11.1 - Construct the Tree
Notation
We will denote the feature space by \(\mathbf{X}\). Normally \(\mathbf{X}\) is a multidimensional Euclidean space. However, sometimes some variables (measurements) may be categorical such as gender, (male or female). CART has the advantage of treating real variables and categorical variables in a unified manner. This is not so for many other classification methods, for instance, LDA.
The input vector is indicated by \(X \in \mathbf{X}\) contains p features \(X_1, X_2, \cdots , X_p\).
Tree structured classifiers are constructed by repeated splits of the space X into smaller and smaller subsets, beginning with X itself.
We will also need to introduce a few additional definitions:
Rollover the definitions on the right in the interactive image below:
node, terminal node (leaf node), parent node, child node.
One thing that we need to keep in mind is that the tree represents recursive splitting of the space. Therefore, every node of interest corresponds to one region in the original space. Two child nodes will occupy two different regions and if we put the two together, we get the same region as that of the parent node. In the end, every leaf node is assigned with a class and a test point is assigned with the class of the leaf node it lands in.
Additional Notation:
- A node is denoted by t. We will also denote the left child node by \(t_L\) and the right one by \(t_R\) .
- Denote the collection of all the nodes in the tree by T and the collection of all the leaf nodes by \(\tilde{T}\).
- A split will be denoted by s. The set of splits is denoted by S.
Let's take a look at how these splits can take place.
The whole space is represented by X.
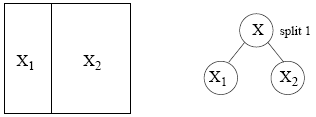
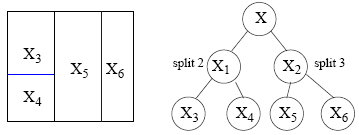
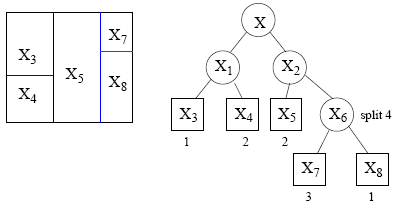
![]()
The Three Elements
The construction of a tree involves the following three general elements:
- The selection of the splits, i.e., how do we decide which node (region) to split and how to split it?
- If we know how to make splits or 'grow' the tree, how do we decide when to declare a node terminal and stop splitting?
- We have to assign each terminal node to a class. How do we assign these class labels?
In particular, we need to decide upon the following:
- The pool of candidate splits that we might select from involves a set Q of binary questions of the form {Is \(\mathbf{x} \in A\)?}, \(A \subseteq \mathbf{X}\). Basically, we ask whether our input \(\mathbf{x}\) belongs to a certain region, A. We need to pick one A from the pool.
- The candidate split is evaluated using a goodness of split criterion \(\Phi(s, t)\) that can be evaluated for any split s of any node t.
- A stop-splitting rule, i.e., we have to know when it is appropriate to stop splitting. One can 'grow' the tree very big. In an extreme case, one could 'grow' the tree to the extent that in every leaf node there is only a single data point. Then it makes no sense to split any farther. In practice, we often don't go that far.
- Finally, we need a rule for assigning every terminal node to a class.
Now, let's get into the details for each of these four decisions that we have to make...
1) Standard Set of Questions for Suggesting Possible Splits
Let's say that the input vector \(X = (X_1, X_2, \cdots , X_p)\) contains features of both categorical and ordered types. CART makes things simple because every split depends on the value of only a single variable.
If we have an ordered variable - for instance \(X_j\) – the question inducing the split is whether \(X_j\) is smaller or equal to some threshold? Thus, for each ordered variable \(X_j\) , Q includes all questions of the form:
{Is \(X_j \leq c\)?}
for all real-valued c.
There are other ways to partition the space. For instance, you might ask whether \(X_1+ X_2\) is smaller than some threshold. In this case, the split line is not parallel to the coordinates. However, here we restrict our interest to the questions of the above format. Every question involves one of \(X_1, \cdots , X_p\), and a threshold.
Since the training data set is finite, there are only finitely many thresholds c that result in distinct division of the data points.
If Xj is categorical, say taking values from {1, 2, ... , M}, the questions Q, are of the form:
{Is \(X_j \in A\)?}.
where A is any subset of {1, 2, ... , M}.
The splits or questions for all p variables form the pool of candidate splits.
This first step identifies all the candidate questions. Which one to use at any node when constructing the tree is the next question ...
2) Determining Goodness of Split
The way we choose the question, i.e., split, is to measure every split by a 'goodness of split' measure, which depends on the split question as well as the node to split. The 'goodness of split' in turn is measured by an impurity function.
Intuitively, when we split the points we want the region corresponding to each leaf node to be "pure", that is, most points in this region come from the same class, that is, one class dominates.
Look at the following example. We have two classes shown in the plot by x's and o's. We could split first by checking whether the horizontal variable is above or below a threshold, shown below:
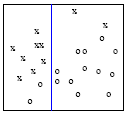
The split is indicated by the blue line. Remember by the nature of the candidate splits, the regions are always split by lines parallel to either coordinate. For the example split above, we might consider it a good split because the left-hand side is nearly pure in that most of the points belong to the x class. Only two points belong to the o class. The same is true of the right-hand side.
Generating pure nodes is the intuition for choosing a split at every node. If we go one level deeper down the tree, we have created two more splits, shown below:
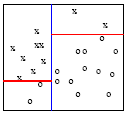
now you see that the upper left region or leaf node contains only the x class. Therefore, it is 100% pure, no class blending in this region. The same is true for the lower right region. It only has o's. Once we have reached this level, it is unnecessary to further split because all the leaf regions are 100% pure. Additional splits will not make the class separation any better in the training data, although it might make a difference with the unseen test data.

