2.5 - The Coefficient of Determination, r-squared
Let's start our investigation of the coefficient of determination, r2, by looking at two different examples — one example in which the relationship between the response y and the predictor x is very weak and a second example in which the relationship between the response y and the predictor x is fairly strong. If our measure is going to work well, it should be able to distinguish between these two very different situations.
Here's a plot illustrating a very weak relationship between y and x. There are two lines on the plot, a horizontal line placed at the average response, \(\bar{y}\), and a shallow-sloped estimated regression line, \(\hat{y}\). Note that the slope of the estimated regression line is not very steep, suggesting that as the predictor x increases, there is not much of a change in the average response y. Also, note that the data points do not "hug" the estimated regression line:
|
|
\(SSR=\sum_{i=1}^{n}(\hat{y}_i-\bar{y})^2=119.1\) \(SSE=\sum_{i=1}^{n}(y_i-\hat{y}_i)^2=1708.5\) \(SSTO=\sum_{i=1}^{n}(y_i-\bar{y})^2=1827.6\) |
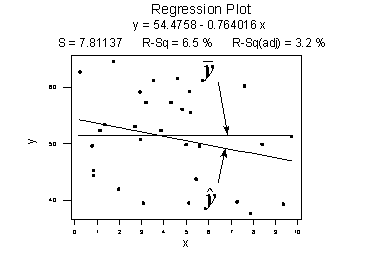
The calculations on the right of the plot show contrasting "sums of squares" values:
- SSR is the "regression sum of squares" and quantifies how far the estimated sloped regression line, \(\hat{y}_i\), is from the horizontal "no relationship line," the sample mean or \(\bar{y}\).
- SSE is the "error sum of squares" and quantifies how much the data points, \(y_i\), vary around the estimated regression line, \(\hat{y}_i\).
- SSTO is the "total sum of squares" and quantifies how much the data points, \(y_i\), vary around their mean, \(\bar{y}\).
Note that SSTO = SSR + SSE. The sums of squares appear to tell the story pretty well. They tell us that most of the variation in the response y (SSTO = 1827.6) is just due to random variation (SSE = 1708.5), not due to the regression of y on x (SSR = 119.1). You might notice that SSR divided by SSTO is 119.1/1827.6 or 0.065. Do you see where this quantity appears on the above fitted line plot?
Contrast the above example with the following one in which the plot illustrates a fairly convincing relationship between y and x. The slope of the estimated regression line is much steeper, suggesting that as the predictor x increases, there is a fairly substantial change (decrease) in the response y. And, here, the data points do "hug" the estimated regression line:
|
|
\(SSR=\sum_{i=1}^{n}(\hat{y}_i-\bar{y})^2=6679.3\) \(SSE=\sum_{i=1}^{n}(y_i-\hat{y}_i)^2=1708.5\) \(SSTO=\sum_{i=1}^{n}(y_i-\bar{y})^2=8487.8\) |
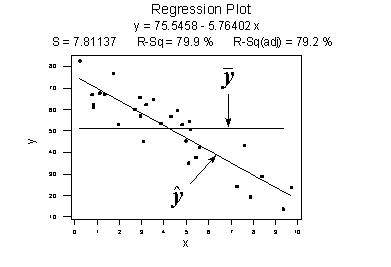
The sums of squares for this dataset tell a very different story, namely that most of the variation in the response y (SSTO = 8487.8) is due to the regression of y on x (SSR = 6679.3) not just due to random error (SSE = 1708.5). And, SSR divided by SSTO is 6679.3/8487.8 or 0.799, which again appears on the fitted line plot.
The previous two examples have suggested how we should define the measure formally. In short, the "coefficient of determination" or "r-squared value," denoted r2, is the regression sum of squares divided by the total sum of squares. Alternatively, as demonstrated in this screencast below, since SSTO = SSR + SSE, the quantity r2 also equals one minus the ratio of the error sum of squares to the total sum of squares:
\[r^2=\frac{SSR}{SSTO}=1-\frac{SSE}{SSTO}\]
Here are some basic characteristics of the measure:
- Since r2 is a proportion, it is always a number between 0 and 1.
- If r2 = 1, all of the data points fall perfectly on the regression line. The predictor x accounts for all of the variation in y!
- If r2 = 0, the estimated regression line is perfectly horizontal. The predictor x accounts for none of the variation in y!
We've learned the interpretation for the two easy cases — when r2 = 0 or r2 = 1 — but, how do we interpret r2 when it is some number between 0 and 1, like 0.23 or 0.57, say? Here are two similar, yet slightly different, ways in which the coefficient of determination r2 can be interpreted. We say either:
"r2 ×100 percent of the variation in y is reduced by taking into account predictor x"
or:
"r2 ×100 percent of the variation in y is "explained by" the variation in predictor x."
Many statisticians prefer the first interpretation. I tend to favor the second. The risk with using the second interpretation — and hence why "explained by" appears in quotes — is that it can be misunderstood as suggesting that the predictor x causes the change in the response y. Association is not causation. That is, just because a dataset is characterized by having a large r-squared value, it does not imply that x causes the changes in y. As long as you keep the correct meaning in mind, it is fine to use the second interpretation. A variation on the second interpretation is to say, "r2 ×100 percent of the variation in y is accounted for by the variation in predictor x."
Students often ask: "what's considered a large r-squared value?" It depends on the research area. Social scientists who are often trying to learn something about the huge variation in human behavior will tend to find it very hard to get r-squared values much above, say 25% or 30%. Engineers, on the other hand, who tend to study more exact systems would likely find an r-squared value of just 30% unacceptable. The moral of the story is to read the literature to learn what typical r-squared values are for your research area!
Let's revisit the skin cancer mortality example (skincancer.txt). Any statistical software that performs simple linear regression analysis will report the r-squared value for you, which in this case is 67.98% or 68% to the nearest whole number.
We can say that 68% of the variation in the skin cancer mortality rate is reduced by taking into account latitude. Or, we can say — with knowledge of what it really means — that 68% of the variation in skin cancer mortality is "explained by" latitude.

