, suppose we have three (3) candidate predictors — \(x_{1}\), \(x_{2}\), and \(x_{3}\)— for our final regression model. Then, there are eight (8) possible regression models we can consider:
- the one (1) model with no predictors
- the three (3) models with only one predictor each — the model with \(x_{1}\) alone; the model with \(x_{2}\) alone; and the model with \(x_{3}\) alone
- the three (3) models with two predictors each — the model with \(x_{1}\) and \(x_{2}\); the model with \(x_{1}\) and \(x_{3}\); and the model with \(x_{2}\) and \(x_{3}\)
- and the one (1) model with all three predictors — that is, the model with \(x_{1}\), \(x_{2}\) and \(x_{3}\)
That's 1 + 3 + 3 + 1 = 8 possible models to consider. It can be shown that when there are four candidate predictors — \(x_{1}\), \(x_{2}\), \(x_{3}\) and \(x_{4}\) — there are 16 possible regression models to consider. In general, if there are p-1 possible candidate predictors, then there are \(2^{p-1}\) possible regression models containing the predictors. For example, 10 predictors yield \(2^{10} = 1024\) possible regression models.
That's a heck of a lot of models to consider! The good news is that statistical software, such as Minitab, does all of the dirty work for us.
Step #2
From the possible models identified in the first step, determine the one-predictor models that do the "best" at meeting some well-defined criteria, the two-predictor models that do the "best," the three-predictor models that do the "best," and so on. For example, suppose we have three candidate predictors — \(x_{1}\), \(x_{2}\), and \(x_{3}\) — for our final regression model. Of the three possible models with one predictor, identify the one or two that do "best." Of the three possible two-predictor models, identify the one or two that do "best." By doing this, it cuts down considerably the number of possible regression models to consider!
But, have you noticed that we have not yet even defined what we mean by "best"? What do you think "best" means? Of course, you'll probably define it differently than me or than your neighbor. Therein lies the rub — we might not be able to agree on what's best! In thinking about what "best" means, you might have thought of any of the following:
- the model with the largest \(R^{2}\)
- the model with the largest adjusted \(R^{2}\)
- the model with the smallest MSE (or S = square root of MSE)
There are other criteria you probably didn't think of, but we could consider, too, for example, Mallows' \(C_{p}\)-statistic, the PRESS statistic, and Predicted \(R^{2}\) (which is calculated from the PRESS statistic). We'll learn about Mallows' \(C_{p}\)-statistic in this section and about the PRESS statistic and Predicted \(R^{2}\) in Section 10.5.
To make matters even worse — the different criteria quantify different aspects of the regression model, and therefore often yield different choices for the best set of predictors. That's okay — as long as we don't misuse best subsets regression by claiming that it yields the best model. Rather, we should use best subsets regression as a screening tool — that is, as a way to reduce a large number of possible regression models to just a handful of models that we can evaluate further before arriving at one final model.
Step #3
Further, evaluate and refine the handful of models identified in the last step. This might entail performing residual analyses, transforming the predictors and/or responses, adding interaction terms, and so on. Do this until you are satisfied that you have found a model that meets the model conditions, does a good job of summarizing the trend in the data, and most importantly allows you to answer your research question.
Example 10-3: Cement Data
For the remainder of this section, we discuss how the criteria identified above can help us reduce a large number of possible regression models to just a handful of models suitable for further evaluation.
For the sake of an example, we will use the cement data to illustrate the use of the criteria. Therefore, let's quickly review — the researchers measured and recorded the following data (Cement data) on 13 batches of cement:
- Response y: heat evolved in calories during the hardening of cement on a per-gram basis
- Predictor \(x_{1}\): % of tricalcium aluminate
- Predictor \(x_{2}\): % of tricalcium silicate
- Predictor \(x_{3}\): % of tetra calcium alumino ferrite
- Predictor \(x_{4}\): % of dicalcium silicate
And, the matrix plot of the data looks like this:
The \(R^{2} \text{-values}\)
As you may recall, the \(R^{2} \text{-value}\), which is defined as:
\(R^2=\dfrac{SSR}{SSTO}=1-\dfrac{SSE}{SSTO}\)
can only increase as more variables are added. Therefore, it makes no sense to define the "best" model as the model with the largest \(R^{2} \text{-value}\). After all, if we did, the model with the largest number of predictors would always win.
