Lesson 7: Confounding and Blocking in \(2^k\) Factorial Designs
Lesson 7: Confounding and Blocking in \(2^k\) Factorial DesignsOverview
In Lesson 4 we discussed blocking as a method for removing extraneous sources of variation. In this lesson, we consider blocking in the context of \(2^k\) designs. We will then make a connection to confounding, and show a surprising application of confounding where it is beneficial rather than a liability.
Objectives
- Concept of Confounding
- Blocking of replicated \(2^k\) factorial designs
- Confounding high order interaction effects of the \(2^k\) factorial design in \(2^p\) blocks
- How to choose the effects to be confounded with blocks
- That a \(2^k\) design with a confounded main effect is actually a Split Plot design
- The concept of Partial Confounding and its importance for retrieving information on every interaction effect
Blocking in Replicated Designs
In \(2^k\) replicated designs where we have n replications per cell and perform a completely randomized design we randomly assign all \(2^k\) times n experimental units to the \(2^k\) treatment combinations. Alternatively, when we have n replicates we can use these n replicates as blocks, and assign the \(2^k\) treatments to the experimental units within each of the n blocks. If we are going to replicate the experiment anyway, at almost no additional cost, you can block the experiment, doing one replicate first, then the second replicate, etc. rather than completely randomize the n times \(2^k\) treatment combinations to all the runs.
There is almost always an advantage to blocking when we replicate the treatments. This is true even if we only block using time due to the order of the replicates. However, there are often many other factors that we have available as potential sources of variation that we can include as a block factor, such as batches of material, technician, day of the week, or time of day, or other environmental factors. Thus if we can afford to replicate the design then it is almost always useful to block.
To give a simple example, if we have four factors, the \(2^k\) design has 16 treatment combinations, so say we plan to do just two replicates of the design. Without blocking, the ANOVA has \(2^4 = 16\) treatments, but with n = 2 replicates, the MSE would have 16 degrees of freedom. If we included a block factor, with two levels, the ANOVA would use one of these 16 degrees of freedom for the block, leaving 15 degrees of freedom for MSE. Hence the statistical cost of blocking is really the loss of one degree of freedom for error, and the potential gain if the block explains significant variation would be to reduce the size of the MSE and thereby increase the power of the tests.
The more interesting case that we will consider next is when we have an unreplicated design. If we are only planning to do one replicate, can we still benefit from the advantage ascribed to blocking our experiment?
7.1 - Blocking in an Unreplicated Design
7.1 - Blocking in an Unreplicated DesignWe begin with a very simple replicated example of blocking. Here we have \(2^2\) treatments and we have n = 3 blocks. In the graphic below the treatments are labeled using the standard Yates notation. Here the \(2^2\) treatments are the full set of treatment combinations so we can simply put each replicate within a block and assign them in this way.
We can use the Minitab software to construct this design as seen in the video below.
Now let’s consider the case when we don't have any replicates, hence when we only have one set of treatment combinations. We go back to the definition of effects that we defined before. We did this using following table, where {(1), a, b, ab} is the set of treatment combinations, and A, B, and AB are the effect contrasts:
| trt | A | B | AB |
|---|---|---|---|
| (1) |
-1
|
-1
|
1
|
| a |
1
|
-1
|
-1
|
| b |
-1
|
1
|
-1
|
| ab |
1
|
1
|
1
|
The question is: what if we want to block this experiment? Or, more to the point, when it is necessary to use blocks, how would we block this experiment?
If our block size is less than four we are only going to consider, in this context of \(2^k\) treatments, block sizes in the same family, i.e. \(2^p\) number of blocks. So in the case of this example let's use blocks of size 2, which is \(2^1\). If we have blocks of size two then we must put two treatments in each block. One example would be twin studies where you have two sheep from each ewe. The twins would have homogeneous genetics and the block size would be two for the two animals. Another example might be two-color micro-arrays where you have only two colors in each micro-array.
