Lesson 4: Blocking
Lesson 4: BlockingOverview
Blocking factors and nuisance factors provide the mechanism for explaining and controlling variation among the experimental units from sources that are not of interest to you and therefore are part of the error or noise aspect of the analysis. Block designs help maintain internal validity, by reducing the possibility that the observed effects are due to a confounding factor, while maintaining external validity by allowing the investigator to use less stringent restrictions on the sampling population.
The single design we looked at so far is the completely randomized design (CRD) where we only have a single factor. In the CRD setting we simply randomly assign the treatments to the available experimental units in our experiment.
When we have a single blocking factor available for our experiment we will try to utilize a randomized complete block design (RCBD). We also consider extensions when more than a single blocking factor exists which takes us to Latin Squares and their generalizations. When we can utilize these ideal designs, which have nice simple structure, the analysis is still very simple, and the designs are quite efficient in terms of power and reducing the error variation.
Objectives
- Concept of Blocking in Design of Experiment
- Dealing with missing data cases in Randomized Complete Block Design
- Application of Latin Square Designs in presence of two nuisance factors
- Application of Graeco-Latin Square Design in presence of three blocking factor sources of variation
- Crossover Designs and their special clinical applications
- Balanced Incomplete Block Designs (BIBD)
4.1 - Blocking Scenarios
4.1 - Blocking ScenariosTo compare the results from the RCBD, we take a look at the table below. What we did here was use the one-way analysis of variance instead of the two-way to illustrate what might have occurred if we had not blocked, if we had ignored the variation due to the different specimens. Blocking is a technique for dealing with nuisance factors.
A nuisance factor is a factor that has some effect on the response, but is of no interest to the experimenter; however, the variability it transmits to the response needs to be minimized or explained. We will talk about treatment factors, which we are interested in, and blocking factors, which we are not interested in. We will try to account for these nuisance factors in our model and analysis.
Typical nuisance factors include batches of raw material if you are in a production situation, different operators, nurses or subjects in studies, the pieces of test equipment, when studying a process, and time (shifts, days, etc.) where the time of the day or the shift can be a factor that influences the response.
Many industrial and human subjects experiments involve blocking, or when they do not, probably should in order to reduce the unexplained variation.
Where does the term block come from? The original use of the term block for removing a source of variation comes from agriculture. Given that you have a plot of land and you want to do an experiment on crops, for instance perhaps testing different varieties or different levels of fertilizer, you would take a section of land and divide it into plots and assigned your treatments at random to these plots. If the section of land contains a large number of plots, they will tend to be very variable - heterogeneous.
A block is characterized by a set of homogeneous plots or a set of similar experimental units. In agriculture a typical block is a set of contiguous plots of land under the assumption that fertility, moisture, weather, will all be similar, and thus the plots are homogeneous.
Failure to block is a common flaw in designing an experiment. Can you think of the consequences?
If the nuisance variable is known and controllable, we use blocking and control it by including a blocking factor in our experiment.
If you have a nuisance factor that is known but uncontrollable, sometimes we can use analysis of covariance (see Chapter 15) to measure and remove the effect of the nuisance factor from the analysis. In that case we adjust statistically to account for a covariate, whereas in blocking, we design the experiment with a block factor as an essential component of the design. Which do you think is preferable?
Many times there are nuisance factors that are unknown and uncontrollable (sometimes called a “lurking” variable). We use randomization to balance out their impact. We always randomize so that every experimental unit has an equal chance of being assigned to a given treatment. Randomization is our insurance against a systematic bias due to a nuisance factor.
Sometimes several sources of variation are combined to define the block, so the block becomes an aggregate variable. Consider a scenario where we want to test various subjects with different treatments.
Age classes and gender
In studies involving human subjects, we often use gender and age classes as the blocking factors. We could simply divide our subjects into age classes, however this does not consider gender. Therefore we partition our subjects by gender and from there into age classes. Thus we have a block of subjects that is defined by the combination of factors, gender and age class.
Institution (size, location, type, etc)
Often in medical studies, the blocking factor used is the type of institution. This provides a very useful blocking factor, hopefully removing institutionally related factors such as size of the institution, types of populations served, hospitals versus clinics, etc., that would influence the overall results of the experiment.
Example 4.1: Hardness Testing
In this example we wish to determine whether 4 different tips (the treatment factor) produce different (mean) hardness readings on a Rockwell hardness tester. The treatment factor is the design of the tip for the machine that determines the hardness of metal. The tip is one component of the testing machine.
To conduct this experiment we assign the tips to an experimental unit; that is, to a test specimen (called a coupon), which is a piece of metal on which the tip is tested.
If the structure were a completely randomized experiment (CRD) that we discussed in lesson 3, we would assign the tips to a random piece of metal for each test. In this case, the test specimens would be considered a source of nuisance variability. If we conduct this as a blocked experiment, we would assign all four tips to the same test specimen, randomly assigned to be tested on a different location on the specimen. Since each treatment occurs once in each block, the number of test specimens is the number of replicates.
Back to the hardness testing example, the experimenter may very well want to test the tips across specimens of various hardness levels. This shows the importance of blocking. To conduct this experiment as a RCBD, we assign all 4 tips to each specimen.
In this experiment, each specimen is called a “block”; thus, we have designed a more homogenous set of experimental units on which to test the tips.
Variability between blocks can be large, since we will remove this source of variability, whereas variability within a block should be relatively small. In general, a block is a specific level of the nuisance factor.
Another way to think about this is that a complete replicate of the basic experiment is conducted in each block. In this case, a block represents an experimental-wide restriction on randomization. However, experimental runs within a block are randomized.
Suppose that we use b = 4 blocks as shown in the table below:
| Test Coupon (Block) | |||
|---|---|---|---|
| 1 | 2 | 3 | 4 |
| Tip 3 | Tip 3 | Tip 2 | Tip 1 |
| Tip 1 | Tip 4 | Tip 1 | Tip 4 |
| Tip 4 | Tip 2 | Tip 3 | Tip 3 |
| Tip 2 | Tip 1 | Tip 4 | Tip 3 |
Notice the two-way structure of the experiment. Here we have four blocks and within each of these blocks is a random assignment of the tips within each block.
We are primarily interested in testing the equality of treatment means, but now we have the ability to remove the variability associated with the nuisance factor (the blocks) through the grouping of the experimental units prior to having assigned the treatments.
The ANOVA for Randomized Complete Block Design (RCBD)
In the RCBD we have one run of each treatment in each block. In some disciplines, each block is called an experiment (because a copy of the entire experiment is in the block) but in statistics, we call the block to be a replicate. This is a matter of scientific jargon, the design and analysis of the study is an RCBD in both cases.
Suppose that there are a treatments (factor levels) and b blocks.
A statistical model (effects model) for the RCBD is:
\(Y_{ij}=\mu +\tau_i+\beta_j+\varepsilon_{ij}
\left\{\begin{array}{c}
i=1,2,\ldots,a \\
j=1,2,\ldots,b
\end{array}\right. \)
This is just an extension of the model we had in the one-way case. We have for each observation \(Y_{ij}\) an additive model with an overall mean, plus an effect due to treatment, plus an effect due to block, plus error.
The relevant (fixed effects) hypothesis for the treatment effect is:
\(H_0:\mu_1=\mu_2=\cdots=\mu_a \quad \mbox{where}
\quad \mu_i=(1/b)\sum\limits_{j=1}^b (\mu+\tau_i+\beta_j)=\mu+\tau_i\)
\(\mbox{if}\quad \sum\limits_{j=1}^b \beta_j =0\)
We make the assumption that the errors are independent and normally distributed with constant variance \(\sigma^2\).
The ANOVA is just a partitioning of the variation:
\begin{eqnarray*} \sum\limits_{i=1}^a \sum\limits_{j=1}^b (y_{ij}-\bar{y}_{..})^2 &=& \sum\limits_{i=1}^a \sum\limits_{j=1}^b [(\bar{y}_{i.}-\bar{y}_{..})+(\bar{y}_{.j}-\bar{y}_{..}) \\ & & +(y_{ij}-\bar{y}_{i.}-\bar{y}_{.j}+\bar{y}_{..})]^2\\ &=& b\sum\limits_{i=1}{a}(\bar{y}_{i.}-\bar{y}_{..})^2+a\sum\limits_{j=1}{b}(\bar{y}_{.j}-\bar{y}_{..})^2\\ & & +\sum\limits_{i=1}^a \sum\limits_{j=1}^b (y_{ij}-\bar{y}_{i.}-\bar{y}_{.j}+\bar{y}_{..})^2 \end{eqnarray*}
\(SS_T=SS_{Treatments}+SS_{Blocks}+SS_E\)
The algebra of the sum of squares falls out in this way. We can partition the effects into three parts: sum of squares due to treatments, sum of squares due to the blocks and the sum of squares due to error.
