Using Auxiliary Information Section
The auxiliary information about the population may include a known variable to which the variable of interest is approximately related. The auxiliary information typically is easy to measure, whereas the variable of interest may be expensive to measure.
- Population units: 1, 2, ... , N
- variable of interest : \(y_1, y_2,...,y_N\) (expensive or costly to measure)
- auxiliary variable : \(x_1, x_2,...,x_N\) (known)
For example, consider:
A national park is partitioned into N units.
- \(y_i\)= the number of animals in unit i
- \(x_i\)= the size of unit i
Another example might be where a certain city has N bookstores.
- \(y_i\) = the sales of a given book title at bookstore i
- \(x_i\)= the size of the bookstore i
A third example would be a forest that has N trees.
- \(y_i\) = the volume of the tree
- \(x_i\) = the diameter of the tree
Ratio Estimators
If \(\tau_y=\sum\limits_{i=1}^N y_i\) and \(\tau_x=\sum\limits_{i=1}^N x_i\) then, \(\dfrac{\tau_y}{\tau_x}=\dfrac{\mu_y}{\mu_x}\) and \(\tau_y=\dfrac{\mu_y}{\mu_x}\cdot \tau_x\)
The ratio estimator, denoted as \(\hat{\tau}_r\) , is \(\hat{\tau}_r=\dfrac{\bar{y}}{\bar{x}}\cdot \tau_x\)
The estimator is useful in the following situation:
-
When X and Y are highly linearly correlated through the origin, then:
\(Var(\hat{\tau}_r)\) is less than \(Var(N\bar{y})\)
-
In the case where N is unknown, then it provides a way to estimate \(\tau_y\) since when N is unknown, one cannot use \(N\bar{y}\).
Historical Use
When was this type of estimator used historically? Probably the first instance of its use occurred in France in 1802. At this time there was no population census and Laplace wanted to estimate the total population of France. He did not have the resources to count every individual so he sampled 30 communities in France. In this case for Laplace, n = 30, and the total number of inhabitants in these communities = 2,037,615. What type of information did the government already have?
Laplace found auxiliary information to help him and found good records of the number of registered births. It turns out that the total number of registered births for the 30 communities that he had selected = 71,866.33.
Dividing 2,037,615 by 71,866.33, he estimated that there is one registered birth for every 28.35 persons. Therefore, he estimated the total population by the total number of annual births × 28.35
Rationale: Communities with larger populations are likely to have a larger number of registered births.
This is an example of the early use of ratio estimation.
Example 4-1: Total Weight of Apple Juice Section
For a juice company, the price they paid for apples in large shipments is based on the amount of apple juice from the load. Therefore, we need to determine the amount of apple juice in the whole load prior to extraction. We can sample n apples and find \(y_1,...,y_n\) the amount of apple juice in those apples. \(N\bar{y}\) is hard to get in this case because N is hard to count. How could we measure this?
The total weight would be a good idea and easy to get. We will use the relationship between the weight of the load and the weight of the apple juice one obtains.
Y is related to x, the weight of each apple in the sample and the total weight is easy to get for the entire shipment. We can thus estimate the total apple juice by:
\(\hat{\tau}_r=\dfrac{\bar{y}}{\bar{x}}\cdot \tau_x\)
For this example, N is unknown and we cannot use \(N\bar{y}\). One can see that if the condition for using the ratio estimator is satisfied and N is known, this ratio estimator may actually work better than \(N\bar{y}\).
Similarly, to estimate \(\mu_y\), we can use
\(\hat{\mu}_r=\dfrac{\bar{y}}{\bar{x}}\cdot \mu_x\)
It turns out that this estimate is not unbiased. Note that \(\hat{\tau}_r\) is not unbiased for \(\tau_y\) and \(\hat{\mu}_r\) is not unbiased for \(\mu_y\) but they are approximately unbiased for large samples when the sampling is a simple random sampling. The approximate MSE of \(\hat{\mu}_r\) is \(Var(\hat{\mu}_r)\) and given by.
\(Var(\hat{\mu}_r) \approx \left( \dfrac{N-n}{N} \right)\cdot \dfrac{\sigma^2_r}{n}\)
How can we compute the \(\sigma^2_r\)?
where, \(\sigma^2_r=\dfrac{1}{N-1} \sum\limits_{i=1}^N \left( y_i-\dfrac{\tau_y}{\tau_x}\cdot x_i \right)^2\)
When we want to estimate \(\sigma^2_r\) we will estimate using this formula:
\(s^2_r=\dfrac{1}{n-1} \sum\limits_{i=1}^n \left( y_i-\dfrac{\bar{y}}{\bar{x}}\cdot x_i \right)^2\)
Given all of this, when do we know that the estimate \(\hat{\mu}_r\) is good? We can compare it to:
\(Var(\bar{y})=\left(\dfrac{N-n}{N}\right)\cdot \dfrac{\sigma^2}{n}\)
\(\hat{\mu}_r\) will perform better if \(\sigma^2_r\)< \(\sigma^2\) . That is the case for populations for which y's and x's are highly correlated and with roughly a linear relationship through the origin.
An approximate 100(1 - \(\alpha\))% CI for \(\mu_y\) is
\(\hat{\mu}_r \pm t_{n-1,\alpha/2}\sqrt{\hat{V}ar(\hat{\mu}_r)}\)
for \(\tau_y\),
\(\hat{\tau}_r=N \hat{\mu}_r=\dfrac{\bar{y}}{\bar{x}}\cdot \tau_x\)
\(\hat{V}ar(\hat{\tau}_r)=N \cdot (N-n) \dfrac{s^2_r}{n}\)
Back to the context for this example...