So now the question: How do we assign our four treatments to our blocks of size two?
In our example each block will be composed of two treatments. The usual rule is to pick an effect you are least interested in, and this is usually the highest order interaction, as a means of specifying how to do blocking. In this case it is the AB effect that we will use to determine our blocks. As you can see in the table below we have used the high level of AB to denote Block 1, and the low-level of AB to denote Block 2. This determines our design.
| trt | A | B | AB | Block |
|---|---|---|---|---|
| (1) |
-1
|
-1
|
1
|
1
|
| a |
1
|
-1
|
-1
|
2
|
| b |
-1
|
1
|
-1
|
2
|
| ab |
1
|
1
|
1
|
1
|
Now, using this design we can assign treatments to blocks. In this case treatment (1) and treatment ab will be in the first block, and treatment a and treatment b will be in the second block.
Blocks of size 2
| Block | 1 | 2 |
|---|---|---|
| AB | + | - |
|
(1)
|
a
|
|
|
ab
|
b
|
This design confounds blocks with the AB interaction. You can see this by these contrasts - the comparison between block 1 and Block 2 is the same comparison as the AB contrast. Note that the A effect and the B effect are orthogonal to the AB effect. This design gives you complete information on the A and the B main effects, but it totally confounds the AB interaction effect with the block effect.
Although our block size is fixed at size = 2 we still might want to replicate this experiment in addition. What we have above is two blocks which is one unit of the experiment. We could replicate this design additionally let's say r times and each replicate of the design would be 2 blocks of the design laid out in this way.
We show how to construct this with four replicates. Review the movie below to see how this occurs in Minitab.
7.2 - The \(2^3\) Design
7.2 - The \(2^3\) DesignLet's look now at the \(2^3\) design. Here we have 8 treatments and we could create designs with blocks of size \(2^p\) - which could either be blocks of size 4 or 2. As before, we can write this out in a table as:
| trt | I | A | B | C | AB | AC | BC | ABC |
|---|---|---|---|---|---|---|---|---|
| (1) | + | - | - | - | + | + | + | - |
| a | + | + | - | - | - | - | + | + |
| b | + | - | + | - | - | + | - | + |
| ab | + | + | + | - | + | - | - | - |
| c | + | - | - | + | + | - | - | + |
| ac | + | + | - | + | - | + | - | - |
| bc | + | - | + | + | - | - | + | - |
| abc | + | + | + | + | + | + | + | + |
In the table above we have defined our seven effects: three main effects {A, B, C}, three 2-way interaction effects {AB, AC, BC}, and one 3-way interaction effect {ABC}. We need to define our blocks next by selecting an effect that we are willing to give up by confounding it within the blocks. Let's first look at an example where we let the block size = 4.
Now we need to ask ourselves, what is typically the least interesting effect? The highest order interaction. Do we will use the contrast of the highest order interaction, the three-way, as the effect to guide the layout of our blocks.
| trt | I | A | B | C | AB | AC | BC | ABC | Block |
|---|---|---|---|---|---|---|---|---|---|
| (1) | + | - | - | - | + | + | + | - | 1 |
| a | + | + | - | - | - | - | + | + | 2 |
| b | + | - | + | - | - | + | - | + | 2 |
| ab | + | + | + | - | + | - | - | - | 1 |
| c | + | - | - | + | + | - | - | + | 2 |
| ac | + | + | - | + | - | + | - | - | 1 |
| bc | + | - | + | + | - | - | + | - | 1 |
| abc | + | + | + | + | + | + | + | + | 2 |
Under the ABC column, the - values will be placed in Block 1, and the + values will be placed in Block 2. Thus we can layout the design by defining the two blocks of four observations like this:
| Block | 1 | 2 |
|---|---|---|
| ABC | - | + |
| (1) | a | |
| ab | b | |
| ac | c | |
| bc | abc |
Let's take a look at how Minitab would run this process ...
What if we have \(2^3\) treatments but we want the block size to be 2?
