7.3 - Log-transforming Both the Predictor and Response for SLR
In this section, we learn how to build and use a model by transforming both the response y and the predictor x. You might have to do this when everything seems wrong — when the regression function is not linear and the error terms are not normal and have unequal variances. In general (although not always!):
- Transforming the y values corrects problems with the error terms (and may help the non-linearity).
- Transforming the x values primarily corrects the non-linearity.
Again, keep in mind that although we're focussing on a simple linear regression model here, the essential ideas apply more generally to multiple linear regression models too.
As before, let's learn about transforming both the x and y values by way of example.
Building the model
An example. Many different interest groups — such as the lumber industry, ecologists, and foresters — benefit from being able to predict the volume of a tree just by knowing its diameter. One classic data set (shortleaf.txt) — reported by C. Bruce and F. X. Schumacher in 1935 — concerned the diameter (x, in inches) and volume (y, in cubic feet) of n = 70 shortleaf pines. Let's use the data set to learn not only about the relationship between the diameter and volume of shortleaf pines, but also about the benefits of simultaneously transforming both the response y and the predictor x.
Although the r2 value is quite high (89.3%), the fitted line plot suggests that the relationship between tree volume and tree diameter is not linear:
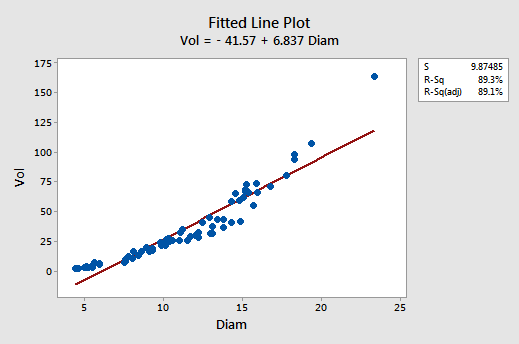
The residuals vs. fits plot also suggests that the relationship is not linear:
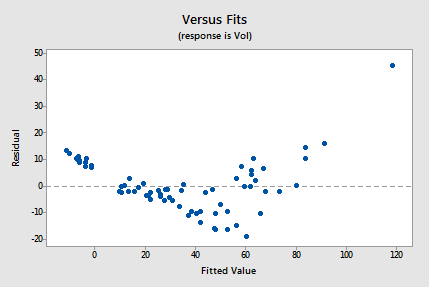
Because the lack of linearity dominates the plot, we can not use the plot to evaluate whether the error variances are equal. We have to fix the non-linearity problem before we can assess the assumption of equal variances.
The normal probability plot suggests that the error terms are not normal. The plot is not quite linear and the Anderson-Darling P-value is 0.012. There is sufficient evidence to conclude that the error terms are not normally distributed:
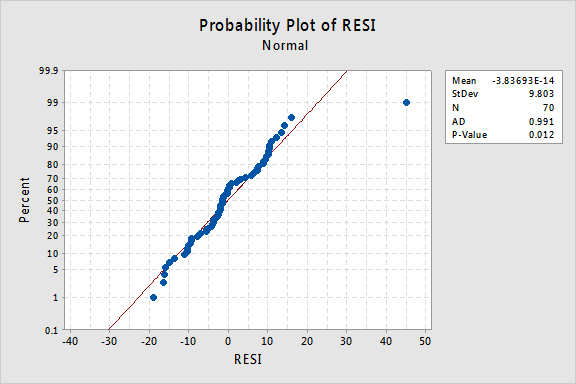
The plot actually has the classical appearance of residuals that are predominantly normal but have one outlier. This illustrates how a data point can be deemed an "outlier" just because of poor model fit.
In summary, it appears as if the relationship between tree diameter and volume is not linear. Furthermore, it appears as if the error terms are not normally distributed.
Let's see if we get anywhere by transforming only the x values. In particular, let's take the natural logarithm of the tree diameters to obtain the new predictor x = lnDiam:
|
Diameter
|
Volume
|
lnDiam
|
|
4.4
|
2.0
|
1.48160
|
|
4.6
|
2.2
|
1.52606
|
|
5.0
|
3.0
|
1.60944
|
|
5.1
|
4.3
|
1.62924
|
|
5.1
|
3.0
|
1.62924
|
|
5.2
|
2.9
|
1.64866
|
|
5.2
|
3.5
|
1.64866
|
|
5.5
|
3.4
|
1.70475
|
|
5.5
|
5.0
|
1.70475
|
|
5.6
|
7.2
|
1.72277
|
|
5.9
|
6.4
|
1.77495
|
|
5.9
|
5.6
|
1.77495
|
|
7.5
|
7.7
|
2.01490
|
|
7.6
|
10.3
|
2.02815
|
|
… and so on …
|
||
For example, ln(5.0) = 1.60944 and ln(7.6) = 2.02815. How well does transforming only the x values work? Not very!