All is not lost, however. We can instead use the \(R^{2} \text{-values}\) to find the point where adding more predictors is not worthwhile, because it yields a very small increase in the \(R^{2}\)-value. In other words, we look at the size of the increase in \(R^{2}\), not just its magnitude alone. Because this is such a "wishy-washy" criterion, it is used most often in combination with the other criteria.
Let's see how this criterion works in the cement data example. In doing so, you get your first glimpse of Minitab's best subsets regression output. For Minitab, select Stat > Regression > Regression > Best Subsets to do a best subsets regression.
Best Subsets Regressions: y versus x1, x2, x3, x4
Response is y
Vars | R-Sq | R-Sq | R-Sq | Mallows | S | x | x | x | x |
|---|---|---|---|---|---|---|---|---|---|
1 | 2 | 3 | 4 | ||||||
1 | 67.5 | 64.5 | 56.0 | 138.7 | 8.9639 | X | |||
1 | 66.6 | 63.6 | 55.7 | 142.5 | 9.0771 | X | |||
2 | 97.9 | 97.4 | 96.5 | 2.7 | 2.4063 | X | X | ||
2 | 97.2 | 96.7 | 95.5 | 5.5 | 2.7343 | X | X | ||
3 | 98.2 | 97.6 | 96.9 | 3.0 | 2.3087 | X | X | X | |
3 | 98.2 | 97.6 | 96.7 | 3.0 | 2.3232 | X | X | X | |
4 | 98.2 | 97.4 | 95.9 | 5.0 | 2.4460 | X | X | X | X |
Each row in the table represents information about one of the possible regression models. The first column — labeled Vars — tells us how many predictors are in the model. The last four columns — labeled downward x1, x2, x3, and x4 — tell us which predictors are in the model. If an "X" is present in the column, then that predictor is in the model. Otherwise, it is not. For example, the first row in the table contains information about the model in which \(x_{4}\) is the only predictor, whereas the fourth row contains information about the model in which \(x_{1}\) and \(x_{4}\) are the two predictors in the model. The other five columns — labeled R-sq, R-sq(adj), R-sq(pred), Cp, and S — pertain to the criteria that we use in deciding which models are "best."
As you can see, by default Minitab reports only the two best models for each number of predictors based on the size of the \(R^{2} \text{-value}\) that is, Minitab reports the two one-predictor models with the largest \(R^{2} \text{-values}\), followed by the two two-predictor models with the largest \(R^{2} \text{-values}\), and so on.
So, using the \(R^{2} \text{-value}\) criterion, which model (or models) should we consider for further evaluation? Hmmm — going from the "best" one-predictor model to the "best" two-predictor model, the \(R^{2} \text{-value}\) jumps from 67.5 to 97.9. That is a jump worth making! That is, with such a substantial increase in the \(R^{2} \text{-value}\), one could probably not justify — with a straight face at least — using the one-predictor model over the two-predictor model. Now, should we instead consider the "best" three-predictor model? Probably not! The increase in the \(R^{2} \text{-value}\) is very small — from 97.9 to 98.2 — and therefore, we probably can't justify using the larger three-predictor model over the simpler, smaller two-predictor model. Get it? Based on the \(R^{2} \text{-value}\) criterion, the "best" model is the model with the two predictors \(x_{1}\) and \(x_{2}\).
The adjusted \(R^{2} \text{-value}\) and MSE
The adjusted \(R^{2} \text{-value}\), which is defined as:
\begin{align} R_{a}^{2}&=1-\left(\dfrac{n-1}{n-p}\right)\left(\dfrac{SSE}{SSTO}\right)\\&=1-\left(\dfrac{n-1}{SSTO}\right)MSE\\&=\dfrac{\dfrac{SSTO}{n-1}-\frac{SSE}{n-p}}{\dfrac{SSTO}{n-1}}\end{align}
makes us pay a penalty for adding more predictors to the model. Therefore, we can just use the adjusted \(R^{2} \text{-value}\) outright. That is, according to the adjusted \(R^{2} \text{-value}\) criterion, the best regression model is the one with the largest adjusted \(R^{2}\)-value.