Now for each replicate we need four blocks with only two treatments per block.
Thought Questions: How should we assign our treatments? How many and which effects must you select to confound with the four blocks?
To define the design for four blocks we need to select two effects to confound, and then we will get four combinations of those two effects.
What if we first select ABC as one of the effects? Then, it would seem logical to pick one of the 2-way interactions as the other confounding factor. Let's say we use AB. If we do this, remember, we also confound the interaction between these two effects. What is the interaction between ABC and AB. It is C. We can see this by multiplying the elements in the columns for ABC and AB. Try it and you get the same coefficients as you have in the column for C. This is called the generalized interaction. Although it intuitively seemed as though ABC and AB would be a good choice, it is not because it also confounds the main effect C.
Another choice would be to pick two of the 2-way interactions such as AB and AC. The interaction of these is BC. In this case you have not confounded a main effect, but instead have confounded the three two-way interactions. The four combinations of the AB and AC interactions define the four blocks as seen in this color coded table.
| trt | I | A | B | C | AB | AC | BC | ABC | Block |
|---|---|---|---|---|---|---|---|---|---|
| (1) | + | - | - | - | + | + | + | - | 4 |
| a | + | + | - | - | - | - | + | + | 1 |
| b | + | - | + | - | - | + | - | + | 3 |
| ab | + | + | + | - | + | - | - | - | 2 |
| c | + | - | - | + | + | - | - | + | 2 |
| ac | + | + | - | + | - | + | - | - | 3 |
| bc | + | - | + | + | - | - | + | - | 1 |
| abc | + | + | + | + | + | + | + | + | 4 |
Look under the AB and the AC columns. Where there are - values for both AB and AC these treatments will be placed in Block 1. Where there is a + value for AB and a - value for AC these treatments will be placed in Block 2. Where there is a - value for AB and a + value for AC these treatments will be placed in Block 3. And finally, where there are + values for both AB and AC these treatments will be placed in Block 4. From here we can layout the design separating the four blocks of two observations like this:
| Block | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| AB, AC | -, - | +, - | -, + | +, + |
| a | ab | b | (1) | |
| bc | c | ac | abc |
Let's take a look at how Minitab would run this process ...
For the \(2^3\) design the only two possibilities are either block sizes of two or four. When we look at more than eight treatments or \(2^3\), then we have more combinations possible. We typically want to confound the highest order of interaction possible remembering that all generalized interactions are also confounded. This is a property of the geometry of designs.
In the next lesson we will look at how we can analyze the data if we take replications of these basic designs, considering one replicate as just the basic building block. This is typically determined by the fact that the block size is usually imposed by some cost or size restrictions on the experiment. However, given adequate resources you can replicate that whole experiment multiple times. So then the question becomes how to analyze these designs and how do we pull out the treatment information.
7.3 - Blocking in Replicated Designs
7.3 - Blocking in Replicated DesignsIn the previous section, we saw a \(2^2\) treatment design with 4 runs constructed in two blocks confounded with the AB contrast. We also saw a \(2^3\) design constructed in two blocks, with ABC confounded with blocks. We say this is a \(2^3\) design in \(2^1\) blocks of size \(2^2\) per replicate. And we also saw a \(2^3\) design in \(2^2 = 4\) blocks of size \(2^1 = 2\) per replicate with effects AB, AC, and therefore \(AB \times AC = A^{2}BC = BC\) confounded with blocks.