The fitted line plot with y = volume as the response and x = lnDiam as the predictor suggests that the relationship is still not linear:
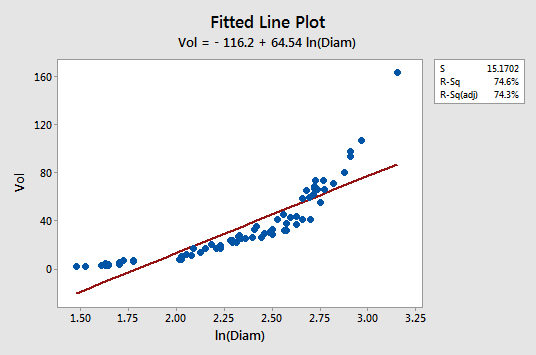
Transforming only the x values didn't change the non-linearity at all. The residuals vs. fits plot also still suggests a non-linear relationship ...
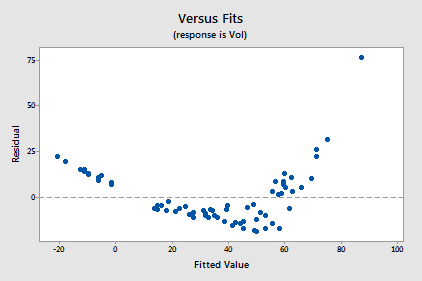
... and there is little improvement in the normality of the error terms:
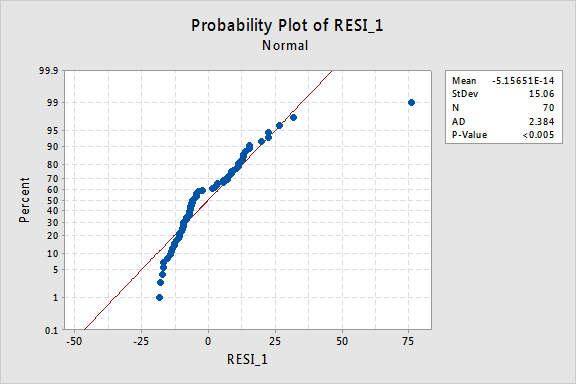
The pattern is not linear and the Anderson-Darling P-value is less than 0.005. There is sufficient evidence to conclude that the error terms are not normally distributed.
So, transforming x alone didn't help much. Let's also try transforming the response (y) values. In particular, let's take the natural logarithm of the tree volumes to obtain the new response y = lnVol:
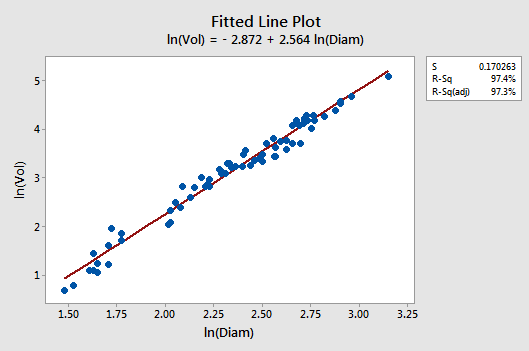
Let's see if transforming both the x and y values does it for us. Wow! The fitted line plot should give us hope! The relationship between the natural log of the diameter and the natural log of the volume looks linear and strong (r2 = 97.4%):
The residuals vs. fits plot provides yet more evidence of a linear relationship between lnVol and lnDiam:
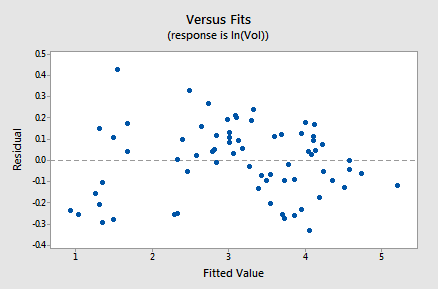
Generally, speaking the residuals bounce randomly around the residual = 0 line. You might be a little concerned that some "funneling" exists. If it does, it doesn't appear to be too severe, as the negative residuals do follow the desired horizontal band.
The normal probability plot has improved substantially:
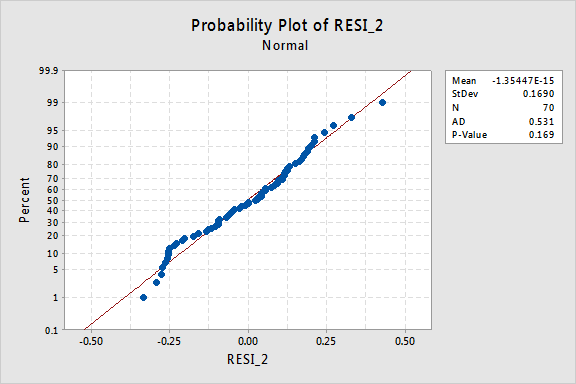
The trend is generally linear and the Anderson-Darling P-value is 0.169. There is insufficient evidence to conclude that the error terms are not normal.
