9.4 - Nearest-Neighbor Methods
The Nearest Neighbor Classifier
Training data: \((g_i, x_i)\), \(i=1,2,\ldots,N\).
- Define distance on input x, e.g. Euclidian distance.
- Classify new instance by looking at label of closest sample in the training set: \(\hat{G}(x^*) = argmin_i d(x_i, x^*)\).
Problem: Over fitting
It is easy to overfit data. For example, assume we know that the data generating process has a linear boundary, but there is some random noise to our measurements.

Solution: Smoothing
To prevent overfitting, we can smooth the decision boundary by K nearest neighbors instead of 1.
Find the K training samples \(x_r\), \(r = 1, \ldots , K\) closest in distance to \(x^*\), and then classify using majority vote among the k neighbors.
The amount of computation can be intense when the training data is large since the distance between a new data point and every training point has to be computed and sorted.
Feature standardization is often performed in pre-processing. Because standardization affects the distance, if one wants the features to play a similar role in determining the distance, standardization is recommended. However, whether to apply normalization is rather subjective. One has to decide on an individual basis for the problem in consideration.
The only parameter that can adjust the complexity of KNN is the number of neighbors k. The larger k is, the smoother the classification boundary. Or we can think of the complexity of KNN as lower when k increases.
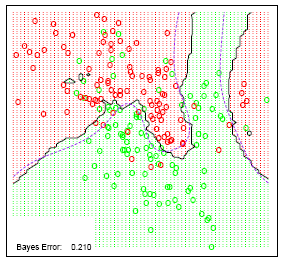
The classification boundaries generated by a given training data set and 15 Nearest Neighbors are shown below. As a comparison, we also show the classification boundaries generated for the same training data but with 1 Nearest Neighbor. We can see that the classification boundaries induced by 1 NN are much more complicated than 15 NN.
15 Nearest Neighbors (below)
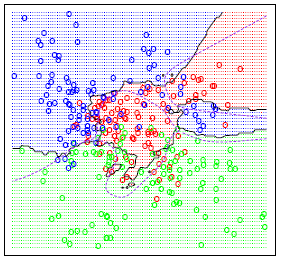
Figure 13.3 k-nearest-neighbor classifiers applied to the simulation data of figure 13.1. The broken purple curve in the background is the Bayes decision boundary.
1 Nearest Neighbor (below)
For another simulated data set, there are two classes. The error rates based on the training data, the test data, and 10 fold cross validation are plotted against K, the number of neighbors. We can see that the training error rate tends to grow when k grows, which is not the case for the error rate based on a separate test data set or cross-validation. The test error rate or cross-validation results indicate there is a balance between k and the error rate. When k first increases, the error rate decreases, and it increases again when k becomes too big. Hence, there is a preference for k in a certain range.
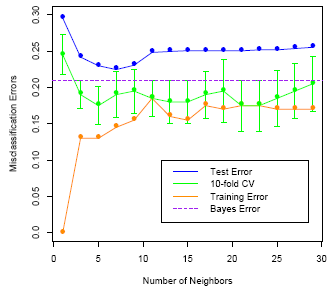
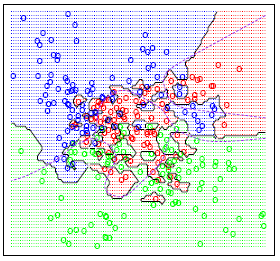
Figure 13.4 k-nearest-neighbors on the two-class mixture data. The upper panel shows the misclassification errors as a function of neighborhood size. Standard error bars are included for 10-fold cross validation. The lower panel shows the decision boundary for 7-nearest neighbors, which appears to be optimal for minimizing test error. The broken purple curve in the background is the Bayes decision boundary.
7 Nearest Neighbors (below)