The degrees of freedom for the sums of squares in:
\(SS_T=SS_{Treatments}+SS_{Blocks}+SS_E\)
are as follows for a treatments and b blocks:
\(ab-1=(a-1)+(b-1)+(a-1)(b-1)\)
The partitioning of the variation of the sum of squares and the corresponding partitioning of the degrees of freedom provides the basis for our orthogonal analysis of variance.
ANOVA Display for the RCBD
| Source of Variation |
Sum of Squares | Degrees of Freedom |
Mean Square | \(F_{0}\) |
|---|---|---|---|---|
| Treatments | \(SS_{Treatments}\) | \(a-1\) | \(\dfrac{SS_{Treatments}}{a-1}\) | \(\dfrac{MS_{Treatments}}{MS_{g}}\) |
| Blocks | \(SS_{Blocks}\) | \(b-1\) | \(\dfrac{SS_{Blocks}}{b-1}\) | |
| Error | \(SS_{E}\) | \((a-1)(b-1)\) | \(\dfrac{SS_{g}}{(a-1)(b-1)}\) | |
| Total | \(SS_{T}\) | \(N-1\) | ||
| Table 4-2 Analysis of Variance for a Randomized Complete Block Design | ||||
In Table 4.2 we have the sum of squares due to treatment, the sum of squares due to blocks, and the sum of squares due to error. The degrees of freedom add up to a total of N-1, where N = ab. We obtain the Mean Square values by dividing the sum of squares by the degrees of freedom.
Then, under the null hypothesis of no treatment effect, the ratio of the mean square for treatments to the error mean square is an F statistic that is used to test the hypothesis of equal treatment means.
The text provides manual computing formulas; however, we will use Minitab to analyze the RCBD.
Back to the Tip Hardness example:
Remember, the hardness of specimens (coupons) is tested with 4 different tips.
Here is the data for this experiment (tip_hardness.csv):
| Obs | Tip | Hardness | Coupon |
|---|---|---|---|
| 1 | 1 | 9.3 | 1 |
| 2 | 1 | 9.4 | 2 |
| 3 | 1 | 9.6 | 3 |
| 4 | 1 | 10.0 | 4 |
| 5 | 2 | 9.4 | 1 |
| 6 | 2 | 9.3 | 2 |
| 7 | 2 | 9.8 | 3 |
| 8 | 2 | 9.9 | 4 |
| 9 | 3 | 9.2 | 1 |
| 10 | 3 | 9.4 | 2 |
| 11 | 3 | 9.5 | 3 |
| 12 | 3 | 9.7 | 4 |
| 13 | 4 | 9.7 | 1 |
| 14 | 4 | 9.6 | 2 |
| 15 | 4 | 10.0 | 3 |
| 16 | 4 | 10.2 | 4 |
Here is the output from Minitab. We can see four levels of the Tip and four levels for Coupon:
The Analysis of Variance table shows three degrees of freedom for Tip three for Coupon, and the error degrees of freedom is nine. The ratio of mean squares of treatment over error gives us an F ratio that is equal to 14.44 which is highly significant since it is greater than the .001 percentile of the F distribution with three and nine degrees of freedom.
| Factor | Type | Levels | Values |
|---|---|---|---|
| Tip | fixed | 4 | 1, 2, 3, 4 |
| Coupon | fixed | 4 | 1, 2, 3, 4 |
Analysis of Variance for Hardness
| Source | DF | SS | MS | F | P |
|---|---|---|---|---|---|
| Tip | 3 | 0.38500 | 0.12833 | 14.44 | 0.001 |
| Coupon | 3 | 0.82500 | 0.27500 | 30.94 | 0.000 |
| Error | 9 | 0.0800 | 0.00889 | ||
| Total | 15 | 1.29000 | |||
| S = 0.0942809 R-Sq = 93.80% R-Sq(adj) = 89.66% | |||||
Our 2-way analysis also provides a test for the block factor, Coupon. The ANOVA shows that this factor is also significant with an F-test = 30.94. So, there is a large amount of variation in hardness between the pieces of metal. This is why we used specimen (or coupon) as our blocking factor. We expected in advance that it would account for a large amount of variation. By including block in the model and in the analysis, we removed this large portion of the variation, such that the residual error is quite small. By including a block factor in the model, the error variance is reduced, and the test on treatments is more powerful.
The test on the block factor is typically not of interest except to confirm that you used a good blocking factor. The results are summarized by the table of means given below.
Means
| Tip | N | Hardness | Coupon | N | Hardness |
|---|---|---|---|---|---|
| 1 | 4 | 9.5750 | 1 | 4 | 9.4000 |
| 2 | 4 | 9.6000 | 3 | 4 | 9.4250 |
| 3 | 4 | 9.4500 | 3 | 4 | 9.7250 |
| 4 | 4 | 9.8750 | 4 | 4 | 9.9500 |
Here is the residual analysis from the two-way structure.
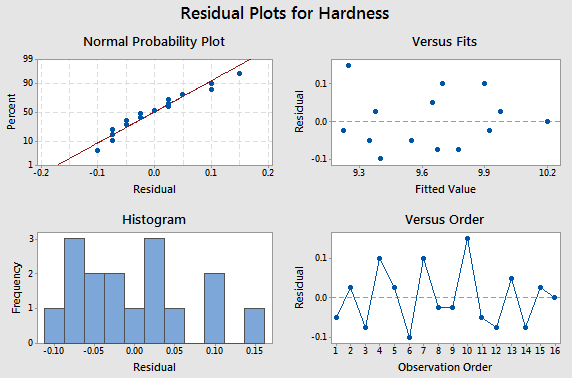
Comparing the CRD to the RCBD
To compare the results from the RCBD, we take a look at the table below. What we did here was use the one-way analysis of variance instead of the two-way to illustrate what might have occurred if we had not blocked, if we had ignored the variation due to the different specimens.
ANOVA: Hardness versus Tip
| Factor | Type | Levels | Values |
|---|---|---|---|
| Tip | fixed | 4 | 1, 2, 3, 4 |
Analysis of Variance for Hardness
| Source | DF | SS | MS | F | P |
|---|---|---|---|---|---|
| Tip | 3 | 0.38500 | 0.12833 | 1.70 | 0.220 |
| Error | 12 | 0.90500 | 0.07542 | ||
| Total | 15 | 1.29000 | |||
| S = 0.274621 R-Sq = 29.84% R-Sq(adj) = 12.31% | |||||
This isn't quite fair because we did in fact block, but putting the data into one-way analysis we see the same variation due to tip, which is 3.85. So we are explaining the same amount of variation due to the tip. That has not changed. But now we have 12 degrees of freedom for error because we have not blocked and the sum of squares for error is much larger than it was before, thus our F-test is 1.7. If we hadn't blocked the experiment our error would be much larger and in fact, we would not even show a significant difference among these tips. This provides a good illustration of the benefit of blocking to reduce error. Notice that the standard deviation, \(S=\sqrt{MSE}\), would be about three times larger if we had not blocked.
Other Aspects of the RCBD
The RCBD utilizes an additive model – one in which there is no interaction between treatments and blocks. The error term in a randomized complete block model reflects how the treatment effect varies from one block to another.
Both the treatments and blocks can be looked at as random effects rather than fixed effects, if the levels were selected at random from a population of possible treatments or blocks. We consider this case later, but it does not change the test for a treatment effect.
What are the consequences of not blocking if we should have? Generally the unexplained error in the model will be larger, and therefore the test of the treatment effect less powerful.
How to determine the sample size in the RCBD? The OC curve approach can be used to determine the number of blocks to run. The number of blocks, b, represents the number of replications. The power calculations that we looked at before would be the same, except that we use b rather than n, and we use the estimate of error, \(\sigma^{2}\), that reflects the improved precision based on having used blocks in our experiment. So, the major benefit or power comes not from the number of replications but from the error variance which is much smaller because you removed the effects due to block.
4.2 - RCBD and RCBD's with Missing Data
4.2 - RCBD and RCBD's with Missing DataExample 4.1: Vascular Graft
This example investigates a procedure to create artificial arteries using a resin. The resin is pressed or extruded through an aperture that forms the resin into a tube.
To conduct this experiment as a RCBD, we need to assign all 4 pressures at random to each of the 6 batches of resin. Each batch of resin is called a “block”, since a batch is a more homogenous set of experimental units on which to test the extrusion pressures. Below is a table which provides percentages of those products that met the specifications.
| Extrusion Pressure (PSI) | Batch of Resin (Block) | Treatment Total | |||||
|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | ||
| 8500 | 90.3 | 89.2 | 98.2 | 93.9 | 87.4 | 97.9 | 556.9 |
| 8700 | 92.5 | 89.5 | 90.6 | 94.7 | 87.0 | 95.8 | 550.1 |
| 8900 | 85.5 | 90.8 | 89.6 | 86.2 | 88.0 | 93.4 | 533.5 |
| 9100 | 82.5 | 89.5 | 85.6 | 87.4 | 78.9 | 90.7 | 514.6 |
| Block Totals | 350.8 | 359.0 | 364.0 | 362.2 | 341.3 | 377.8 | \(y_n = 2155.1\) |
| Table 4-3 Randomized Complete Block Design for the Vascular Graft Experiment | |||||||
Output...