Now, you might have noticed that the adjusted \(R^{2} \text{-value}\) is a function of the mean square error (MSE). And, you may — or may not — recall that MSE is defined as:
\(MSE=\dfrac{SSE}{n-p}=\dfrac{\sum(y_i-\hat{y}_i)^2}{n-p}\)
That is, MSE quantifies how far away our predicted responses are from our observed responses. Naturally, we want this distance to be small. Therefore, according to the MSE criterion, the best regression model is the one with the smallest MSE.
But, aha — the two criteria are equivalent! If you look at the formula again for the adjusted \(R^{2} \text{-value}\):
\(R_{a}^{2}=1-\left(\dfrac{n-1}{SSTO}\right)MSE\)
you can see that the adjusted \(R^{2} \text{-value}\) increases only if MSE decreases. That is, the adjusted \(R^{2} \text{-value}\) and MSE criteria always yield the same "best" models.
Back to the cement data example! One thing to note is that S is the square root of MSE. Therefore, finding the model with the smallest MSE is equivalent to finding the model with the smallest S:
Best Subsets Regressions: y versus x1 ,x2, x3, x4
Response is y
Vars | R-Sq | R-Sq | R-Sq | Mallows | S | x | x | x | x |
|---|---|---|---|---|---|---|---|---|---|
1 | 2 | 3 | 4 | ||||||
1 | 67.5 | 64.5 | 56.0 | 138.7 | 8.9639 | X | |||
1 | 66.6 | 63.6 | 55.7 | 142.5 | 9.0771 | X | |||
2 | 97.9 | 97.4 | 96.5 | 2.7 | 2.4063 | X | X | ||
2 | 97.2 | 96.7 | 95.5 | 5.5 | 2.7343 | X | X | ||
3 | 98.2 | 97.6 | 96.9 | 3.0 | 2.3087 | X | X | X | |
3 | 98.2 | 97.6 | 96.7 | 3.0 | 2.3232 | X | X | X | |
4 | 98.2 | 97.4 | 95.9 | 5.0 | 2.4460 | X | X | X | X |
The model with the largest adjusted \(R^{2} \text{-value}\) (97.6) and the smallest S (2.3087) is the model with the three predictors \(x_{1}\), \(x_{2}\), and \(x_{4}\).
See?! Different criteria can indeed lead us to different "best" models. Based on the \(R^{2} \text{-value}\) criterion, the "best" model is the model with the two predictors \(x_{1}\) and \(x_{2}\). But, based on the adjusted \(R^{2} \text{-value}\) and the smallest MSE criteria, the "best" model is the model with the three predictors \(x_{1}\), \(x_{2}\), and \(x_{4}\).
Mallows' \(C_{p}\)-statistic
Recall that an underspecified model is a model in which important predictors are missing. And, an underspecified model yields biased regression coefficients and biased predictions of the response. Well, in short, Mallows' \(C_{p}\)-statistic estimates the size of the bias that is introduced into the predicted responses by having an underspecified model.
Now, we could just jump right in and be told how to use Mallows' \(C_{p}\)-statistic as a way of choosing a "best" model. But, then it wouldn't make any sense to you — and therefore it wouldn't stick to your craw. So, we'll start by justifying the use of the Mallows' \(C_{p}\)-statistic. The problem is it's kind of complicated. So, be patient, don't be frightened by the scary-looking formulas, and before you know it, we'll get to the moral of the story. Oh, and by the way, in case you're wondering — it's called Mallows' \(C_{p}\)-statistic, because a guy named Mallows thought of it!
Here goes! At issue in any regression model are two things, namely:
- The bias in the predicted responses.
- The variation in the predicted responses.
Bias in predicted responses
Recall that, in fitting a regression model to data, we attempt to estimate the average — or expected value — of the observed responses \(E \left( y_i \right) \) at any given predictor value x. That is, \(E \left( y_i \right) \) is the population regression function. Because the average of the observed responses depends on the value of x, we might also denote this population average or population regression function as \(\mu_{Y|x}\).
