11.8 - Right Sized Tree via Pruning
In the previous section we talked about growing trees. In this section, we will discuss pruning trees.
Let the expected misclassification rate of a tree \(T\) be \(R^*(T)\).
Recall we used the resubstitution estimate for \(R^*(T)\). This is:
\[R(T)=\sum_{t \in \tilde{T}}r(t)p(t)=\sum_{t \in \tilde{T}}R(t) \]
Remember also that r(t) is the probability of making a wrong classification for points in node t. For a point in a given leaf node t, the estimated probability of misclassification is 1 minus the probability of the majority class in node t based on the training data.
To get the probability of misclassification for the whole tree, a weighted sum of the within leaf node error rate is computed according to the total probability formula.
We also mentioned in the last section the resubstitution error rate \(R(T)\) is biased downward. Specifically, we proved the weighted mis-classification rate for the parent node is guaranteed to be greater or equal to the sum of the weighted misclassification rates of the left and right child nodes, that is:
\[R(t) \geq R(t_L) + R(t_R)\]
This means that if we simply minimize the resubstitution error rate, we would always prefer a bigger tree. There is no defense against overfitting.
Let's look at the digit recognition example that we discussed before.
The biggest tree grown using the training data is of size 71. In other words, it has 71 leaf nodes. The tree is grown until all of the points in every leaf node are from the same class.
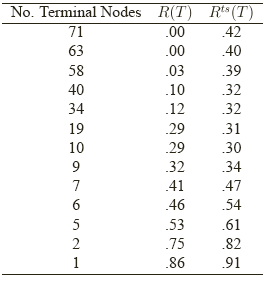
Then a pruning procedure is applied, (the details of this process we will get to later). We can see from the above table that the tree is gradually pruned. The tree next to the full tree has 63 leaf nodes, which is followed by a tree with 58 leaf nodes, so on so forth until only one leaf node is left. This minimum tree contains only a single node, the root.
The resubstitution error rate \(R(T)\) becomes monotonically larger when the tree shrinks.
The error rate \(R^{ts}\) based on a separate test data shows a different pattern. It decreases first when the tree becomes larger, hits minimum at the tree with 10 terminal nodes, and begins to increase when the tree further grows.
Comparing with \(R(T)\), \(R^{ts}(T)\) better reflects the real performance of the tree. The minimum \(R^{ts}(T)\) is achieved not by the biggest tree, but by a tree that better balances the resubstitution error rate and the tree size.