Now let’s consider this last situation when we have \(n = 3\) replicates of this basic design with \(b = 4\) blocks. We can write a model:
\(Y_{ijklm}= \mu+r_{i}+b_{j(i)}+\alpha_{k}+\beta_{l}+\gamma_{m}+...\)
where “i” is the index for replicates and “j” is the index for blocks within the replicates. “k”, “l” and “m” are indices for the different treatment factors.
| AOV | df | |
|---|---|---|
| Rep | n-1 | = 3 - 1 = 2 |
| Blk(Rep) | n(b - 1) | = 3(4 - 1) = 9 |
| A | 2 - 1 | 1 |
| B | 2 - 1 | 1 |
| C | 2 - 1 | 1 |
| ABC | 2 - 1 | 1 |
| Error | (n - 1)*4 | 8 |
| Total | \(n*2^{3} - 1\) | 23 |
Now we consider another example: in figure 7.3 of the text we see four replicates with ABC confounded in each of the four replicates. The ANOVA for this design is seen in table 7.5 which shows that the Block effect (Block 1 vs. Block 2) is equivalent to the ABC effect and since there are four replicates of this basic design, we can extract some information about the ABC effect, and indeed test the hypothesis of no ABC effect, by using the Rep × ABC interaction as error.
See the analysis of this design using Minitab:
Stat > ANOVA > General Linear Model
and fitting the following model:
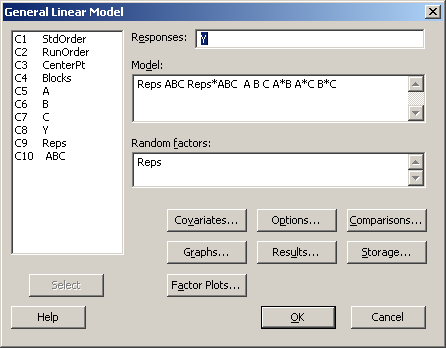
If Reps is specified as a random effects factor in the model, as above, GLM will produce the correct F-tests based on the Expected Means Squares. The reason is analogous to the RCBD with random blocks (Reps) and a fixed treatment (ABC). The topic of random factors is completely covered in chapter 13 of the text book
For Minitab Stat > ANOVA > GLM to analyze this data, you need to first construct a pseudo-factor called "ABC" which is constructed by multiplying the levels of A, B, and C using 'Calculator' under the 'Data' menu in Minitab. Click on the 'Inspect' button below which will walk you through this process using Minitab v.16.
In addition you can open this Minitab project file 2-k-confound-ABC.mpx and review the steps leading to the output. The response variable Y is random data simply to illustrate the analysis.
Here is an alternative way to analyze this design using the analysis portion of the fractional factorial software in Minitab v.16.
A similar exercise can be done to illustrate the confounded situation where the main effect, say A, is confounded with blocks. Again, since this is a bit nonstandard, we will need to generate a design in Minitab using the default settings and then edit the worksheet to create the confounding we desire and analyze it in GLM.
7.4 - Split-Plot Example – Confounding a Main Effect with blocks
7.4 - Split-Plot Example – Confounding a Main Effect with blocksLet us consider three replicates, and at each replicate we have two large fields. A diagram of this would look like this:
We will randomly assign the low (-1) or high (+1) level of factor A to each of the two fields. In our example A = +1 is irrigation, and A = -1 is no irrigation. We will randomly assign the levels of A to the two fields in each replicate. Then the experiment layout would look like this for one replicate:
Similar to the previous example, we would then assigned the treatment combinations of factors B and C to the four experimental units in each block. We could call these experimental units plots -- or using the language of split plot designs -- the blocks are whole plots and the subplots are split plots.
The analysis of variance is similar to what we saw in the example above except we now have A rather than ABC confounded with blocks.
See the Minitab project file 2-K-Split-Plota.mpx as an example. In addition, here is a viewlet that will walk you through this example using Minitab v.16.
7.5 - Blocking in \(2^k\) Factorial Designs
7.5 - Blocking in \(2^k\) Factorial DesignsNow we will generalize what we have shown by example. We will look at \(2^k\) designs in \(2^p\) blocks of size \(2^{k-p}\). We do this by choosing k and if we want to confound the design in \(2^p\) blocks then we need to choose p effects to confound. Then, due to the intereactions among these effects, we get \(2^{p}-1\) effects confounded with blocks.