Response: Yield
ANOVA for selected Factorial Model
Analysis of variance table [Partial sum of squares]
| Source | Sum of Squares | DF | Mean Square | F Value | Prob > F |
|---|---|---|---|---|---|
| Block | 192.25 | 5 | 38.45 | ||
| Model | 178.17 | 3 | 59.39 | 8.11 | 0.0019 |
| A | 178.17 | 3 | 59.39 | 8.11 | 0.0019 |
| Residual | 109.89 | 15 | 7.33 | ||
| Cor Total | 480.31 | 23 |
| Std. Dev. | 2.71 | R-Squared | 0.6185 |
| Mean | 89.80 | Adj R-Squared | 0.5422 |
| C.V. | 3.01 | Pred R-Squared | 0.0234 |
| PRESS | 281.31 | Adeq Precision | 9.759 |
Notice that Design Expert does not perform the hypothesis test on the block factor. Should we test the block factor?
Below is the Minitab output which treats both batch and treatment the same and tests the hypothesis of no effect.
ANOVA: Yield versus Batch, Pressure
| Factor | Type | Level | Values |
|---|---|---|---|
| Batch | random | 6 | 1,2,3,4,5,6 |
| Pressure | fixed | 4 | 8500, 8700, 8900, 9100 |
Analysis of Variance for Yield
| Source | DF | SS | MS | F | P |
|---|---|---|---|---|---|
| Batch | 5 | 192.252 | 38.450 | 5.25 | 0.006 |
| Pressure | 3 | 178.171 | 59.390 | 8.11 | 0.002 |
| Error | 15 | 109.886 | 7.326 | ||
| Total | 23 | 480.310 |
| S = 2.70661 | R-Sq = 77.12% | R-Sq(adj) = 64.92% |
This example shows the output from the ANOVA command in Minitab (Menu > Stat > ANOVA > Balanced ANOVA). It does hypothesis tests for both batch and pressure, and they are both significant. Otherwise, the results from both programs are very similar.
Again, should we test the block factor? Generally, the answer is no, but in some instances, this might be helpful. We use the RCBD design because we hope to remove from error the variation due to the block. If the block factor is not significant, then the block variation, or mean square due to the block treatments is no greater than the mean square due to the error. In other words, if the block F ratio is close to 1 (or generally not greater than 2), you have wasted effort in doing the experiment as a block design, and used in this case 5 degrees of freedom that could be part of error degrees of freedom, hence the design could actually be less efficient!
Therefore, one can test the block simply to confirm that the block factor is effective and explains variation that would otherwise be part of your experimental error. However, you generally cannot make any stronger conclusions from the test on a block factor, because you may not have randomly selected the blocks from any population, nor randomly assigned the levels.
Why did I first say no?
There are two cases we should consider separately when blocks are: 1) a classification factor and 2) an experimental factor. In the case where blocks are a batch, it is a classification factor, but it might also be subjects or plots of land which are also classification factors. For a RCBD you can apply your experiment to convenient subjects. In the general case of classification factors, you should sample from the population in order to make inferences about that population. These observed batches are not necessarily a sample from any population. If you want to make inferences about a factor then there should be an appropriate randomization, i.e. random selection, so that you can make inferences about the population. In the case of experimental factors, such as oven temperature for a process, all you want is a representative set of temperatures such that the treatment is given under homogeneous conditions. The point is that we set the temperature once in each block; we don't reset it for each observation. So, there is no replication of the block factor. We do our randomization of treatments within a block. In this case, there is an asymmetry between treatment and block factors. In summary, you are only including the block factor to reduce the error variation due to this nuisance factor, not to test the effect of this factor.
ANOVA: Yield versus Batch, Pressure
The residual analysis for the Vascular Graft example is shown:
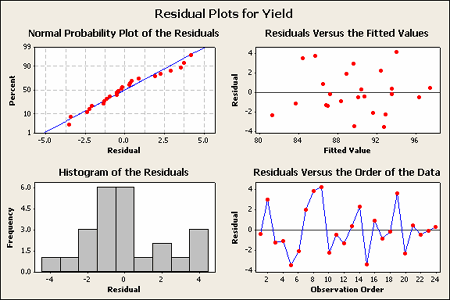
The pattern does not strike me as indicating an unequal variance.
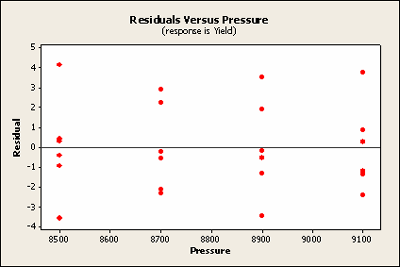
Another way to look at these residuals is to plot the residuals against the two factors. Notice that pressure is the treatment factor and batch is the block factor. Here we'll check for homogeneous variance. Against treatment these look quite homogeneous.
Plotted against block the sixth does raise ones eyebrow a bit. It seems to be very close to zero.
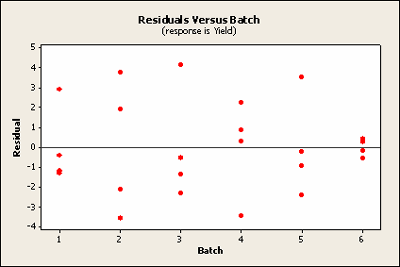
Basic residual plots indicate that normality, constant variance assumptions are satisfied. Therefore, there seems to be no obvious problems with randomization. These plots provide more information about the constant variance assumption, and can reveal possible outliers. The plot of residuals versus order sometimes indicates a problem with the independence assumption.
Missing Data
In the example dataset above, what if the data point 94.7 (second treatment, fourth block) was missing? What data point can I substitute for the missing point?
If this point is missing we can substitute x, calculate the sum of squares residuals, and solve for x which minimizes the error and gives us a point based on all the other data and the two-way model. We sometimes call this an imputed point, where you use the least squares approach to estimate this missing data point.
After calculating x, you could substitute the estimated data point and repeat your analysis. Now you have an artificial point with known residual zero. So you can analyze the resulting data, but now should reduce your error degrees of freedom by one. In any event, these are all approximate methods, i.e., using the best fitting or imputed point.
Before high-speed computing, data imputation was often done because the ANOVA computations are more readily done using a balanced design. There are times where imputation is still helpful but in the case of a two-way or multiway ANOVA we generally will use the General Linear Model (GLM) and use the full and reduced model approach to do the appropriate test. This is often called the General Linear Test (GLT).
Let's take a look at this in Minitab now (no sound)...
The sum of squares you want to use to test your hypothesis will be based on the adjusted treatment sum of squares, \(R( \tau_i | \mu, \beta_j) \) using the notation for testing:
\(H_0 \colon \tau_i = 0\)
The numerator of the F-test, for the hypothesis you want to test, should be based on the adjusted SS's that is last in the sequence or is obtained from the adjusted sums of squares. That will be very close to what you would get using the approximate method we mentioned earlier. The general linear test is the most powerful test for this type of situation with unbalanced data.
The General Linear Test can be used to test for significance of multiple parameters of the model at the same time. Generally, the significance of all those parameters which are in the Full model but are not included in the Reduced model are tested, simultaneously. The F test statistic is defined as
\(F^\ast=\dfrac{SSE(R)-SSE(F)}{df_R-df_F}\div \dfrac{SSE(F)}{df_F}\)
Where F stands for “Full” and R stands for “Reduced.” The numerator and denominator degrees of freedom for the F statistic is \(df_R - df_F\) and \(df_F\) , respectively.
Here are the results for the GLM with all the data intact. There are 23 degrees of freedom total here so this is based on the full set of 24 observations.
General Linear Model: Yield versus, Batch, Pressure
| Factor | Type | Levels | Values |
|---|---|---|---|
| Batch | fixed | 6 | 1, 2, 3, 4, 5, 6 |
| Pressure | fixed | 4 | 8500, 8700, 8900, 9100 |
Analysis of variance for Yield, using Adjusted SS for Tests
| Source | DF | Seq SS | Adj SS | Adj MS | F | P |
|---|---|---|---|---|---|---|
| Batch | 5 | 192.252 | 192.252 | 38.450 | 5.25 | 0.006 |
| Pressure | 3 | 178.171 | 178.171 | 59.390 | 8.11 | 0.002 |
| Error | 15 | 109.886 | 109.886 | 7.326 | ||
| Total | 23 | 480.310 |
| S = 2.70661 | R-Sq = 77.12% | R-Sq(adj) =64.92% |
Least Squares Means for Yield
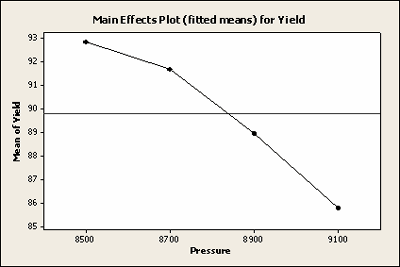
| Pressure | Mean | SE Mean | |
|---|---|---|---|
| 8500 | 92.82 | 1.105 | |
| 8700 | 91.68 | 1.105 | |
| 8900 | 88.92 | 1.105 | |
| 9100 | 85.77 | 1.105 | |
| Main Effects Plot (fitted means) for Yield | |||
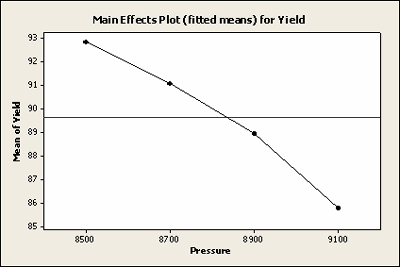
When the data are complete this analysis from GLM is correct and equivalent to the results from the two-way command in Minitab. When you have missing data, the raw marginal means are wrong. What if the missing data point were from a very high measuring block? It would reduce the overall effect of that treatment, and the estimated treatment mean would be biased.