Now, if there is no bias in the predicted responses, then the average of the observed responses \(E \left( y_i \right) \) and the average of the predicted responses E(\(\hat{y}_i\)) both equal the thing we are trying to estimate, namely the average of the responses in the population \(\mu_{Y|x}\). On the other hand, if there is bias in the predicted responses, then \(E \left( y_i \right) \) = \(\mu_{Y|x}\) and E(\(\hat{y}_i\)) do not equal each other. The difference between \(E \left( y_i \right) \) and E(\(\hat{y}_i\)) is the bias \(B_i\) in the predicted response. That is, the bias:
\(B_i=E(\hat{y}_i) - E(y_i)\)
We can picture this bias as follows:
The quantity \(E \left( y_i \right) \) is the value of the population regression line at a given x. Recall that we assume that the error terms \(\epsilon_i\) are normally distributed. That's why there is a normal curve — in red — drawn around the population regression line \(E \left( y_i \right) \). You can think of the quantity E(\(\hat{y}_i\)) as being the predicted regression line — well, technically, it's the average of all of the predicted regression lines you could obtain based on your formulated regression model. Again, since we always assume the error terms \(\epsilon_i\) are normally distributed, we've drawn a normal curve — in blue— around the average predicted regression line E(\(\hat{y}_i\)). The difference between the population regression line \(E \left( y_i \right) \) and the average predicted regression line E(\(\hat{y}_i\)) is the bias \(B_i=E(\hat{y}_i)-E(y_i)\) .
Earlier in this lesson, we saw an example in which bias was likely introduced into the predicted responses because of an underspecified model. The data concerned the heights and weights of Martians. The Martian data set — don't laugh — contains the weights (in g), heights (in cm), and amount of daily water consumption (0, 10, or 20 cups per day) of 12 Martians.
If we regress y = weight on the predictors \(x_{1}\) = height and \(x_{2}\) = water, we obtain the following estimated regression equation:
Regression Equation
\(\widehat{weight} = -1.220 + -.28344 height + 0.11121 water\)
But, if we regress y = weight on only the one predictor \(x_{1}\) = height, we obtain the following estimated regression equation:
Regression Equation
\(\widehat{weight} = -4.14 + 0.2889 height\)
A plot of the data containing the two estimated regression equations looks like this:
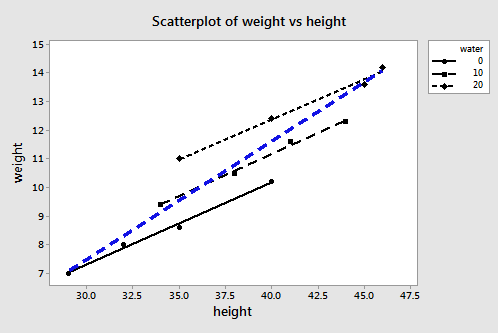
The three black lines represent the estimated regression equation when the amount of water consumption is taken into account — the first line for 0 cups per day, the second line for 10 cups per day, and the third line for 20 cups per day. The dashed blue line represents the estimated regression equation when we leave the amount of water consumed out of the regression model.
As you can see, if we use the blue line to predict the weight of a randomly selected martian, we would consistently overestimate the weight of Martians who drink 0 cups of water a day, and we would consistently underestimate the weight of Martians who drink 20 cups of water a day. That is, our predicted responses would be biased.
Variation in predicted responses
When a bias exists in the predicted responses, the variance in the predicted responses for a data point i is due to two things:
- the ever-present random sampling variation, that is \((\sigma_{\hat{y}_i}^{2})\)
- the variance associated with the bias, that is \((B_{i}^{2})\)
Now, if our regression model is biased, it doesn't make sense to consider the bias at just one data point i. We need to consider the bias that exists for all n data points. Looking at the plot of the two estimated regression equations for the martian data, we see that the predictions for the underspecified model are more biased for certain data points than for others. And, we can't just consider the variation in the predicted responses at one data point i. We need to consider the total variation in the predicted responses.
To quantify the total variation in the predicted responses, we just sum the two variance components — \((\sigma_{\hat{y}_i}^{2})\) and \((B_{i}^{2})\) — over all n data points to obtain a (standardized) measure of the total variation in the predicted responses \(\Gamma_p\) (that's the greek letter "gamma"):
\(\Gamma_p=\dfrac{1}{\sigma^2} \left\{ \sum_{i=1}^{n}\sigma_{\hat{y}_i}^{2}+\sum_{i=1}^{n}\left( E(\hat{y}_i)-E(y_i) \right) ^2 \right\}\)
I warned you about not being overwhelmed by scary-looking formulas! The first term in the brackets quantifies the random sampling variation summed over all n data points, while the second term in the brackets quantifies the amount of bias (squared) summed over all n data points. Because the size of the bias depends on the measurement units used, we divide by \(\sigma^{2}\) to get a standardized unitless measure.
