2.3 - An Example
Wage Data Revisited
Wage data is available in the ISLR package in R. The data has been used before in Lesson 1 and it was noted that there are 3000 observations of which 2480 are White and the rest Black, Asian or Other.
Objective is to predict accurately whether a worker will have raw wage above 100 or not. Of the predictors included in the data year, age, education and jobclass are considered as having an impact on the wage. The learning algorithm used for prediction is K-nearest neighbor algorithm which will be considered later in the course. Briefly, KNN is a simple classifier which classifies a new observation based on similarity measure computed amongst 'nearest neighbors'. The predictors are used to compute the similarity. K can take any value from 1 onwards, depending on the size of the data set. If K = 1, the new observation is classified as having the same class as the nearest neighbor. If K > 1, then the most frequent class among the nearest neighbors is assigned to the new observation.
For K = 1 in the training data, there is always overfitting. As a result error in the training data is small, but test error is expected to be high. For a large K, the prediction is not expected to be accurate, since the bias will be high. For an accurate prediction, an optimum value of K is to be determined.
Case I: Holdout sample: Training and Test
Only White data is considered for prediction. Note that Jobclass is a binary variable and Education is an ordinal variable with 5 levels. Age and Year are assumed continuous.
Sample R code for Training and Test Split 50:50
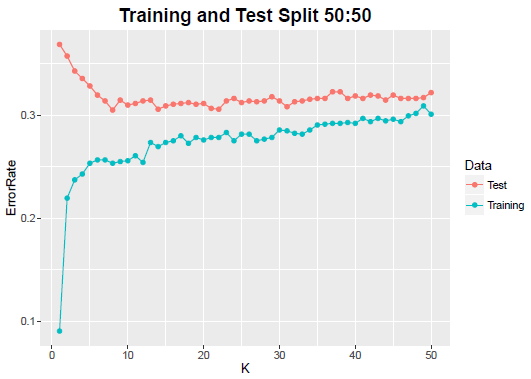
The blue line is the error rate in the training sample. When K = 1, the error rate in training sample is the lowest. As K increases the error rate increases. After a large value of K, the rate of increase becomes negligible.
When K = 1, predictive power of the algorithm is the least, which is corroborated by the test error rate shown. As K increases, test error rate decreases, indicting that the predictive power of the algorithm gets better.
For all the K values considered, minimum is reached at K = 8. It is also clear that for large K, the training and test error rates are close, the training error rate is monotonically increasing but the test error rate has stabilized.
Important Observation: The training and test data creation has an impact on the training and test error rates. For the figure above a random seed value 679 was used. However for a different seed value, a different behavior of training and test errors is noted. In the R codes provided, you may verify this yourself.
Sample R code for Training and Test Split 90:10
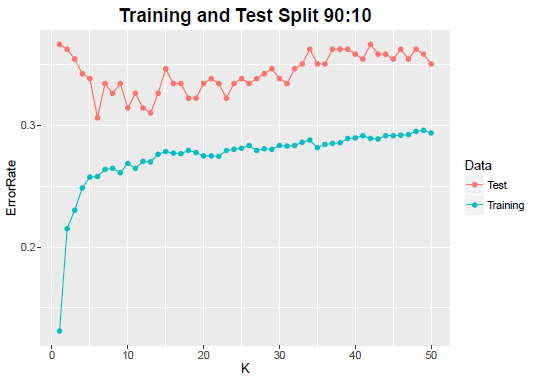
The split between training and test data also may have an impact on the error rate. If the test data is a small proportion of the sample, the error rates will not be smooth, even though the minimum test error is attained at a reasonable lower value of K (K = 6).
Case II: 10-Fold Cross-validation
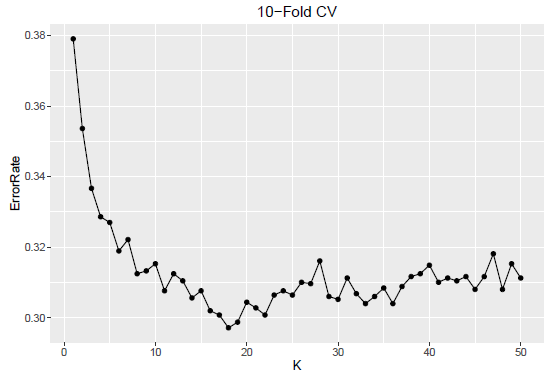
Only White data is considered along with the same 4 predictors. Objective is to find an optimal K. The data is split into 10 partitions of the sample space. All values of K from 1 to 50 is considered. For each value of K, 9 folds are used as the training data to develop the model and the residual part is considered as the test data. By rotation, each fold is considered as part of training data and test data.
Sample R code for 10-Fold Cross-validation
Case III: LOOCV
At every cycle one observation is left out and predicted for class membership using the rest of the observations. This method is also a robust method of error prediction but computation time might be on the higher side.
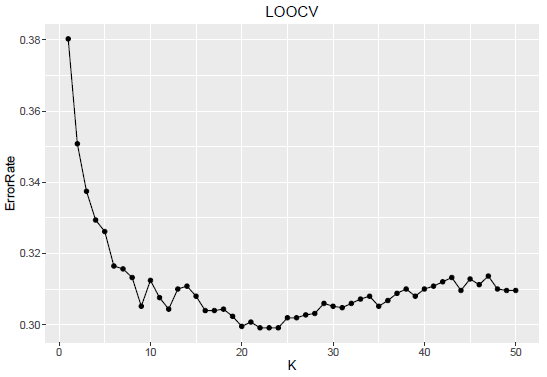
The optimum values of K for 10-fold CV as well as LOOCV are very close. In the former it is 18 while in the latter the value is 20. The error distribution for different K values follow a parabolic curve with a single minimum. The error curve is smoother compared to the hold-out sample situation. It is true that a unique minimum is reached for hold-out sample situations, but the variability of the error curve is much higher.
Also to note that depending on the cross-validation mechanism, the minimum error may be achieved at different value of the tuning parameter.
There is a lot of scope of experimenting here. Different seed values, different proportional split in the data and a number of othetr criteria impact the estimation accuracy of PE.