Above you have the least squares means that correspond exactly to the simple means from the earlier analysis.
We now illustrate the GLM analysis based on the missing data situation - one observation missing (Batch 4, pressure 2 data point removed). The least squares means as you can see (below) are slightly different, for pressure 8700. What you also want to notice is the standard error of these means, i.e., the S.E., for the second treatment is slightly larger. The fact that you are missing a point is reflected in the estimate of error. You do not have as many data points on that particular treatment.
Results for: Ex4-1miss.MTW
General Linear Model: Yield versus, Batch, Pressure
| Factor | Type | Levels | Values |
|---|---|---|---|
| Batch | fixed | 6 | 1, 2, 3, 4, 5, 6 |
| Pressure | fixed | 4 | 8500, 8700, 8900, 9100 |
Analysis of variance for Yield, using Adjusted SS for Tests
| Source | DF | Seq SS | Adj SS | Adj MS | F | P |
|---|---|---|---|---|---|---|
| Batch | 5 | 190.119 | 189.522 | 37.904 | 5.22 | 0.007 |
| Pressure | 3 | 163.398 | 163.398 | 54.466 | 7.50 | 0.003 |
| Error | 14 | 101.696 | 101.696 | 7.264 | ||
| Total | 22 | 455.213 |
| S = 2.69518 | R-Sq = 77.66% | R-Sq(adj) =64.99% |
Least Squares Means for Yield
| Pressure | Mean | SE Mean |
|---|---|---|
| 8500 | 92.82 | 1.100 |
| 8700 | 91.08 | 1.238 |
| 8900 | 88.92 | 1.100 |
| 9100 | 85.77 | 1.100 |
The overall results are similar. We have only lost one point and our hypothesis test is still significant, with a p-value of 0.003 rather than 0.002.
Here is a plot of the least squares means for Yield with all of the observations included.
Here is a plot of the least squares means for Yield with the missing data, not very different.
Again, for any unbalanced data situation, we will use the GLM. For most of our examples, GLM will be a useful tool for analyzing and getting the analysis of variance summary table. Even if you are unsure whether your data are orthogonal, one way to check if you simply made a mistake in entering your data is by checking whether the sequential sums of squares agree with the adjusted sums of squares.
4.3 - The Latin Square Design
4.3 - The Latin Square DesignLatin Square Designs are probably not used as much as they should be - they are very efficient designs. Latin square designs allow for two blocking factors. In other words, these designs are used to simultaneously control (or eliminate) two sources of nuisance variability. For instance, if you had a plot of land the fertility of this land might change in both directions, North -- South and East -- West due to soil or moisture gradients. So, both rows and columns can be used as blocking factors. However, you can use Latin squares in lots of other settings. As we shall see, Latin squares can be used as much as the RCBD in industrial experimentation as well as other experiments.
Whenever, you have more than one blocking factor a Latin square design will allow you to remove the variation for these two sources from the error variation. So, consider we had a plot of land, we might have blocked it in columns and rows, i.e. each row is a level of the row factor, and each column is a level of the column factor. We can remove the variation from our measured response in both directions if we consider both rows and columns as factors in our design.
The Latin Square Design gets its name from the fact that we can write it as a square with Latin letters to correspond to the treatments. The treatment factor levels are the Latin letters in the Latin square design. The number of rows and columns has to correspond to the number of treatment levels. So, if we have four treatments then we would need to have four rows and four columns in order to create a Latin square. This gives us a design where we have each of the treatments and in each row and in each column.
This is just one of many 4×4 squares that you could create. In fact, you can make any size square you want, for any number of treatments - it just needs to have the following property associated with it - that each treatment occurs only once in each row and once in each column.
Consider another example in an industrial setting: the rows are the batch of raw material, the columns are the operator of the equipment, and the treatments (A, B, C and D) are an industrial process or protocol for producing a particular product.
What is the model? We let:
\(y_{ijk} = \mu + \rho_i + \beta_j + \tau_k + e_{ijk}\)
i = 1, ... , t
j = 1, ... , t
[k = 1, ... , t] where - k = d(i, j) and the total number of observations
\(N = t^2\) (the number of rows times the number of columns) and t is the number of treatments.
Note that a Latin Square is an incomplete design, which means that it does not include observations for all possible combinations of i, j and k. This is why we use notation \(k = d(i, j)\). Once we know the row and column of the design, then the treatment is specified. In other words, if we know i and j, then k is specified by the Latin Square design.
This property has an impact on how we calculate means and sums of squares, and for this reason, we can not use the balanced ANOVA command in Minitab even though it looks perfectly balanced. We will see later that although it has the property of orthogonality, you still cannot use the balanced ANOVA command in Minitab because it is not complete.
An assumption that we make when using a Latin square design is that the three factors (treatments, and two nuisance factors) do not interact. If this assumption is violated, the Latin Square design error term will be inflated.
The randomization procedure for assigning treatments that you would like to use when you actually apply a Latin Square, is somewhat restricted to preserve the structure of the Latin Square. The ideal randomization would be to select a square from the set of all possible Latin squares of the specified size. However, a more practical randomization scheme would be to select a standardized Latin square at random (these are tabulated) and then:
- randomly permute the columns,
- randomly permute the rows, and then
- assign the treatments to the Latin letters in a random fashion.
Consider a factory setting where you are producing a product with 4 operators and 4 machines. We call the columns the operators and the rows the machines. Then you can randomly assign the specific operators to a row and the specific machines to a column. The treatment is one of four protocols for producing the product and our interest is in the average time needed to produce each product. If both the machine and the operator have an effect on the time to produce, then by using a Latin Square Design this variation due to machine or operators will be effectively removed from the analysis.
The following table gives the degrees of freedom for the terms in the model.
|
AOV
|
df
|
df for the example
|
|
Rows
|
t-1
|
3
|
|
Cols
|
t-1
|
3
|
|
Treatments
|
t-1
|
3
|
|
Error
|
(t-1)(t-2)
|
6
|
|
Total
|
(t2 - 1)
|
15
|
A Latin Square design is actually easy to analyze. Because of the restricted layout, one observation per treatment in each row and column, the model is orthogonal.
If the row, \(\rho_i\), and column, \(\beta_j\), effects are random with expectations zero, the expected value of \(Y_{ijk}\) is \(\mu + \tau_k\). In other words, the treatment effects and treatment means are orthogonal to the row and column effects. We can also write the sums of squares, as seen in Table 4.10 in the text.
We can test for row and column effects, but our focus of interest in a Latin square design is on the treatments. Just as in RCBD, the row and column factors are included to reduce the error variation but are not typically of interest. And, depending on how we've conducted the experiment they often haven't been randomized in a way that allows us to make any reliable inference from those tests.
Note: if you have missing data then you need to use the general linear model and test the effect of treatment after fitting the model that would account for the row and column effects.
In general, the General Linear Model tests the hypothesis that:
\(H_0 \colon \tau_i = 0\) vs. \(H_A \colon \tau_i \ne 0\)
To test this hypothesis we will look at the F-ratio which is written as:
\(F=\dfrac{MS(\tau_k|\mu,\rho_i,\beta_j)}{MSE(\mu,\rho_i,\beta_j,\tau_k)}\sim F((t-1),(t-1)(t-2))\)
To get this in Minitab you would use GLM and fit the three terms: rows, columns and treatments. The F statistic is based on the adjusted MS for treatment.
The Rocket Propellant Problem – A Latin Square Design
| Batches of Raw Material | Operators | ||||
|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | |
| 1 | A = 24 | B = 20 | C = 19 | D = 24 | E = 24 |
| 2 | B = 17 | C = 24 | D = 30 | E = 27 | A = 36 |
| 3 | C = 18 | D = 38 | E = 26 | A = 27 | B = 21 |
| 4 | D = 26 | E = 31 | A = 26 | B = 23 | C = 22 |
| 5 | E = 22 | A = 30 | B = 20 | C = 29 | D = 31 |
| Latin Square Design for the Rocket Propellant | |||||
Statistical Analysis of the Latin Square Design
The statistical (effects) model is:
\(Y_{ijk}=\mu +\rho_i+\beta_j+\tau_k+\varepsilon_{ijk}
\left\{\begin{array}{c}
i=1,2,\ldots,p \\
j=1,2,\ldots,p\\
k=1,2,\ldots,p
\end{array}\right. \)
but \(k = d(i, j)\) shows the dependence of k in the cell i, j on the design layout, and p = t the number of treatment levels.