To illustrate this, if \(p= 2\) then we have \(2^{p} = \text{four blocks}\), and thus \(2^{p} - 1 = 3\) effects confounded, i.e., the 2 effects we chose plus the interaction between these two. In general, we choose p effects and in addition to the p effects we choose, \(2^{p} - p - 1\) other effects are automatically confounded. We will call these "generalized interactions" which are also confounded.
Earlier we looked at a couple of examples - for instance when \(k = 3\) and \(p = 2\). We chose ABC and AB. Then the \(ABC \times AB = A^{2} B^{2} C = C\) which was also confounded. This shows that the generalized interaction can be a main effect, i.e. the generalized interaction affect can be a lower order term. This is not a good outcome. A better outcome that we settled on was to pick two 2-way interactions, AB and AC, which gave us \(AB \times AC = A^{2}BC \text{which} = BC\), another 2-way interaction. In this case we have all three 2-way interactions confounded, but all the main effects were estimable.
7.6 - Example 1
7.6 - Example 1Example 7.1
Let's take another example where \(k = 4\), and \(p = 2\). This is one step up in the number of treatment factors. And now we have block size \(= 2^{4 - 2}\) or 4. Again, we have to choose two effects to confound. We will show three cases to illustrate this.
- Let's try ABCD and a 3-way, ABC. This implies \(ABCD \times ABC = A^{2}B^{2}C^{2}D = D\) is also confounded. We usually do not want to confound a main effect. It seems that if you reach too far then you fall short. So, the question is: what is the right compromise?
- We could try ABCD and just AB. In this case we get \(ABCD \times AB = A^{2}B^{2}CD = CD\). Here we have the 4-way interaction and just two of the 2-way interactions confounded. Can we do better than this? Do you know that one or more of your 2-way interaction effects are not important? This is something you probably don't know, but you might. In this case you could pick this interaction and very carefully assign treatments based on this knowledge.
- One more try. How about confounding two 3-way interactions? What if we use ABC and BCD. This would give us the interactions of those, \(ABC \times BCD = AB^{2}C^{2}D \text{which} = AD\).
Which of these three attempts is better? The first try (a) is definitely not good because it confounds the main effect. So, which of the second or third do you prefer? The third (c) is probably the best because it has the fewest lower order interactions confounded. Generally, it is assumed that the higher order interactions are less important, so this makes the (c) case the best choice. Both cases (b) and (c) confound 2-way interactions but the (b) case confounds two of them and the (c) case only one.
If we look at Minitab the program defaults are always set to choose the best of these options. Use this short viewlet to see how Minitab v.17 selects these:
7.7 - Example 2
7.7 - Example 2Example 7.2
Let's try an example where \(k = 5\), and \(p = 2\).
a. If we choose to confound two 4-way interactions ABCD and BCDE, this would give us \(ABCD \times BCDE = AB^{2}C^{2}D^{2}E = AE\), confounded as well, which is a 2-way interaction. Not so good.
If we choose ABC and CDE, this would give us \(ABC \times CDE = ABC^{2}DE = ABDE\). So, with this choice we are confounding the higher level 4-way interaction and two 3-way interactions instead of the 2-way interaction as above.
Let's see what Minitab chooses...
If you were planning to replicate one of these designs, you would not need to use the same three factors for blocking in each replicate of the design, but instead could choose a different set of effects to use for each replicate of the experiment. More on that later.
7.8 - Alternative Method for Assigning Treatments to Blocks
7.8 - Alternative Method for Assigning Treatments to BlocksWe began this section by looking at the +'s and -'s that were assigned by looking at whether the treatment level was high or low. And in our simplest example we looked at our contrast as +1's and -1's and used these to determine which treatments were assigned to which blocks.
An alternative to using the -'s and +'s is to use 0 and 1. In this case, the low level is 0 and the high level is 1. You can think of this method as just another finite math procedure that can be used to determine which treatments go in which block. We introduce this here because as we will see later, this alternative method generalizes to designs with more than two levels.
