11.2 - The Impurity Function
The impurity function measures the extent of purity for a region containing data points from possibly different classes. Suppose the number of classes is K. Then the impurity function is a function of \(p_1, \cdots , p_K\) , the probabilities for any data point in the region belonging to class 1, 2,..., K. During training, we do not know the real probabilities. What we would use is the percentage of points in class 1, class 2, class 3, and so on, according to the training data set.
The impurity function can be defined in different ways, but the bottom line is that it satisfies three properties.
Definition: An impurity function is a function \(\Phi\) defined on the set of all K-tuples of numbers \((p_1, \cdots , p_K)\) satisfying \(p_j \geq 0,\;\; j =1, \cdots , K, \Sigma_j p_j = 1\) with the properties:
- \(\Phi\) achieves maximum only for the uniform distribution, that is all the pj are equal.
- \(\Phi\) achieves minimum only at the points (1, 0, ... , 0), (0, 1, 0, ... , 0), ..., (0, 0, ... , 0, 1), i.e., when the probability of being in a certain class is 1 and 0 for all the other classes.
- \(\Phi\) is a symmetric function of \(p_1, \cdots , p_K\), i.e., if we permute \(p_j\) , \(\Phi\) remains constant.
Definition: Given an impurity function \(\Phi\), define the impurity measure, denoted as i(t), of a node t as follows:
\[i(t)=\phi(p(1|t), p(2|t), ... , p(K|t)) \]
where p(j | t) is the estimated posterior probability of class j given a point is in node t. This is called the impurity function or the impurity measure for node t.
Once we have i(t), we define the goodness of split s for node t, denoted by \(\Phi\)(s, t):
\[\Phi(s, t) =\Delta i(s, t) = i(t) - p_Ri(t_R)-p_L i(t_L) \]
Δi(s, t) is the difference between the impurity measure for node t and the weighted sum of the impurity measures for the right child and the left child nodes. The weights, \(p_R\) and \(p_L\) , are the proportions of the samples in node t that go to the right node \(t_R\) and the left node \(t_L\) respectively.
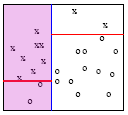 Look at the graphic again. Suppose the region to the left (shaded purple) is the node being split, the upper portion is the left child node the lower portion is the right child node. You can see that the proportion of points that are sent to the left child node is \( p_L = 8/10 \). The proportion sent to the right child is \(p_R = 2/10\).
Look at the graphic again. Suppose the region to the left (shaded purple) is the node being split, the upper portion is the left child node the lower portion is the right child node. You can see that the proportion of points that are sent to the left child node is \( p_L = 8/10 \). The proportion sent to the right child is \(p_R = 2/10\).
The classification tree algorithm goes through all the candidate splits to select the best one with maximum Δi(s, t).
Next, we will define I(t) = i(t) p(t), that is, the impurity function of node t weighted by the estimated proportion of data that go to node t. p(t) is the probability of data falling into the region corresponding to node t. A simple way to estimate it is to count the number of points that are in node t and divide it by the total number of points in the whole data set.
The aggregated impurity measure of tree T, I(T) is defined by
\[I(T)=\sum_{t \in \tilde{T}}I(t)=\sum_{t \in \tilde{T}}i(t)p(t)\]
This is a sum over all of the leaf nodes. (Remember, not all of the nodes in the tree, just the leaf nodes: \(\tilde{T}\).)
Note for any node t the following equations hold:
\[ \begin {align}& p(t_L) + p(t_R)=p(t) \\
&p_L=p(t_L)/p(t) \\
&p_R=p(t_R)/p(t) \\
&p_L+p_R=1 \\
\end {align} \]
The region covered by the left child node, \(t_L\), and the right child node, \(t_R\), are disjoint and if combined, form the bigger region of their parent node t. The sum of the probabilities over two disjoined sets is equal to the probability of the union. \(p_L\) then becomes the relative proportion of the left child node with respect to the parent node.
Next, we define the difference between the weighted impurity measure of the parent node and the two child nodes.
\[ \begin {align}\Delta I(s,t)& = I(t)-I(t_L)-I(t_R)\\
& = p(t)i(t) -p(t_L)i(t_L)-p(t_R)i(t_R)\\
& = p(t)i(t) -p_L i(t_L)-p_Ri(t_R) \\
& = p(t)\Delta i(s,t) \\
\end {align} \]
Finally getting to this mystery of the impurity function...
It should be understood that no matter what impurity function we use, the way you use it in a classification tree is the same. The only difference is what specific impurity function to plug in. Once you use this, what follows is the same.
Possible impurity functions:
- Entropy function: \(\sum_{j=1}^{K}p_j \text{ log }\frac{1}{p_j}\). If pj = 0, use the limit \(\text{lim }p_j \rightarrow \text{ log }p_j=0\).
- Misclassification rate: \(1 - max_j p_j \).
- Gini index: \(\sum_{j=1}^{K}p_j (1-p_j)=1-\sum_{j=1}^{K}p_{j}^{2}\).
Remember, impurity functions have to 1) achieve a maximum at the uniform distribution, 2) achieve a minimum when \(p_j = 1\), and 3) be symmetric with regard to their permutations.
Another Approach: The Twoing Rule
Another splitting method is the Twoing Rule. This approach does not have anything to do with the impurity function.
The intuition here is that the class distributions in the two child nodes should be as different as possible and the proportion of data falling into either of the child nodes should be balanced.
The twoing rule: At node t, choose the split s that maximizes:
\[\frac{p_L p_R}{4}\left[\sum_{j}|p(j|t_L)-p(j|t_R)| \right]^2\]
When we break one node to two child nodes, we want the posterior probabilities of the classes to be as different as possible. If they differ a lot, each tends to be pure. If instead the proportions of classes in the two child nodes are roughly the same as the parent node, this indicates the splitting does not make the two child nodes much purer than the parent node and hence not a successful split.
In summary, one can use either the goodness of split defined using the impurity function or the twoing rule. At each node, try all possible splits exhaustively and select the best from them.