The statistical analysis (ANOVA) is much like the analysis for the RCBD.
The analysis for the rocket propellant example is presented in Example 4.3.
4.4 - Replicated Latin Squares
4.4 - Replicated Latin SquaresLatin Squares are very efficient by including two blocking factors, however, the d.f. for error are often too small. In these situations, we consider replicating a Latin Square. Let's go back to the factory scenario again as an example and look at n = 3 repetitions of a 4 × 4 Latin square.
We labeled the row factor the machines, the column factor the operators and the Latin letters denoted the protocol used by the operators which were the treatment factor. We will replicate this Latin Square experiment n = 3 times. Now we have total observations equal to \(N = t^{2}n\).
You could use the same squares over again in each replicate, but we prefer to randomize these separately for each replicate. It might look like this:
Ok, with this scenario in mind, let's consider three cases that are relevant and each case requires a different model to analyze. The cases are determined by whether or not the blocking factors are the same or different across the replicated squares. The treatments are going to be the same but the question is whether the levels of the blocking factors remain the same.
Case 1
Here we will have the same row and column levels. For instance, we might do this experiment all in the same factory using the same machines and the same operators for these machines. The first replicate would occur during the first week, the second replicate would occur during the second week, etc. Week one would be replication one, week two would be replication two and week three would be replication three.
We would write the model for this case as:
\(Y_{hijk}=\mu +\delta _{h}+\rho _{i}+\beta _{j}+\tau _{k}+e_{hijk}\)
where:
\(h = 1, \dots , n\)
\(i = 1, \dots , t\)
\(j = 1, \dots , t\)
\(k = d_{h}(i,j)\) - the Latin letters
This is a simple extension of the basic model that we had looked at earlier. We have added one more term to our model. The row and column and treatment all have the same parameters, the same effects that we had in the single Latin square. In a Latin square, the error is a combination of any interactions that might exist and experimental error. Remember, we can't estimate interactions in a Latin square.
Let's take a look at the analysis of variance table.
|
AOV
|
df
|
df for Case 1
|
SS
|
| rep=week |
\(n - 1\)
|
2
|
|
| row=machine |
\(t - 1\)
|
3
|
|
| column=operator |
\(t - 1\)
|
3
|
|
| treatment=protocol |
\(t - 1\)
|
3
|
|
| error |
\((t - 1) [n( t + 1) - 3]\)
|
36
|
|
|
Total
|
\(nt^{2} - 1\)
|
47
|
|
Case 2
In this case, one of our blocking factors, either row or column, is going to be the same across replicates whereas the other will take on new values in each replicate. Back to the factory example e.g., we would have a situation where the machines are going to be different (you can say they are nested in each of the repetitions) but the operators will stay the same (crossed with replicates). In this scenario, perhaps, this factory has three locations and we want to include machines from each of these three different factories. To keep the experiment standardized, we will move our operators with us as we go from one factory location to the next. This might be laid out like this:
There is a subtle difference here between this experiment in a Case 2 and the experiment in Case 1 - but it does affect how we analyze the data. Here the model is written as:
\(Y_{hijk}=\mu +\delta _{h}+\rho _{i(h)}+\beta _{j}+\tau _{k}+e_{hijk}\)
where:
\(h = 1, \dots , n\)
\(i = 1, \dots , t\)
\(j = 1, \dots , t\)
\(k = d_{h}(i,j)\)- the Latin letters
and the 12 machines are distinguished by nesting the i index within the h replicates.
This affects our ANOVA table. Compare this to the previous case:
|
AOV
|
df
|
df for Case 2
|
SS
|
| rep = factory |
\(n - 1\)
|
2
|
See text p. 144. |
| row (rep) = machine (factory) |
\(n(t - 1)\)
|
9
|
|
| column = operator |
\(t - 1\)
|
3
|
|
| treatment = protocol |
\(t - 1\)
|
3
|
|
| error |
\((t - 1) (nt - 2)\)
|
30
|
|
|
Total
|
\(nt^{2} - 1\)
|
47
|
Note that Case 2 may also be flipped where you might have the same machines, but different operators.
Case 3
In this case, we have different levels of both the row and the column factors. Again, in our factory scenario, we would have different machines and different operators in the three replicates. In other words, both of these factors would be nested within the replicates of the experiment.
We would write this model as:
\(Y_{hijk}=\mu +\delta _{h}+\rho _{i(h)}+\beta _{j(h)}+\tau _{k}+e_{hijk}\)
where:
h = 1, ... , n
i = 1, ... , t
j = 1, ... , t
\(k = d_{h}(i,j)\) - the Latin letters
Here we have used nested terms for both of the block factors representing the fact that the levels of these factors are not the same in each of the replicates.
The analysis of variance table would include:
|
AOV
|
df
|
df for Case 3
|
SS
|
| rep = factory |
\(n - 1\)
|
2
|
See text p. 144. |
| row (rep) = machine (factory) |
\(n(t - 1)\)
|
9
|
|
| column (rep) = operator (factory) |
\(n(t - 1)\)
|
9
|
|
| treatment protocol |
\(t - 1\)
|
3
|
|
| error |
\((t - 1) [n(t - 1) - 1]\)
|
24
|
|
|
Total
|
\(nt^{2} - 1\)
|
47
|
Which case is best?
There really isn't a best here... the choice of case depends on how you need to conduct the experiment. If you are simply replicating the experiment with the same row and column levels, you are in Case 1. If you are changing one or the other of the row or column factors, using different machines or operators, then you are in Case 2. If both of the block factors have levels that differ across the replicates, then you are in Case 3. The third case, where the replicates are different factories, can also provide a comparison of the factories. The fact that you are replicating Latin Squares does allow you to estimate some interactions that you can't estimate from a single Latin Square. If we added a treatment by factory interaction term, for instance, this would be a meaningful term in the model, and would inform the researcher whether the same protocol is best (or not) for all the factories.
The degrees of freedom for error grows very rapidly when you replicate Latin squares. But usually if you are using a Latin Square then you are probably not worried too much about this error. The error is more dependent on the specific conditions that exist for performing the experiment. For instance, if the protocol is complicated and training the operators so they can conduct all four becomes an issue of resources then this might be a reason why you would bring these operators to three different factories. It depends on the conditions under which the experiment is going to be conducted.
Situations where you should use a Latin Square are where you have a single treatment factor and you have two blocking or nuisance factors to consider, which can have the same number of levels as the treatment factor.
4.5 - What do you do if you have more than 2 blocking factors?
4.5 - What do you do if you have more than 2 blocking factors?When might this occur? Let's consider the factory example again. In this factory you have four machines and four operators to conduct your experiment. You want to complete the experimental trials in a week. Use the animation below to see how this example of a typical treatment schedule pans out.
As the treatments were assigned you should have noticed that the treatments have become confounded with the days. Days of the week are not all the same, Monday is not always the best day of the week! Just like any other factor not included in the design you hope it is not important or you would have included it into the experiment in the first place.
What we now realize is that two blocking factors is not enough! We should also include the day of the week in our experiment. It looks like day of the week could affect the treatments and introduce bias into the treatment effects, since not all treatments occur on Monday. We want a design with 3 blocking factors; machine, operator, and day of the week.
One way to do this would be to conduct the entire experiment on one day and replicate it four times. But this would require 4 × 16 = 64 observations not just 16. Or, we could use what is called a Graeco-Latin Square.
Graeco-Latin Squares
We write the Latin square first then each of the Greek letters occurs alongside each of the Latin letters. A Graeco-Latin square is a set of two orthogonal Latin squares where each of the Greek and Latin letters is a Latin square and the Latin square is orthogonal to the Greek square. Use the animation below to explore a Graeco-Latin square:
The Greek letters each occur one time with each of the Latin letters. A Graeco-Latin square is orthogonal between rows, columns, Latin letters and Greek letters. It is completely orthogonal.
How do we use this design?
We let the row be the machines, the column be the operator, (just as before) and the Greek letter the day, (you could also think of this as the order in which it was produced). Therefore the Greek letter could serve the multiple purposes as the day effect or the order effect. The Latin letters are assigned to the treatments as before.
We want to account for all three of the blocking factor sources of variation, and remove each of these sources of error from the experiment. Therefore we must include them in the model.
Here is the model for this design:
\(Y_{ijkl}= \mu + \rho _{i}+\beta _{j}+\tau _{k}+ \gamma _{l}+e_{ijkl}\)
So, we have three blocking factors and one treatment factor.
and i, j, k and l all go from 1, ... , t , where i and j are the row and column indices, respectively, and k and l are defined by the design, that is, k and l are specified by the Latin and Greek letters, respectively.
