4.6 - Crossover Designs
4.6 - Crossover DesignsCrossover designs use the same experimental unit for multiple treatments. The common use of this design is where you have subjects (human or animal) on which you want to test a set of drugs -- this is a common situation in clinical trials for examining drugs.
The simplest case is where you only have 2 treatments and you want to give each subject both treatments. Here as with all crossover designs we have to worry about carryover effects.
Here is a timeline of this type of design.
We give the treatment, then we later observe the effects of the treatment. This is followed by a period of time, often called a washout period, to allow any effects to go away or dissipate. This is followed by a second treatment, followed by an equal period of time, then the second observation.
If we only have two treatments, we will want to balance the experiment so that half the subjects get treatment A first, and the other half get treatment B first. For example, if we had 10 subjects we might have half of them get treatment A and the other half get treatment B in the first period. After we assign the first treatment, A or B, and make our observation, we then assign our second treatment.
This situation can be represented as a set of 5, 2 × 2 Latin squares.
We have not randomized these, although you would want to do that, and we do show the third square different from the rest. The row effect is the order of treatment, whether A is done first or second or whether B is done first or second. And the columns are the subjects. So, if we have 10 subjects we could label all 10 of the subjects as we have above, or we could label the subjects 1 and 2 nested in a square. This is similar to the situation where we have replicated Latin squares - in this case five reps of 2 × 2 Latin squares, just as was shown previously in Case 2.
This crossover design has the following AOV table set up:
| AOV | df | df for this example |
| rep = square | \(n - 1\) | 4 |
| column = subject(sq) | \(n(t - 1)\) | 5 |
| row = order | \(t - 1\) | 1 |
| treatment = A vs. B | \(t - 1\) | 1 |
| error | \((t - 1) (nt - 2)\) | 8 |
| Total | \(nt^{2} - 1\) | 19 |
We have five squares and within each square we have two subjects. So we have 4 degrees of freedom among the five squares. We have 5 degrees of freedom representing the difference between the two subjects in each square. If we combine these two, 4 + 5 = 9, which represents the degrees of freedom among the 10 subjects. This representation of the variation is just the partitioning of this variation. The same thing applies in the earlier cases we looked at.
With just two treatments there are only two ways that we can order them. Let's look at a crossover design where t = 3. If t = 3 then there are more than two ways that we can represent the order. The basic building block for the crossover design is the Latin Square.
Here is a 3 × 3 Latin Square. To achieve replicates, this design could be replicated several times.
In this Latin Square we have each treatment occurring in each period. Even though Latin Square guarantees that treatment A occurs once in the first, second and third period, we don't have all sequences represented. It is important to have all sequences represented when doing clinical trials with drugs.
Crossover Design Balanced for Carryover Effects
The following crossover design, is based on two orthogonal Latin squares.
Together, you can see that going down the columns every pairwise sequence occurs twice, AB, BC, CA, AC, BA, CB going down the columns. The combination of these two Latin squares gives us this additional level of balance in the design, than if we had simply taken the standard Latin square and duplicated it.
To do a crossover design, each subject receives each treatment at one time in some order. So, one of its benefits is that you can use each subject as its own control, either as a paired experiment or as a randomized block experiment, the subject serves as a block factor. For each subject we will have each of the treatments applied. The number of periods is the same as the number of treatments. It is just a question about what order you give the treatments. The smallest crossover design which allows you to have each treatment occurring in each period would be a single Latin square.
A 3 × 3 Latin square would allow us to have each treatment occur in each time period. We can also think about period as the order in which the drugs are administered. One sense of balance is simply to be sure that each treatment occurs at least one time in each period. If we add subjects in sets of complete Latin squares then we retain the orthogonality that we have with a single square.
In designs with two orthogonal Latin Squares we have all ordered pairs of treatments occurring twice and only twice throughout the design. Take a look at the video below to get a sense of how this occurs:
All ordered pairs occur an equal number of times in this design. It is balanced in terms of residual effects, or carryover effects.
For an odd number of treatments, e.g. 3, 5, 7, etc., it requires two orthogonal Latin squares in order to achieve this level of balance. For even number of treatments, 4, 6, etc., you can accomplish this with a single square. This form of balance is denoted balanced for carryover (or residual) effects.
Here is an actual data example for a design balanced for carryover effects. In this example the subjects are cows and the treatments are the diets provided for the cows. Using the two Latin squares we have three diets A, B, and C that are given to 6 different cows during three different time periods of six weeks each, after which the weight of the milk production was measured. In between the treatments a wash out period was implemented.