Now, we don't have the tools to prove it, but it can be shown that if there is no bias in the predicted responses — that is, if the bias = 0 — then \(\Gamma_p\) achieves its smallest possible value, namely p, the number of parameters:
\(\Gamma_p=\dfrac{1}{\sigma^2} \left\{ \sum_{i=1}^{n}\sigma_{\hat{y}_i}^{2}+0 \right\} =p\)
Now, because it quantifies the amount of bias and variance in the predicted responses, \(\Gamma_p\) seems to be a good measure of an underspecified model:
\(\Gamma_p=\dfrac{1}{\sigma^2} \left\{ \sum_{i=1}^{n}\sigma_{\hat{y}_i}^{2}+\sum_{i=1}^{n} \left( E(\hat{y}_i)-E(y_i) \right) ^2 \right\}\)
The best model is simply the model with the smallest value of \(\Gamma_p\). We even know that the theoretical minimum of \(\Gamma_p\) is the number of parameters p.
Well, it's not quite that simple — we still have a problem. Did you notice all of those greek parameters — \(\sigma^{2}\), \((\sigma_{\hat{y}_i}^{2})\), and \(\gamma_p\)? As you know, greek parameters are generally used to denote unknown population quantities. That is, we don't or can't know the value of \(\Gamma_p\) — we must estimate it. That's where Mallows' \(C_{p}\)-statistic comes into play!
\(C_{p}\) as an estimate of \(\Gamma_p\)
If we know the population variance \(\sigma^{2}\), we can estimate \(\Gamma_{p}\):
\(C_p=p+\dfrac{(MSE_p-\sigma^2)(n-p)}{\sigma^2}\)
where \(MSE_{p}\) is the mean squared error from fitting the model containing the subset of p-1 predictors (which with the intercept contains p parameters).
But we don't know \(\sigma^{2}\). So, we estimate it using \(MSE_{all}\), the mean squared error obtained from fitting the model containing all of the candidate predictors. That is:
\(C_p=p+\dfrac{(MSE_p-MSE_{all})(n-p)}{MSE_{all}}=\dfrac{SSE_p}{MSE_{all}}-(n-2p)\)
A couple of things to note though. Estimating \(\sigma^{2}\) using \(MSE_{all}\):
- assumes that there are no biases in the full model with all of the predictors, an assumption that may or may not be valid, but can't be tested without additional information (at the very least you have to have all of the important predictors involved)
- guarantees that \(C_{p}\) = p for the full model because in that case \(MSE_{p}\) - \(MSE_{all}\) = 0.
Using the \(C_{p}\) criterion to identify "best" models
Finally — we're getting to the moral of the story! Just a few final facts about Mallows' \(C_{p}\)-statistic will get us on our way. Recalling that p denotes the number of parameters in the model:
- Subset models with small \(C_{p}\) values have a small total (standardized) variance of prediction.
- When the \(C_{p}\) value is ...
- ... near p, the bias is small (next to none)
- ... much greater than p, the bias is substantial
- ... below p, it is due to sampling error; interpret as no bias
- For the largest model containing all of the candidate predictors, \(C_{p}\) = p (always). Therefore, you shouldn't use \(C_{p}\) to evaluate the fullest model.
That all said, here's a reasonable strategy for using \(C_{p}\) to identify "best" models:
- Identify subsets of predictors for which the \(C_{p}\) value is near p (if possible).
- The full model always yields \(C_{p}\)= p, so don't select the full model based on \(C_{p}\).
- If all models, except the full model, yield a large \(C_{p}\) not near p, it suggests some important predictor(s) are missing from the analysis. In this case, we are well-advised to identify the predictors that are missing!
- If several models have \(C_{p}\) near p, choose the model with the smallest \(C_{p}\) value, thereby insuring that the combination of the bias and the variance is at a minimum.
- When more than one model has a small value of \(C_{p}\) value near p, in general, choose the simpler model or the model that meets your research needs.