Using Minitab
As it turns out in this example, 15 apples selected by simple random samples were weighed and also juiced. The total weight of the apple shipment was found to be 2000 pounds. What we need to do, given the table of results below, is to get a point estimate of the total weight of the juice for the shipment of apples and provide a 95% confidence interval. Here is the data in a Minitab worksheet (Apple_Juice.txt) which contains the following columns of data:
- C1 is the sampled Apple
- C2 is \(Y\), the weight of the Apple juice in lbs.
- C3 is \(X\), the weight of the Apple in lbs.
- C4 is \(Y-rX\), the observed y value - estimated y value, and
- C5 is \((Y-rX)^2\), the (observed y value - estimated y value) squared.
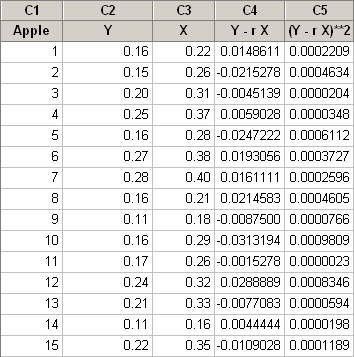
Total Apple juice weight is 2.85 lbs. (mean = 0.19 lbs.)
Total Apple weight is 4.32 lbs. (mean = 0.288 lbs.)
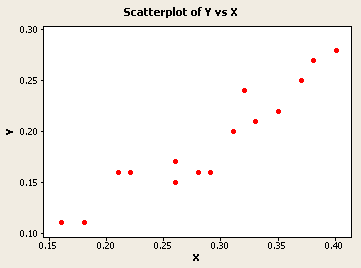
We can use Minitab to generate the scatterplot, the regression analysis, and the descriptive statistics:
Graph > Scatterplot
Stat > Regression > Regression
Choose Y for the Response and X for the continuous predictor.
Stat > Basic Statistics
Questions
-
Is it appropriate to use the ratio estimate?
Use the graph and analysis below to justify your answer.
Minitab output:
Regression Analysis: Apple juice Y versus Weight X
Coefficients
Predictor Coef SE Coef T-Value P-Value Constant -0.00904 0.02003 -0.45 0.659 Weight X 0.69112 0.06754 10.23 0.000 Regression Equation
Apple juice Y = - 0.0090 + 0.691 Weight X
S = 0.0185258 R-Sq = 89.0% R-Sq(adj) = 88.1%
The scatterplot of the data shows a linear relationship between the y and x variables. Moreover, the regression analysis suggests that the regression line goes through the origin (p-value of constant = 0.659 > 0.05). Therefore, it appears appropriate to use the ratio estimate.
-
Use ratio estimate to estimate the total weight and provide a 95% confidence interval.
Minitab output:
Descriptive Statistics: Apple juice Y, Weight X
Variable N N* Mean SE Mean StDev Minimum Q1 Median Q3 Maximum Apple juice Y
15 0 0.1900 0.0139 0.0537 0.1100 0.1600 0.1700 0.2400 0.2800 Weight X 15 0 0.2800 0.0189 0.0733 0.1600 0.2200 0.2900 0.3500 0.4000 The ratio estimate of the total weight is
\(\hat{\tau}_r=r\tau_x=\dfrac{0.190}{0.288}\times 2000=1319.44\)
\(s^2_r=\dfrac{1}{n-1} \sum\limits_{i=1}^n (y_i-rx_i)^2=\dfrac{1}{14}[(0.16-0.6597 \times 0.22)^2+\ldots+(0.22-0.6597 \times 0.35)^2]\)
How accurate is this result? Let's compute a confidence interval and for this, we need the variance.
\begin{align}
\hat{V}ar(\hat{\tau}_r)=\hat{N}\cdot (\hat{N}-n)\dfrac{s^2_r}{n} & = \dfrac{\tau_x}{\bar{x}}\left(\dfrac{\tau_x}{\bar{x}}-n\right)\dfrac{s^2_r}{n} \\
& = \dfrac{2000}{0.288}\left(\dfrac{2000}{0.288}-15\right)\dfrac{\dfrac{1}{n-1}\sum\limits_{i=1}^{15}(y_i-rx_i)^2}{n} \\
& = 6944.444\cdot 6929.444 \cdot \dfrac{\dfrac{1}{14}\cdot 0.004536}{15} \\
& = 1039.42\\
\end{align}\(\hat{S}D(\hat{\tau}_r)=32.24\)
Then an approximate 95% CI for \(\tau\) is then:
\begin{array}{lcl}
& = & 1319.44 \pm t_{14} \hat{S}D(\hat{\tau}_r) \\
& = & 1319.44 \pm 2.145 \times 32.24 \\
& = & 1319.44 \pm 69.15
\end{array}Let \(s^2\) denote the sample variance of the \(y_i\)'s, the \(s^2\) can be calculated to be \(s^2= (0.0537)^2=0.004536\), whereas \(s^2_r\) = 0.004536 / 14 = 0.000324.
We see that for this example, the estimate does reduce the variance by using information contained in x about y.
-
Using R
Here is the code for R for this example:
Datafile: Apple.txt
R code: Chapter4_apple.R.txt
Estimation for Ratio Section
In some cases we are interested in estimating:
\(R=\dfrac{\tau_y}{\tau_x}\left(\text{also, } \dfrac{\mu_y}{\mu_x}\right)\)
For example, sociologists are interested in ratios such as the monthly food budget compared to the monthly income per family. The sample ratio is the estimate for R and:
\(r=\dfrac{\bar{y}}{\bar{x}}\), \(Var(r) \approx \left(\dfrac{N-n}{N\mu^2_x}\right)\dfrac{\sigma^2_r}{n}\) and \(\hat{V}ar(r) \approx \left(\dfrac{N-n}{N\mu^2_x}\right)\dfrac{s^2_r}{n}\)