How do we analyze this? If we didn't have our concern for the residual effects then the model for this experiment would be:
\(Y_{ijk}= \mu + \rho _{i}+\beta _{j}+\tau _{k}+e_{ijk}\)
where:
\(\rho_i = \text{period}\)
\(\beta_j = \text{cows}\)
\(\tau_k = \text{treatment}\)
\(i = 1, ..., 3 (\text{the number of treatments})\)
\(j = 1 , .... , 6 (\text{the number of cows})\)
\(k = 1, ..., 3 (\text{the number of treatments})\)
Let's take a look at how this is implemented in Minitab using GLM. Use the viewlet below to walk through an initial analysis of the data (cow_diets.mwx | cow_diets.csv) for this experiment with cow diets.
Why do we use GLM? We do not have observations in all combinations of rows, columns, and treatments since the design is based on the Latin square.
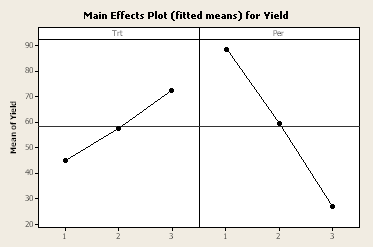
Here is a plot of the least square means for treatment and period. We can see in the table below that the other blocking factor, cow, is also highly significant.
General Linear Model: Yield versus Per, Cow, Trt
| Factor | Type | Levels | Values |
|---|---|---|---|
| Per | fixed | 3 | 1, 2, 3 |
| Cow | fixed | 6 | 1, 2, 3, 4, 5, 6 |
| Trt | fixed | 3 | 1, 2, 3 |
Analysis of Variance for Yield, using Adjusted SS for Tests
| Source | DF | Seq SS | Adj SS | Adj Ms | F | P |
|---|---|---|---|---|---|---|
| Per | 2 | 11480.1 | 11480.1 | 5740.1 | 55.70 | 0.000 |
| Cow | 5 | 5781.1 | 5781.1 | 1156.2 | 11.22 | 0.002 |
| Trt | 2 | 2276.8 | 2276.8 | 1138.4 | 11.05 | 0.005 |
| Error | 8 | 824.4 | 824.4 | 103.1 | ||
| Total | 17 | 20362.4 |
| S = 10.1516 | R-Sq = 95.95% | R-Sq(adj) = 91.40% |
So, let's go one step farther...
Is this an example of Case 2 or Case 3 of the multiple Latin Squares that we had looked at earlier?
This is a Case 2 where the column factor, the cows are nested within the square, but the row factor, period, is the same across squares.
Notice the sum of squares for cows is 5781.1. Let's change the model slightly using the general linear model in Minitab again. Follow along with the video.
Now I want to move from Case 2 to Case 3. Is the period effect in the first square the same as the period effect in the second square? If it only means order and all the cows start lactating at the same time it might mean the same. But if some of the cows are done in the spring and others are done in the fall or summer, then the period effect has more meaning than simply the order. Although this represents order it may also involve other effects you need to be aware of this. A Case 3 approach involves estimating separate period effects within each square.
My guess is that they all started the experiment at the same time - in this case, the first model would have been appropriate.
How Do We Analyze Carryover Effect?
OK, we are looking at the main treatment effects. With our first cow, during the first period, we give it a treatment or diet and we measure the yield. Obviously, you don't have any carryover effects here because it is the first period. However, what if the treatment they were first given was a really bad treatment? In fact in this experiment the diet A consisted of only roughage, so, the cow's health might in fact deteriorate as a result of this treatment. This could carry over into the next period. This carryover would hurt the second treatment if the washout period isn't long enough. The measurement at this point is a direct reflection of treatment B but may also have some influence from the previous treatment, treatment A.
If you look at how we have coded data here, we have another column called residual treatment. For the first six observations, we have just assigned this a value of 0 because there is no residual treatment. But for the first observation in the second row, we have labeled this with a value of one indicating that this was the treatment prior to the current treatment (treatment A). In this way the data is coded such that this column indicates the treatment given in the prior period for that cow.
Now we have another factor that we can put in our model. Let's take a look at how this looks in Minitab:
We have learned everything we need to learn. We have the appropriate analysis of variance here. By fitting in order, when residual treatment (i.e., ResTrt) was fit last we get:
SS(treatment | period, cow) = 2276.8
SS(ResTrt | period, cow, treatment) = 616.2
When we flip the order of our treatment and residual treatment, we get the sums of squares due to fitting residual treatment after adjusting for period and cow:
SS(ResTrt | period, cow) = 38.4
SS(treatment | period, cow, ResTrt) = 2854.6
Which of these are we interested in? If we wanted to test for residual treatment effects how would we do that? What would we use to test for treatment effects if we wanted to remove any carryover effects?