Example 10-3: Cement Data Continued
Ahhh—an example! Let's see what model the \(C_{p}\) criterion leads us to for the cement data:
Best Subsets Regressions: y versus x1, x2, x3, x4
Response is y
Vars | R-Sq | R-Sq | R-Sq | Mallows | S | x | x | x | x |
|---|---|---|---|---|---|---|---|---|---|
1 | 2 | 3 | 4 | ||||||
1 | 67.5 | 64.5 | 56.0 | 138.7 | 8.9639 | X | |||
1 | 66.6 | 63.6 | 55.7 | 142.5 | 9.0771 | X | |||
2 | 97.9 | 97.4 | 96.5 | 2.7 | 2.4063 | X | X | ||
2 | 97.2 | 96.7 | 95.5 | 5.5 | 2.7343 | X | X | ||
3 | 98.2 | 97.6 | 96.9 | 3.0 | 2.3087 | X | X | X | |
3 | 98.2 | 97.6 | 96.7 | 3.0 | 2.3232 | X | X | X | |
4 | 98.2 | 97.4 | 95.9 | 5.0 | 2.4460 | X | X | X | X |
The first thing you might want to do here is "pencil in" a column to the left of the Vars column. Recall that this column tells us the number of predictors (p-1) that are in the model. But, we need to compare \(C_{p}\) to the number of parameters (p). There is always one more parameter—the intercept parameter—than predictors. So, you might want to add—at least mentally—a column containing the number of parameters—here, 2, 2, 3, 3, 4, 4, and 5.
Here, the model in the third row (containing predictors \(x_{1}\) and \(x_{2}\)), the model in the fifth row (containing predictors \(x_{1}\), \(x_{2}\) and \(x_{4}\)), and the model in the sixth row (containing predictors \(x_{1}\), \(x_{2}\) and \(x_{3}\)) are all unbiased models, because their \(C_{p}\) values equal (or are below) the number of parameters p. For example:
- the model containing the predictors \(x_{1}\) and \(x_{2}\) contains 3 parameters and its \(C_{p}\) value is 2.7. When \(C_{p}\) is less than p, it suggests the model is unbiased;
- the model containing the predictors \(x_{1}\), \(x_{2}\) and \(x_{4}\) contains 4 parameters and its \(C_{p}\) value is 3.0. When \(C_{p}\) is less than p, it suggests the model is unbiased;
- the model containing the predictors \(x_{1}\), \(x_{2}\) and \(x_{3}\) contains 4 parameters and its \(C_{p}\) value is 3.0. When \(C_{p}\) is less than p, it suggests the model is unbiased.
So, in this case, based on the \(C_{p}\) criterion, the researcher has three legitimate models from which to choose with respect to bias. Of these three, the model containing the predictors \(x_{1}\) and \(x_{2}\) has the smallest \(C_{p}\) value, but the \(C_{p}\) values for the other two models are similar and so there is little to separate these models based on this criterion.
Incidentally, you might also want to conclude that the last model — the model containing all four predictors — is a legitimate contender because \(C_{p}\) = 5.0 equals p = 5. Don't forget that the model with all of the predictors is assumed to be unbiased. Therefore, you should not use the \(C_{p}\) criterion as a way of evaluating the fullest model with all of the predictors.
Incidentally, how did Minitab determine that the \(C_{p}\) value for the third model is 2.7, while for the fourth model the \(C_{p}\) value is 5.5? We can verify these calculated \(C_{p}\) values!
The following output was obtained by first regressing y on the predictors \(x_{1}\), \(x_{2}\), \(x_{3}\) and \(x_{4}\) and then by regressing y on the predictors \(x_{1}\) and \(x_{2}\):
Regression Equation
\(\widehat{y} = 62.4 + 1.55 x1 + 0.51 x2 + 0.102 x3 - 0.144 x4\)
Source | DF | SS | MS | F | P |
|---|---|---|---|---|---|
Regression | 4 | 2667.90 | 666.97 | 111.48 | 0.000 |
Residual Error | 8 | 47.86 | 5.98 | ||
Total | 12 | 2715.76 |
Regression Equation
\(\widehat{y} = 52.6 + 1.47 x1 + 0.662 x2\)
Source | DF | SS | MS | F | P |
|---|---|---|---|---|---|
Regression | 2 | 2657.9 | 1328.9 | 229.50 | 0.000 |
Residual Error | 10 | 57.9 | 5.8 | ||
Total | 12 | 2715.8 |
tells us that, here, \(MSE_{all}\) = 5.98 and \(MSE_{p}\) = 5.8. Therefore, just as Minitab claims:
\(C_p=p+\dfrac{(MSE_p-MSE_{all})(n-p)}{MSE_{all}}=3+\dfrac{(5.8-5.98)(13-3)}{5.98}=2.7\)
the \(C_{p}\)-statistic equals 2.7 for the model containing the predictors \(x_{1}\) and \(x_{2}\).
