Even though this is an applied course on data mining and the focus is on data analysis by application of software and interpretation of results, familiarity of mathematical underpinings help to understand the applicability and limitations of the methods. Computational techniques have given data mining unprecedented power, but,at the same time, they have increased the chances of blindly applying any technique to any situation, without paying heed to its applicability. The analytical insight does not come with any software application; a software application enhances analytical insight. Blind application of software on a large number of records will not necessarily provide insight into the data; rather it is possible that in the mire of information all grains of truth will be inextricably lost.
Let us start with an overview of the data mining techniques that are going to be considered in this course. The focus is on the problem of Prediction. This is by no means the only problem that data mining can deal with. There are many other topics outside the scope of the current course. Data mining is multi-disciplinary and encompasses methods dealing with scaling up for high-dimensional data and high-speed data streams, distributed data mining, mining in a network setting and many other facets. Within this course our focus is on Statistical Learning and Prediction.
The diagram here presents the main aspects of a statistical learning model.
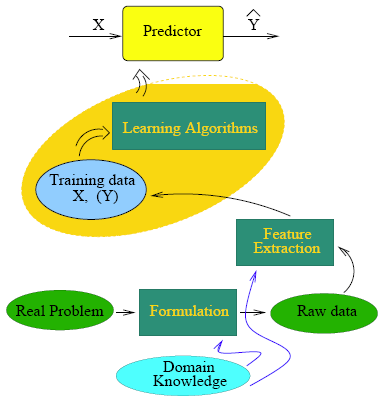 In a learning (prediction) problem, there exists a set of features (X) and a response (Y). X is usually a vector. For the purpose of the course, Y is a real number, which is either a quantitative variable or a label for a categorical variable.The predictor is a mathematical function (f) that maps X to Y.
In a learning (prediction) problem, there exists a set of features (X) and a response (Y). X is usually a vector. For the purpose of the course, Y is a real number, which is either a quantitative variable or a label for a categorical variable.The predictor is a mathematical function (f) that maps X to Y.
The problem is how to find the function f?
There may be different approaches to solve this problem. For instance, researchers in medical domains form their prediction functions based on individual expertise and domain knowledge. Physicians ask their patients about the symptoms, and then based on their experience they will identify the disease.
Such a problem of human prediction function is not of interest in this course. We are interested in studying predictors generated by learning algorithms.
The approach considered in this course is purely data-driven.The first step in any model-building process is to understand the data, which can be done graphically or analytically. When data is complex an amalgamation of both visual and analytical process gives the best result. This step is often called the EDA or Exploratoy Data Analysis. The second step is to build and evaluate a model (or a set of candidate models) on the data. A standard approach is to take a random sample of the data for model building and use the rest of the data to evaluate the model performance. The part of sample that is used to build a model is called the Training Sample (training set or training data) and the other part, the Test Sample (test set or test data). The training sample is used to develop the relationship between X and Y and model parameters are estimated based on this data. The test sample is used only when one model among a few strong candidate models is finalized. Repeatedly using the test sample in the model building process negates its utility as a final arbitrator of the model.
The learning algorithms explore the given data set and extract a relationship between X and Y. The output of the learning algorithms is a function mapping X to Y. This is known as Supervised Learning algorithm. In Unsupervised Learning algorithms the response Y is not known or not considered in developing the algorithm.
At face value model building appears straightforward. Once the data is available, with the help of software, several techniques are applied in the training data and one final model emerges after looking at its performance in the test data. However to achieve a reliable and trustworthy predictive model, understanding of the features in the data and the objective of modeling is essential. In fact reality is often complicated and formulation of a practical problem into a data mining problem may be the real challenge. Sometimes only raw data is provided for analysis. In other cases researchers have the freedom to collect the data. Collection of relevant data is costly and requires domain knowledge. Between the raw data and model building there is a data simplification step that may be known as feature extraction. Very often the raw data is not easy to handle or there are layers of hidden information which will have to be revealed before it is submitted to a learning algorithm.