8.3 - Two Separate Advantages
Perhaps somewhere along the way in our most recent discussion, you thought "why not just fit two separate regression functions — one for the smokers and one for the non-smokers?" (If you didn't think of it, I thought of it for you!) Are there advantages to including both the binary and quantitative predictor variables within one multiple regression model? The answer is yes! In this section, we explore the two primary advantages.
The first advantage
An easy way of discovering the first advantage is to analyze the data three times — once using the data on all 32 subjects, once using the data on only the 16 non-smokers, and once using the data on only the 16 smokers. Then, we can investigate the effects of the different analyses on important things such as sizes of standard errors of the coefficients and the widths of confidence intervals. Let's try it!
Here's statistical software output for the analysis using a (0,1) indicator variable and the data on all 32 subjects. Let's just run through the output and collect information on various values obtained:
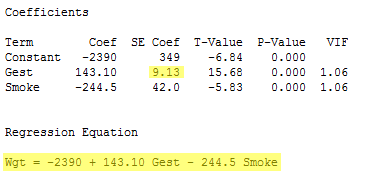
The standard error of the Gest coefficient is 9.13. Recall that this value quantifies how much the estimated Gest coefficient would vary from sample to sample. And, the following output:
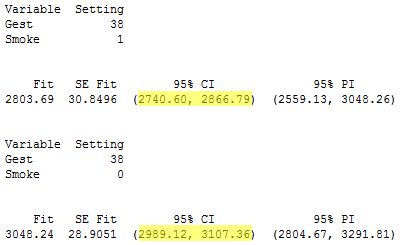
tells us that for mothers with a 38-week gestation, the width of the confidence interval for the mean birth weight is 126.2 for smoking mothers and 118.2 for non-smoking mothers.
Let's do that again, but this time for the output on just the 16 non-smoking mothers:
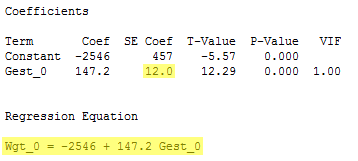
The standard error of the Gest coefficient is 12.0. And:
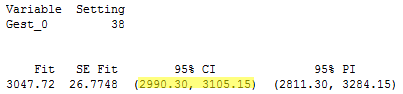
for non-smoking mothers with a 38-week gestation, the width of the confidence interval for the mean birth weight is 114.9.
And, let's do the same thing one more time for the output on just the 16 smoking mothers:
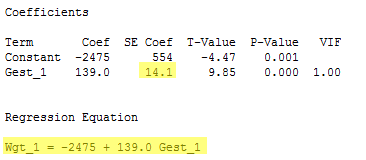
The standard error of the Gest coefficient is 14.1. And:
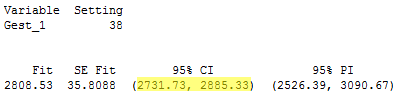
for smoking mothers with a 38-week gestation, the length of the confidence interval is 153.6.
Here's a summary of what we've gleaned from the three pieces of output:
| Model estimated using… |
SE(Gest)
|
Width of CI for μY |
| all 32 data points |
9.13
|
(NS) 118.2
(S) 126.2 |
| 16 nonsmokers |
12.0
|
114.9
|
| 16 smokers |
14.1
|
153.6
|
Let's see what we learn from this investigation:
- The standard error of the Gest coefficient — SE(Gest) — is smallest for the estimated model based on all 32 data points. Therefore, confidence intervals for the Gest coefficient will be narrower if calculated using the analysis based on all 32 data points. (This is a good thing!)
- The width of the confidence interval for the mean weight of babies born to smoking mothers is narrower for the estimated model based on all 32 data points (126.2 compared to 153.6), and not substantially different for non-smoking mothers (118.2 compared to 114.9). (Another good thing!)
In short, there appears to be an advantage in "pooling" and analyzing the data all at once rather than breaking it apart and conducting different analyses for each group. Our regression model assumes that the slope for the two groups are equal. It also assumes that the variances of the error terms are equal. Therefore, it makes sense to use as much data as possible to estimate these quantities.
The second advantage
An easy way of discovering the second advantage of fitting one "combined" regression function using all of the data is to consider how you'd answer the research question if you broke apart the data and conducted two separate analyses obtaining:
Nonsmokers
Smokers
How could you use these results to determine if the mean birth weight of babies differs between smoking and non-smoking mothers, after taking into account length of gestation? Not completely obvious, is it?! It actually could be done with much more (complicated) work than would be necessary if you analyze the data as a whole and fit one combined regression function:
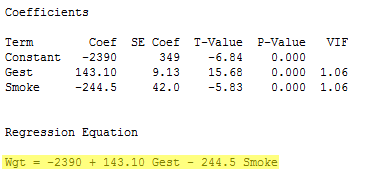
As we previously discussed, answering the research question merely involves testing the null hypothesis H0 : β2 = 0 against the alternative HA : β2 ≠ 0. The P-value is < 0.001. There is sufficient evidence to conclude that there is a statistically significant difference in the mean birth weight of all babies of smoking mothers and the mean birth weight of all babies of non-smoking mothers, after taking into account length of gestation.
In summary, "pooling" your data and fitting one combined regression function allows you to easily and efficiently answer research questions concerning the binary predictor variable.