This is a highly efficient design with \(N = t^2\) observations.
You could go even farther and have more than two orthogonal latin squares together. These are referred to a Hyper-Graeco-Latin squares!
Fisher, R.A. The Design of Experiments, 8th edition, 1966, p.82-84, gives examples of hyper-Graeco-Latin squares for t = 4, 5, 8 and 9.
4.6 - Crossover Designs
4.6 - Crossover DesignsCrossover designs use the same experimental unit for multiple treatments. The common use of this design is where you have subjects (human or animal) on which you want to test a set of drugs -- this is a common situation in clinical trials for examining drugs.
The simplest case is where you only have 2 treatments and you want to give each subject both treatments. Here as with all crossover designs we have to worry about carryover effects.
Here is a timeline of this type of design.
We give the treatment, then we later observe the effects of the treatment. This is followed by a period of time, often called a washout period, to allow any effects to go away or dissipate. This is followed by a second treatment, followed by an equal period of time, then the second observation.
If we only have two treatments, we will want to balance the experiment so that half the subjects get treatment A first, and the other half get treatment B first. For example, if we had 10 subjects we might have half of them get treatment A and the other half get treatment B in the first period. After we assign the first treatment, A or B, and make our observation, we then assign our second treatment.
This situation can be represented as a set of 5, 2 × 2 Latin squares.
We have not randomized these, although you would want to do that, and we do show the third square different from the rest. The row effect is the order of treatment, whether A is done first or second or whether B is done first or second. And the columns are the subjects. So, if we have 10 subjects we could label all 10 of the subjects as we have above, or we could label the subjects 1 and 2 nested in a square. This is similar to the situation where we have replicated Latin squares - in this case five reps of 2 × 2 Latin squares, just as was shown previously in Case 2.
This crossover design has the following AOV table set up:
| AOV | df | df for this example |
| rep = square | \(n - 1\) | 4 |
| column = subject(sq) | \(n(t - 1)\) | 5 |
| row = order | \(t - 1\) | 1 |
| treatment = A vs. B | \(t - 1\) | 1 |
| error | \((t - 1) (nt - 2)\) | 8 |
| Total | \(nt^{2} - 1\) | 19 |
We have five squares and within each square we have two subjects. So we have 4 degrees of freedom among the five squares. We have 5 degrees of freedom representing the difference between the two subjects in each square. If we combine these two, 4 + 5 = 9, which represents the degrees of freedom among the 10 subjects. This representation of the variation is just the partitioning of this variation. The same thing applies in the earlier cases we looked at.
With just two treatments there are only two ways that we can order them. Let's look at a crossover design where t = 3. If t = 3 then there are more than two ways that we can represent the order. The basic building block for the crossover design is the Latin Square.
Here is a 3 × 3 Latin Square. To achieve replicates, this design could be replicated several times.
In this Latin Square we have each treatment occurring in each period. Even though Latin Square guarantees that treatment A occurs once in the first, second and third period, we don't have all sequences represented. It is important to have all sequences represented when doing clinical trials with drugs.
Crossover Design Balanced for Carryover Effects
The following crossover design, is based on two orthogonal Latin squares.
Together, you can see that going down the columns every pairwise sequence occurs twice, AB, BC, CA, AC, BA, CB going down the columns. The combination of these two Latin squares gives us this additional level of balance in the design, than if we had simply taken the standard Latin square and duplicated it.
To do a crossover design, each subject receives each treatment at one time in some order. So, one of its benefits is that you can use each subject as its own control, either as a paired experiment or as a randomized block experiment, the subject serves as a block factor. For each subject we will have each of the treatments applied. The number of periods is the same as the number of treatments. It is just a question about what order you give the treatments. The smallest crossover design which allows you to have each treatment occurring in each period would be a single Latin square.
A 3 × 3 Latin square would allow us to have each treatment occur in each time period. We can also think about period as the order in which the drugs are administered. One sense of balance is simply to be sure that each treatment occurs at least one time in each period. If we add subjects in sets of complete Latin squares then we retain the orthogonality that we have with a single square.
In designs with two orthogonal Latin Squares we have all ordered pairs of treatments occurring twice and only twice throughout the design. Take a look at the video below to get a sense of how this occurs:
All ordered pairs occur an equal number of times in this design. It is balanced in terms of residual effects, or carryover effects.
For an odd number of treatments, e.g. 3, 5, 7, etc., it requires two orthogonal Latin squares in order to achieve this level of balance. For even number of treatments, 4, 6, etc., you can accomplish this with a single square. This form of balance is denoted balanced for carryover (or residual) effects.
Here is an actual data example for a design balanced for carryover effects. In this example the subjects are cows and the treatments are the diets provided for the cows. Using the two Latin squares we have three diets A, B, and C that are given to 6 different cows during three different time periods of six weeks each, after which the weight of the milk production was measured. In between the treatments a wash out period was implemented.
How do we analyze this? If we didn't have our concern for the residual effects then the model for this experiment would be:
\(Y_{ijk}= \mu + \rho _{i}+\beta _{j}+\tau _{k}+e_{ijk}\)
where:
\(\rho_i = \text{period}\)
\(\beta_j = \text{cows}\)
\(\tau_k = \text{treatment}\)
\(i = 1, ..., 3 (\text{the number of treatments})\)
\(j = 1 , .... , 6 (\text{the number of cows})\)
\(k = 1, ..., 3 (\text{the number of treatments})\)
Let's take a look at how this is implemented in Minitab using GLM. Use the viewlet below to walk through an initial analysis of the data (cow_diets.mwx | cow_diets.csv) for this experiment with cow diets.
Why do we use GLM? We do not have observations in all combinations of rows, columns, and treatments since the design is based on the Latin square.
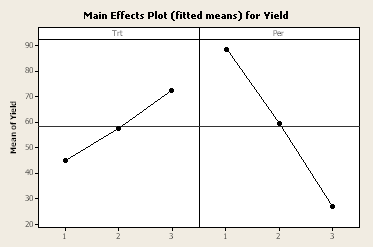
Here is a plot of the least square means for treatment and period. We can see in the table below that the other blocking factor, cow, is also highly significant.
General Linear Model: Yield versus Per, Cow, Trt
| Factor | Type | Levels | Values |
|---|---|---|---|
| Per | fixed | 3 | 1, 2, 3 |
| Cow | fixed | 6 | 1, 2, 3, 4, 5, 6 |
| Trt | fixed | 3 | 1, 2, 3 |
Analysis of Variance for Yield, using Adjusted SS for Tests
| Source | DF | Seq SS | Adj SS | Adj Ms | F | P |
|---|---|---|---|---|---|---|
| Per | 2 | 11480.1 | 11480.1 | 5740.1 | 55.70 | 0.000 |
| Cow | 5 | 5781.1 | 5781.1 | 1156.2 | 11.22 | 0.002 |
| Trt | 2 | 2276.8 | 2276.8 | 1138.4 | 11.05 | 0.005 |
| Error | 8 | 824.4 | 824.4 | 103.1 | ||
| Total | 17 | 20362.4 |
| S = 10.1516 | R-Sq = 95.95% | R-Sq(adj) = 91.40% |
So, let's go one step farther...
Is this an example of Case 2 or Case 3 of the multiple Latin Squares that we had looked at earlier?
This is a Case 2 where the column factor, the cows are nested within the square, but the row factor, period, is the same across squares.
Notice the sum of squares for cows is 5781.1. Let's change the model slightly using the general linear model in Minitab again. Follow along with the video.
Now I want to move from Case 2 to Case 3. Is the period effect in the first square the same as the period effect in the second square? If it only means order and all the cows start lactating at the same time it might mean the same. But if some of the cows are done in the spring and others are done in the fall or summer, then the period effect has more meaning than simply the order. Although this represents order it may also involve other effects you need to be aware of this. A Case 3 approach involves estimating separate period effects within each square.
My guess is that they all started the experiment at the same time - in this case, the first model would have been appropriate.
How Do We Analyze Carryover Effect?
OK, we are looking at the main treatment effects. With our first cow, during the first period, we give it a treatment or diet and we measure the yield. Obviously, you don't have any carryover effects here because it is the first period. However, what if the treatment they were first given was a really bad treatment? In fact in this experiment the diet A consisted of only roughage, so, the cow's health might in fact deteriorate as a result of this treatment. This could carry over into the next period. This carryover would hurt the second treatment if the washout period isn't long enough. The measurement at this point is a direct reflection of treatment B but may also have some influence from the previous treatment, treatment A.
If you look at how we have coded data here, we have another column called residual treatment. For the first six observations, we have just assigned this a value of 0 because there is no residual treatment. But for the first observation in the second row, we have labeled this with a value of one indicating that this was the treatment prior to the current treatment (treatment A). In this way the data is coded such that this column indicates the treatment given in the prior period for that cow.