Here is a \(2^3\) design using this notation:
| \(X_3\) | \(X_2\) | \(X_1\) | ||||
|---|---|---|---|---|---|---|
| \(L_{ABC}\) | \(L_{BC}\) | \(L_{AC}\) | \(L_{AB}\) | C | B | A |
| 0 | 0 | 0 | 0 | 0 | ||
| 1 | 1 | 0 | 0 | 1 | ||
| 0 | 1 | 0 | 1 | 0 | ||
| 1 | 0 | 0 | 1 | 1 | ||
| 1 | 0 | 1 | 0 | 0 | ||
| 0 | 1 | 1 | 0 | 1 | ||
| 1 | 1 | 1 | 1 | 0 | ||
| 0 | 0 | 1 | 1 | 1 |
Defining Contrasts
\(L_{AB}=X_{1}+X_{2}\ (mod\ 2)\)
\(L_{AC}=X_{1}+X_{3}\ (mod\ 2)\)
\(L_{BC}=X_{2}+X_{3}\ (mod\ 2)\)
\(L_{ABC}=X_{1}+X_{2}+X_{3}\ (mod\ 2)\)
If you look at \(L_{AB}\) all we are doing here is just summing the 0 and 1 combinations, therefore, \(L_{AB}=\) the sum of the row of 0's and 1's for \(AB\) (in blue for the first row only). What we are doing is defining the linear combinations using modular 2 arithmetic in this way.
If we want to construct a design for \(k = 3\), \(p = 2\) by choosing \(AB\) and \(AC\) as our defining contrasts then we would construct our design in the following manner:
| 4 | 3 | 2 | 1 | Block |
|---|---|---|---|---|
| 1, 1 | 0, 1 | 1, 0 | 0, 0 | \(L_{AB}\), \(L_{Ac}\) |
| a | ab | b | (1) | |
| bc | c | ac | abc |
We are using \(L_{AB}\) and \(L_{AC}\) to define our blocks, so, what we need to do is exactly what we did before, but this time we are using the 0's and 1's to determine the layout for the design. We are simply using a different coding mechanism here for determining the design layout.
Why is this important?
For two level designs both methods work the same. You can either use the +'s and -'s as the two levels of the factor to divide the treatment combinations into blocks, or you can use zero and one, which is simply a different way to do this and gives us a chance to define the contrasts where:
\(L=a_{1}X_{1}+a_{2}X_{2}+a_{3}X_{3}\ (mod\ 2)\)
where \(a_{i}\) is the exponent of the ith factor in the effect to be confounded (either a 0 or a 1 in each case) and Xi is the level of the ith factor appearing in a particular treatment combination.
Both approaches will give us the same set of treatment combinations in blocks. These functions translate the levels of \(A\) and \(B\) to the levels of the \(AB\) interaction.
When we get to designs with more than two levels using +'s and -'s doesn't work. Therefore, we need another method and using this 1's and 0's approach generalizes. We will come back to this method when we look at 3 level designs - but we will get to that later in Lesson 9.
Partial Confounding
In the above designs, we had to select one or more effects that we were willing to confound with blocks, and therefore not be able to estimate. Generally, we should have some prior knowledge about which effects to neglect or which effects are zero. Even if we do replicate a blocked factorial design, we would not be able to obtain good intra-block estimates the effect(s) which are confounded with blocks. To avoid this issue, there is a method of confounding called partial confounding which is widely used.
In partial confounding, the experimenter uses a different interaction effect to be confounded with blocks throughout different replicates. In this way, information regarding each interaction effect which is confounded in one of the replicates can be retrieved from the remaining replicates. Figure 7.7 in the text book shows a partial confounding of \(2^3\) design where \(ABC\), \(AB\), \(BC\) and \(AC\) are confounded with blocks in the first through fourth replicates, respectively. Since each interaction is unconfounded in three-quarters of replicates, \(\frac{3}{4}\) is the relative information for the confounded effects. The analysis is shown in Table 7.10. Example 7.3 in the text book illustrates a \(2^3\) design with partial confounding.