12.6 - Agglomerative Clustering
Agglomerative clustering can be used as long as we have pairwise distances between any two objects. The mathematical representation of the objects are irrelevant when the pairwise distances are given. Hence agglomerative clustering readily applies for non-vector data.
Let's denote the data set as \(A = {x_1, \cdots , x_n}\).
The agglomerative clustering method is also called a bottom-up method as opposed to k-means or k-center methods that are top-down. In a top-down method, a data set is divided into more and more clusters. In a bottom-up approach, all the data points are treated as individual clusters to start with and gradually merged into bigger and bigger clusters.
In agglomerative clustering clusters are generated hierarchically. We start by taking every data point as a cluster. Then we merge two clusters at a time. In order to decide which two clusters to merge, we compare the pairwise distances between any two clusters and pick a pair with the minimum distance. Once we merge two clusters into a bigger one, a new cluster is created. The distances between this new cluster and the existing ones are not given. Some scheme has to be used to obtain these distances based on the two merged clusters. We call this the update of distances. Various schemes of updating distances will be described shortly.
We can keep merging clusters until all the points are merged into one cluster. A tree can be used to visualize the merging process. This tree is called a dendrogram.
The key technical detail here is how we define the between-cluster distance. At the bottom level of the dendrogram where every cluster only contains a single point, the between-cluster distance is simply the Euclidian distance between the points. (In some applications, the between-point distances are pre-given.) However, once we merge two points into a cluster how do we get the distance between the new cluster and the existing clusters?
The idea is to somehow aggregate the distances between the objects contained in the clusters.
- For clusters containing only one data point, the between-cluster distance is the between-object distance.
- For clusters containing multiple data points, the between-cluster distance is an agglomerative version of the between-object distances. There are a number of ways to accomplish this. Examples of these aggregated distances include the minimum or maximum between-object distances for pairs of objects across the two clusters.
For example, suppose we have two clusters and each one has three points. One thing we could do is to find distances between these points. In this case, there would be nine distances between pairs of points across the two clusters. The minimum (or maximum, or average) of the nine distances can be used as the distance between the two clusters.
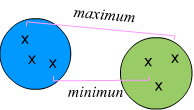
How do we decide which aggregation scheme to use? Depending on how we update the distances, dramatically different results may come up. Therefore, it is always good practice to look at the results using scatterplots or other visualization methods instead of blindly taking the output of any algorithm. Clustering is inevitably subjective since there is no gold standard.
Normally the agglomerative between-cluster distance can be computed recursively. The aggregation as explained above sounds computationally intensive and seemingly impractical. If we have two very large clusters, we have to check all the between-object distances for all pairs across the two clusters. The good news is that for many of these aggregated distances, we can update them recursively without checking all the pairs of objects. The update approach will be described soon.
Example Distances
Let's see how we would update between-cluster distances. Suppose we have two clusters r and s and these two clusters, not necessarily single point clusters, are merged into a new cluster t. Let k be any other existing cluster. We want the distance between the new cluster, t, and the existing cluster, k.
We will get this distance based on the distance between k and the two component clusters, r and s.
Because r and s have existed, the distance between r and k and the distance between s and k are already computed. Denote the distances by \(D(r, k)\) and \(D(s, k)\).
We list below various ways to get \(D(t, k)\) from \(D(r, k)\) and \(D(s, k)\).
Single-link clustering:
\(D(t, k) = min(D(r, k), D(s, k))\)
\(D(t, k)\) is the minimum distance between two objects in cluster t and k respectively. It can be shown that the above way of updating distance is equivalent to defining the between-cluster distance as the minimum distance between two objects across the two clusters.
Complete-link clustering:
\(D(t, k) = max(D(r, k), D(s, k))\)
Here, \(D(t, k)\) is the maximum distance between two objects in cluster t and k.
Average linkage clustering:
There are two cases here, the unweighted case and the weighted case.
Unweighted case:
\[D(t,k) =\frac{n_r}{n_r + n_s}D(r,k) +\frac{n_s}{n_r + n_s}D(s,k)\]
Here we need to use the number of points in cluster r and the number of points in cluster s (the two clusters that are being merged together into a bigger cluster), and compute the percentage of points in the two component clusters with respect to the merged cluster. The two distances, \(D(r, k)\) and \(D(s, k)\), are aggregated by a weighted sum.
Weighted case:
\[D(t,k)=\frac{1}{2}D(r,k) +\frac{1}{2}D(s,k)\]
Instead of using the weight proportional to the cluster size, we use the arithmetic mean. While this might look more like an unweighted case, it is actually weighted in terms of the contribution from individual points in the two clusters. When the two clusters are weighted half and half, any point (i.e., object) in the smaller cluster individually contributes more to the aggregated distance than a point in the larger cluster. In contrast, if the larger cluster is given proportionally higher weight, any point in either cluster contributes equally to the aggregated distance.
Centroid clustering:
A centroid is computed for each cluster and the distance between clusters is defined as the distance between their respective centroids.
Unweighted case:
\[D(t,k) =\frac{n_r}{n_r + n_s}D(r,k) +\frac{n_s}{n_r + n_s}D(s,k) -\frac{n_r n_s}{n_r + n_s}D(r,s)\]
Weighted case:
\[D(t,k)=\frac{1}{2}D(r,k) +\frac{1}{2}D(s,k) - \frac{1}{4}D(r,s)\]
Ward's clustering:
We update the distance using the following formula:
\[D(t,k) =\frac{n_r + n_k}{n_r + n_s+ n_k}D(r,k) +\frac{n_s+ n_k}{n_r + n_s+ n_k}D(s,k) -\frac{n_k}{n_r + n_s+ n_k}D(r,s)\]
This approach attempts to merge the two clusters for which the change in the total variation is minimized. The total variation of a clustering result is defined as the sum of squared-errors between every object and the centroid of the cluster it belongs to.
The dendrogram generated by single-linkage clustering tends to look like a chain. Clusters generated by complete-linkage may not be well separated. Other methods are often intermediate between the two.