Now we have another factor that we can put in our model. Let's take a look at how this looks in Minitab:
We have learned everything we need to learn. We have the appropriate analysis of variance here. By fitting in order, when residual treatment (i.e., ResTrt) was fit last we get:
SS(treatment | period, cow) = 2276.8
SS(ResTrt | period, cow, treatment) = 616.2
When we flip the order of our treatment and residual treatment, we get the sums of squares due to fitting residual treatment after adjusting for period and cow:
SS(ResTrt | period, cow) = 38.4
SS(treatment | period, cow, ResTrt) = 2854.6
Which of these are we interested in? If we wanted to test for residual treatment effects how would we do that? What would we use to test for treatment effects if we wanted to remove any carryover effects?
4.7 - Incomplete Block Designs
4.7 - Incomplete Block DesignsIn using incomplete block designs we will use the notation t = # of treatments. We define the block size as k. And, as you will see, in incomplete block designs k will be less than t. You cannot assign all of the treatments in each block. In short,
t = # of treatments,
k = block size,
b = # of blocks,
\(r_i\) = # of replicates for treatment i, in the entire design.
Remember that an equal number of replications is the best way to be sure that you have minimum variance if you're looking at all possible pairwise comparisons. If \(r_i = r\) for all treatments, the total number of observations in the experiment is N where:
\(N = t(r) = b(k)\)
The incidence matrix which defines the design of the experiment, gives the number of observations say \(n_{ij}\) for the \(i^{th}\) treatment in the \(j^{th}\) block. This is what it might look like here:
Here we have treatments 1, 2, up to t and the blocks 1, 2, up to b. For a complete block design, we would have each treatment occurring one time within each block, so all entries in this matrix would be 1's. For an incomplete block design, the incidence matrix would be 0's and 1's simply indicating whether or not that treatment occurs in that block.
Example 1
The example that we will look at is Table 4.22 (4.21 in 7th ed). Here is the incidence matrix for this example:
Here we have t = 4, b = 4, (four rows and four columns) and k = 3 ( so at each block we can only put three of the four treatments leaving one treatment out of each block). So, in this case, the row sums (\(r_i\) ) and the columns sums, k, are all equal to 3.
In general, we are faced with a situation where the number of treatments is specified, and the block size, or number of experimental units per block (k) is given. This is usually a constraint given from the experimental situation. And then, the researcher must decide how many blocks are needed to run and how many replicates that provides in order to achieve the precision or the power that you want for the test.
Example 2
Here is another example of an incidence matrix for allocating treatments and replicates in an incomplete block design. Let's take an example where k = 2, still t = 4, and b = 4. That gives us a case r = 2. In This case we could design our incidence matrix so that it might look like this:
This example has two observations per block so k = 2 in each case and for all treatments r = 2.
Balanced Incomplete Block Design (BIBD)
A BIBD is an incomplete block design where all pairs of treatments occur together within a block an equal number of times ( \(\lambda\) ). In general, we will specify \(\lambda_{ii^\prime}\) as the number of times treatment \(i\) occurs with \(i^\prime\), in a block.
Let's look at previous cases. How many times does treatment one and two occur together in this first example design?
It occurs together in block 2 and then again in block 4 (highlighted in light blue). So, \(\lambda_{12} = 2\). If we look at treatment one and three, this occurs together in block one and in block two therefore \(\lambda_{13} = 2\). In this design, you can look at all possible pairs. Let's look at 1 and 4 - they occur together twice, 2 and 3 occur together twice, 2 and 4 twice, and 3 and 4 occur together twice. For this design \(\lambda_{ii^\prime} = 2\) for all \(ii^\prime\) treatment pairs defining the concept of balance in this incomplete block design.
If the number of times treatments occur together within a block is equal across the design for all pairs of treatments then we call this a balanced incomplete block design (BIBD).
Now look at the incidence matrix for the second example.
We can see that:
\(\lambda_{12}\) occurs together 0 times.
\(\lambda_{13}\) occurs together 2 times.
\(\lambda_{14}\) occurs together 0 times.
\(\lambda_{23}\) occurs together 0 times.
\(\lambda_{24}\) occurs together 2 times.
\(\lambda_{34}\) occurs together to 0 times.
Here we have two pairs occurring together 2 times and the other four pairs occurring together 0 times. Therefore, this is not a balanced incomplete block design (BIBD).
What else is there about BIBD?
We can define \(\lambda\) in terms of our design parameters when we have equal block size k, and equal replication \(r_i = r\). For a given set of t, k, and r we define \(\lambda\) as:
\(\lambda = r(k-1) / t-1\)
So, for the first example that we looked at earlier - let's plug in the values and calculate \(\lambda\):
\(\lambda = 3 (3 - 1) / (4 -1) = 2\)
Here is the key: when \(\lambda\) is equal to an integer number it tells us that a balanced incomplete block design exists. Let's look at the second example and use the formula and plug in the values for this second example. So, for \(t = 4\), \(k = 2\), \(r = 2\) and \(b = 4\), we have:
\(\lambda = 2 (2 - 1) / (4 - 1) = 0.666\)
Since \(\lambda\) is not an integer there does not exist a balanced incomplete block design for this experiment. We would either need more replicates or a larger block size. Seeing as how the block size in this case is fixed, we can achieve a balanced complete block design by adding more replicates so that \(\lambda\) equals at least 1. It needs to be a whole number in order for the design to be balanced.
We will talk about partially balanced designs later. But in thinking about this case we note that a balanced design doesn't exist so what would be the best partially balanced design? That would be a question that you would ask if you could only afford four blocks and the block size is two. Given this situation, is the design in Example 2 the best design we can construct? The best partially balanced design is where \(\lambda_{ii^\prime}\) should be the nearest integers to the \(\lambda\) that we calculated. In our case each \(\lambda_{ii^\prime}\) should be either 0 or 1, the integers nearest 0.667. This example is not as close to balanced as it could be. In fact, it is not even a connected design where you can go from any treatment to any other treatment within a block. More about this later...
How do you construct a BIBD?
In some situations, it is easy to construct the best IBD, however, for other cases it can be quite difficult and we will look them up in a reference.
Let's say that we want six blocks, we still want 4 treatments and our block size is still 2. Calculate \(\lambda = r(k - 1) / (t - 1) = 1\). We want to create all possible pairs of treatments because lambda is equal to one. We do this by looking at all possible combinations of four treatments taking two at a time. We could set up the incidence matrix for the design or we could represent it like this - entries in the table are treatment labels: {1, 2, 3, 4}.
However, this method of constructing a BIBD using all possible combinations, does not always work as we now demonstrate. If the number of combinations is too large then you need to find a subset - - not always easy to do. However, sometimes you can use Latin Squares to construct a BIBD. As an example, let's take any 3 columns from a 4 × 4 Latin Square design. This subset of columns from the whole Latin Square creates a BIBD. However, not every subset of a Latin Square is a BIBD.
Let's look at an example. In this example we have t = 7, b = 7, and k = 3. This means that r = 3 = (bk) / t . Here is the 7 × 7 Latin square :
We want to select (k = 3) three columns out of this design where each treatment occurs once with every other treatment because \(\lambda = 3(3 - 1) / (7 - 1) = 1\).
We could select the first three columns - let's see if this will work. Click the animation below to see whether using the first three columns would give us combinations of treatments where treatment pairs are not repeated.
Since the first three columns contain some pairs more than once, let's try columns 1, 2, and now we need a third...how about the fourth column. If you look at all possible combinations in each row, each treatment pair occurs only one time.
What if we could afford a block size of 4 instead of 3? Here t = 7, b = 7, k = 4, then r = 4. We calculate \(\lambda = r(k - 1) / (t - 1) = 2\) so a BIBD does exist. For this design with a block size of 4 we can select 4 columns (or rows) from a Latin square. Let's look at columns again... can you select the correct 4?
Now consider the case with 8 treatments. The number of possible combinations of 8 treatments taking 4 at a time is 70. Thus with 70 sets of 4 from which you have to choose 14 blocks - - wow, this is a big job! At this point, we should simply look at an appropriate reference. Here is a handout - a catalog that will help you with this selection process - taken from Cochran & Cox, Experimental Design, p. 469-482.
Analysis of BIBD's
When we have missing data, it affects the average of the remaining treatments in a row, i.e., when complete data does not exist for each row - this affects the means. When we have complete data the block effect and the column effects both drop out of the analysis since they are orthogonal. With missing data or IBDs that are not orthogonal, even BIBD where orthogonality does not exist, the analysis requires us to use GLM which codes the data like we did previously. The GLM fits first the block and then the treatment.
The sequential sums of squares (Seq SS) for block is not the same as the Adj SS.
We have the following:
Seq SS
\(SS(\beta | \mu) 55.0\)
\(SS(\tau | \mu, \beta) = 22.50\)
Adj SS
\(SS(\beta | \mu, \tau) = 66.08\)
\(SS(\tau | \mu, \beta) = 22.75\)
Switch them around...now first fit treatments and then the blocks.