And, the following output is obtained by first regressing y on the predictors \(x_{1}\), \(x_{2}\), \(x_{3}\) and \(x_{4}\) and then by regressing y on the predictors \(x_{1}\) and \(x_{4}\):
Regression Equation
\(\widehat{y} = 62.4 + 1.55 x1 + 0.51 x2 + 0.102 x3 - 0.144 x4\)
Source | DF | SS | MS | F | P |
|---|---|---|---|---|---|
Regression | 4 | 2667.90 | 666.97 | 111.48 | 0.000 |
Residual Error | 8 | 47.86 | 5.98 | ||
Total | 12 | 2715.76 |
Regression Equation
\(\widehat{y} = 103 + 1.44 x1 - 0.614 x4\)
Source | DF | SS | MS | F | P |
|---|---|---|---|---|---|
Regression | 2 | 2641.0 | 1320.5 | 176.63 | 0.000 |
Residual Error | 10 | 74.8 | 7.5 | ||
Total | 12 | 2715.8 |
tells us that, here, \(MSE_{all}\) = 5.98 and \(MSE_{p}\) = 7.5. Therefore, just as Minitab claims:
\(C_p=p+\dfrac{(MSE_p-MSE_{all})(n-p)}{MSE_{all}}=3+\dfrac{(7.5-5.98)(13-3)}{5.98}=5.5\)
the \(C_{p}\)-statistic equals 5.5 for the model containing the predictors \(x_{1}\) and \(x_{4}\).
Try it!
Best subsets regression
When there are four candidate predictors — \(x_1\), \(x_2\), \(x_3\) and \(x_4\) — there are 16 possible regression models to consider. Identify the 16 possible models.
The possible predictor sets and the corresponding models are given below:
Predictor Set | model |
|---|---|
None of \(x_1, x_2, x_3, x_4\) | \(E(Y)=\beta_0\) |
\(x_1\) | \(E(Y)=\beta_0+\beta_1 x_1\) |
\(x_2\) | \(E(Y)=\beta_0+\beta_2 x_2\) |
\(x_3\) | \(E(Y)=\beta_0+\beta_3 x_3\) |
\(x_4\) | \(E(Y)=\beta_0+\beta_4 x_4\) |
\(x_1, x_2\) | \(E(Y)=\beta_0+\beta_1 x_1+\beta_2 x_2\) |
\(x_1, x_3\) | \(E(Y)=\beta_0+\beta_1 x_1+\beta_3 x_3\) |
\(x_1, x_4\) | \(E(Y)=\beta_0+\beta_1 x_1+\beta_4 x_4\) |
\(x_2, x_3\) | \(E(Y)=\beta_0+\beta_2 x_2+\beta_3 x_3\) |
\(x_2, x_4\) | \(E(Y)=\beta_0+\beta_2 x_2+\beta_4 x_4\) |
\(x_3, x_4\) | \(E(Y)=\beta_0+\beta_3 x_3+\beta_4 x_4\) |
\(x_1, x_2,x_3\) | \(E(Y)=\beta_0+\beta_1 x_1+\beta_2 x_2+\beta_3 x_3\) |
\(x_1, x_2,x_4\) | \(E(Y)=\beta_0+\beta_1 x_1+\beta_2 x_2+\beta_4 x_4\) |
\(x_1, x_3,x_4\) | \(E(Y)=\beta_0+\beta_1 x_1+\beta_3 x_3+\beta_4 x_4\) |
\(x_2, x_3,x_4\) | \(E(Y)=\beta_0+\beta_2 x_2+\beta_3 x_3+\beta_4 x_4\) |
\(x_1, x_2,x_3,x_4\) | \(E(Y)=\beta_0+\beta_1 x_1+\beta_2 x_2+\beta_3 x_3+\beta_4 x_4\) |