In summary, it appears as if the model with the natural log of tree volume as the response and the natural log of tree diameter as the predictor works well. The relationship appears to be linear and the error terms appear independent and normally distributed with equal variances.
Using the model
Let's now use our linear regression model for the shortleaf pine data—with y = lnVol as the response and x = lnDiam as the predictor—to answer four different research questions.
Research Question #1: What is the nature of the association between diameter and volume of shortleaf pines?
Again, to answer this research question, we just describe the nature of the relationship. That is, the natural logarithm of tree volume is positively linearly related to the natural logarithm of tree diameter. That is, as the natural log of tree diameters increases, the average natural logarithm of the tree volume also increases.
Research Question #2: Is there an association between diameter and volume of shortleaf pines?
Again, in answering this research question, no modification to the standard procedure is necessary. We merely test the null hypothesis H0: β1 = 0 using either the F-test or the equivalent t-test:
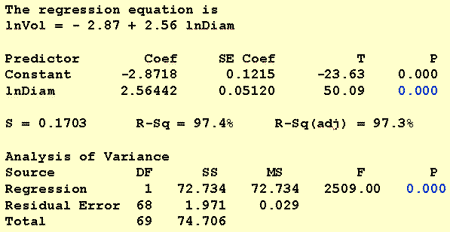
As the software output illustrates, the P-value is < 0.001. There is significant evidence at the 0.01 level to conclude that there is a linear association between the natural logarithm of tree volume and the natural logarithm of tree diameter.
Research Question #3: What is the "average" volume of all shortleaf pine trees that are 10" in diameter?
In answering this research question, if we are only interested in a point estimate, we put x = ln(10) = 2.303 into the estimated regression function:
ln(Vol) = -2.8718 + 2.56442 ln(Diam)
to obtain:
ln(Vol) = -2.8718 + 2.56442 × ln(10) = 3.034
That is, we estimate the average of the natural log of the volumes of all 10"-diameter shortleaf pines to be 3.034 log-cubic feet. Of course, this is not a very helpful conclusion. We have to take advantage of the fact, as we showed before, that the average of the natural log of the volumes approximately equals the natural log of the median of the volumes. Exponentiating both sides of the previous equation:
Vol = eln(Vol) = e3.034 = 20.8 cubic feet
we estimate the median volume of all shortleaf pines with a 10" diameter to be 20.8 cubic feet. Helpful, but not sufficient! A 95% confidence interval for the average of the natural log of the volumes of all 10"-diameter shortleaf pines is:
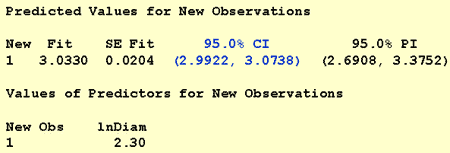
Exponentiating both endpoints of the interval, we get:
e2.9922 = 19.9 and e3.0738 = 21.6.
We can be 95% confident that the median volume of all shortleaf pines, 10" in diameter, is between 19.9 and 21.6 cubic feet.
Research Question #4: What is expected change in volume for a two-fold increase in diameter?
Figuring out how to answer this research question also takes a little bit of work. The end result is:
- In general, the median changes by a factor of \(k^{\beta_1}\) for each k-fold increase in the predictor x.
- Therefore, the median changes by a factor of \(2^{\beta_1}\) for each two-fold increase in the predictor x.
- As always, we won't know the slope of the population line, β1. We have to use b1 to estimate it.
Again, you won't be required to duplicate the derivation, shown below, of this result, but it may help you to understand it and therefore remember it.
For the shortleaf pine data, the software output tells us that b1 = 2.56442:

and therefore:
\[2^{b_1}=2^{2.56442}=5.92\]
The result tells us that the estimated median volume changes by a factor of 5.92 for each two-fold increase in diameter. For example, the median volume of a 20"-diameter tree is estimated to be 5.92 times the median volume of a 10" diameter tree. And, the median volume of a 10"-diameter tree is estimated to be 5.92 times the median volume of a 5"-diameter tree.
So far, we've only calculated a point estimate for the expected change. Of course, a 95% confidence interval for β1 is:
2.56442 ± 1.9955(0.05120) = (2.462, 2.667)
Because:
22.462 = 5.51 and 22.667 = 6.35
we can be 95% confident that the median volume will increase by a factor between 5.51 and 6.35 for each two-fold increase in diameter.