Seq SS
\(SS(\tau | \mu) = 11.67\)
\(SS(\beta | \mu, \tau) = 66.08\)
Adj SS
\(SS(\tau | \mu, \beta) = 22.75\)
\(SS(\beta | \mu, \tau_i) = 66.08\)
The 'least squares means' come from the fitted model. Regardless of the pattern of missing data or the design we can conceptually think of our design represented by the model:
\(Y_{ij}= \mu + +\beta _{i}+\tau _{j}+e_{ij}\)
\(i = 1, \dots , b\), \(j = 1, \dots , t\)
You can obtain the 'least squares means' from the estimated parameters from the least squares fit of the model.
Optional Section
See the discussion in the text for Recovery of Interblock Information, p. 154. This refers to a procedure which allows us to extract additional information from a BIBD when the blocks are a random effect. Optionally you can read this section. We illustrate the analysis by the use of the software, PROC Mixed in SAS (L03_sas_Ex_4_5.sas):
data; input blk trt Y; cards;
1 1 73
1 3 73
1 4 75
2 1 74
2 2 75
2 3 75
3 2 67
3 3 68
3 4 72
4 1 71
4 2 72
4 4 75
;;;;
/*This data is from Example 4-5 in Montgomery, Design and Analysis of experiments, 6th edition, */
/* Wiley, 2005, pages 147-154. This demonstrates the recovery of interblock information when */
/* the blocks are considered random. */
proc glm; class trt blk;
model Y = blk trt;
lsmeans trt/ e stderr pdiff;
proc mixed; class trt blk;
model Y = trt;
random blk;
lsmeans trt/ e pdiff;
/* The next 4 estimate statements calculate the treatment effects from the solution*/
estimate "trt effect 1" trt +.75 -.25 -.25 -.25/e;
estimate "trt effect 2" trt -.25 +.75 -.25 -.25/e;
estimate "trt effect 3" trt -.25 -.25 +.75 -.25/e;
estimate "trt effect 4" trt -.25 -.25 -.25 +.75/e;
/* The next 3 contrast statements show one set of orthogonal contrasts*/
contrast "trt1 vs trt2-4" trt 3 -1 -1 -1;
contrast "trt2 vs trt3-4" trt 0 2 -1 -1 ;
contrast "trt3 vs trt4" trt 0 0 1 -1 ;
run;
The SAS System 12:49 Friday, August 15, 2008 1
The GLM Procedure
Class Level Information
Class Levels Values
trt 4 1 2 3 4
blk 4 1 2 3 4
Number of Observations Read 12
Number of Observations Used 12
The SAS System 12:49 Friday, August 15, 2008 2
The GLM Procedure
Dependent Variable: Y
Sum of
Source DF Squares Mean Square F Value Pr > F
Model 6 77.75000000 12.95833333 19.94 0.0024
Error 5 3.25000000 0.65000000
Corrected Total 11 81.00000000
R-Square Coeff Var Root MSE Y Mean
0.959877 1.112036 0.806226 72.50000
Source DF Type I SS Mean Square F Value Pr > F
blk 3 55.00000000 18.33333333 28.21 0.0015
trt 3 22.75000000 7.58333333 11.67 0.0107
Source DF Type III SS Mean Square F Value Pr > F
blk 3 66.08333333 22.02777778 33.89 0.0010
trt 3 22.75000000 7.58333333 11.67 0.0107
The SAS System 12:49 Friday, August 15, 2008 3
The GLM Procedure
Least Squares Means
Coefficients for trt Least Square Means
trt Level
Effect 1 2 3 4
Intercept 1 1 1 1
blk 1 0.25 0.25 0.25 0.25
blk 2 0.25 0.25 0.25 0.25
blk 3 0.25 0.25 0.25 0.25
blk 4 0.25 0.25 0.25 0.25
trt 1 1 0 0 0
trt 2 0 1 0 0
trt 3 0 0 1 0
trt 4 0 0 0 1
Standard LSMEAN
trt Y LSMEAN Error Pr > |t| Number
1 71.3750000 0.4868051 <.0001 1
2 71.6250000 0.4868051 <.0001 2
3 72.0000000 0.4868051 <.0001 3
4 75.0000000 0.4868051 <.0001 4
Least Squares Means for effect trt
Pr > |t| for H0: LSMean(i)=LSMean(j)
Dependent Variable: Y
i/j 1 2 3 4
1 0.7349 0.4117 0.0035
2 0.7349 0.6142 0.0047
3 0.4117 0.6142 0.0077
4 0.0035 0.0047 0.0077
NOTE: To ensure overall protection level, only probabilities associated with pre-planned
comparisons should be used.
The SAS System 12:49 Friday, August 15, 2008 4
The Mixed Procedure
Model Information
Data Set WORK.DATA1
Dependent Variable Y
Covariance Structure Variance Components
Estimation Method REML
Residual Variance Method Profile
Fixed Effects SE Method Model-Based
Degrees of Freedom Method Containment
Class Level Information
Class Levels Values
trt 4 1 2 3 4
blk 4 1 2 3 4
Dimensions
Covariance Parameters 2
Columns in X 5
Columns in Z 4
Subjects 1
Max Obs Per Subject 12
Number of Observations
Number of Observations Read 12
Number of Observations Used 12
Number of Observations Not Used 0
Iteration History
Iteration Evaluations -2 Res Log Like Criterion
0 1 44.37333968
1 1 34.22046396 0.00000000
Convergence criteria met.
The SAS System 12:49 Friday, August 15, 2008 5
The Mixed Procedure
Covariance Parameter
Estimates
Cov Parm Estimate
blk 8.0167
Residual 0.6500
Fit Statistics
-2 Res Log Likelihood 34.2
AIC (smaller is better) 38.2
AICC (smaller is better) 40.6
BIC (smaller is better) 37.0
Type 3 Tests of Fixed Effects
Num Den
Effect DF DF F Value Pr > F
trt 3 5 11.41 0.0113
Coefficients for
trt effect 1
Effect trt Row1
Intercept
trt 1 0.75
trt 2 -0.25
trt 3 -0.25
trt 4 -0.25
Coefficients for
trt effect 2
Effect trt Row1
Intercept
trt 1 -0.25
trt 2 0.75
trt 3 -0.25
trt 4 -0.25
The SAS System 12:49 Friday, August 15, 2008 6
The Mixed Procedure
Coefficients for
trt effect 3
Effect trt Row1
Intercept
trt 1 -0.25
trt 2 -0.25
trt 3 0.75
trt 4 -0.25
Coefficients for
trt effect 4
Effect trt Row1
Intercept
trt 1 -0.25
trt 2 -0.25
trt 3 -0.25
trt 4 0.75
Estimates
Standard
Label Estimate Error DF t Value Pr > |t|
trt effect 1 -1.0869 0.4269 5 -2.55 0.0515
trt effect 2 -0.8836 0.4269 5 -2.07 0.0932
trt effect 3 -0.5000 0.4269 5 -1.17 0.2942
trt effect 4 2.4705 0.4269 5 5.79 0.0022
Contrasts
Num Den
Label DF DF F Value Pr > F
trt1 vs trt2-4 1 5 6.48 0.0515
trt2 vs trt3-4 1 5 9.58 0.0270
trt3 vs trt4 1 5 18.16 0.0080
The SAS System 12:49 Friday, August 15, 2008 7
The Mixed Procedure
Coefficients for trt Least Squares Means
Effect trt Row1 Row2 Row3 Row4
Intercept 1 1 1 1
trt 1 1
trt 2 1
trt 3 1
trt 4 1
Least Squares Means
Standard
Effect trt Estimate Error DF t Value Pr > |t|
trt 1 71.4131 1.4968 5 47.71 <.0001
trt 2 71.6164 1.4968 5 47.84 <.0001
trt 3 72.0000 1.4968 5 48.10 <.0001
trt 4 74.9705 1.4968 5 50.09 <.0001
Differences of Least Squares Means
Standard
Effect trt _trt Estimate Error DF t Value Pr > |t|
trt 1 2 -0.2033 0.6971 5 -0.29 0.7823
trt 1 3 -0.5869 0.6971 5 -0.84 0.4382
trt 1 4 -3.5574 0.6971 5 -5.10 0.0038
trt 2 3 -0.3836 0.6971 5 -0.55 0.6058
trt 2 4 -3.3541 0.6971 5 -4.81 0.0048
trt 3 4 -2.9705 0.6971 5 -4.26 0.0080
Note that the least squares means for treatments when using PROC Mixed, correspond to the combined intra- and inter-block estimates of the treatment effects.
Random Effect Factor
So far we have discussed experimental designs with fixed factors, that is, the levels of the factors are fixed and constrained to some specific values. However, this is often not the case. In some cases, the levels of the factors are selected at random from a larger population. In this case, the inference made on the significance of the factor can be extended to the whole population but the factor effects are treated as contributions to variance.
Minitab’s General Linear Command handles random factors appropriately as long as you are careful to select which factors are fixed and which are random.