In Lesson 4.1, Example 3 described the analysis of monthly flow data for a Colorado River location. An ARIMA(1,0,0)×(0,1,1)12 was identified and estimated. In the first part of this lesson, you’ll see the R code and output for that analysis. (Lesson 4.1 gave Minitab output.)
Example 4-3: Revisited Section
R code for the Colorado River Analysis
The data are in the file coloradoflow.dat. We used scripts in the library(Stoffer’s routines as described in Lessons 1 & 3), so the first two lines of code are:
library(astsa)
flow <- ts(scan("coloradoflow.dat"))
The first step in the analysis is to plot the time series. The command is:
plot(flow, type="b")
The plot showed clear monthly effects and no obvious trend, so we examined the ACF and PACF of the 12th differences (seasonal differencing). Commands are:
diff12 = diff(flow,12)
acf2(diff12, 48)
The acf2 command asks for information about 48 lags. On the basis of the ACF and PACF of the 12th differences, we identified an ARIMA(1,0,0)×(0,1,1)12 model as a possibility (See Lesson 4.1). The command for fitting this model is
sarima(flow, 1,0,0,0,1,1,12)
The parameters of the command just given are the data series, the non-seasonal specification of AR, differencing, and MA, and then the seasonal specification of seasonal AR, seasonal differencing, seasonal MA, and period or span for the seasonality.
Output from the sarima command is:
Final Estimates of Parameters
| Type | Coef | SE Coef | T | P |
|---|---|---|---|---|
| AR 1 | 0.5149 | 0.0353 | 14.60 | 0.000 |
| SMA 12 | -0.8828 | 0.0237 | -37.25 | 0.000 |
| Constant | -0.0011 | 0.0007 | -1.63 | 0.103 |
sigma^2 estimated as 0.4681: log likelihood = -620.38, aic = 1248.76
$degrees_of_freedom
[1] 585
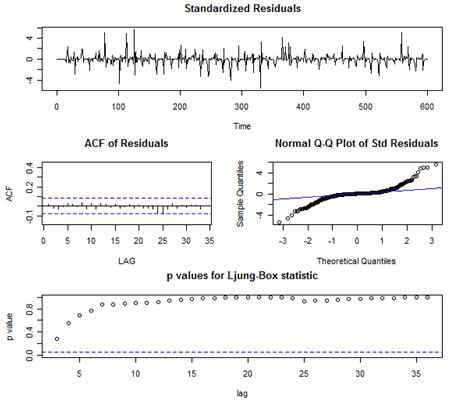
The output included these residual plots. The only difficulty we see is in the normal probability plot. The extreme standardized sample residuals (on both ends) are larger than they would be for normally distributed data. This could be related to the non-constant variance noted in Lesson 4.1.
We didn’t generate any forecasts in Lesson 4.1, but if we were to use R to generate forecasts for the next 24 months in R, one command that could be used is
sarima.for(flow, 24, 1,0,0,0,1,1,12)
The order of parameters in the command is the name of the data series, the number of times for which we want forecasts, followed by the parameters of the ARIMA model.
Partial output for the forecast command follows (We skipped giving the standard errors.)
$pred
Time Series:
Start = 601
End = 624
Frequency = 1
[1] 0.3013677 0.3243119 0.5676440 1.2113713 2.7631409 3.5326281
[7] 1.3931886 0.5971816 0.3294376 0.4161899 0.4180578 0.3186012
[13] 0.2838731 0.3088276 0.5531948 1.1974552 2.7494992 3.5191278
[19] 1.3797610 0.5837915 0.3160668 0.4028290 0.4047020 0.3052481
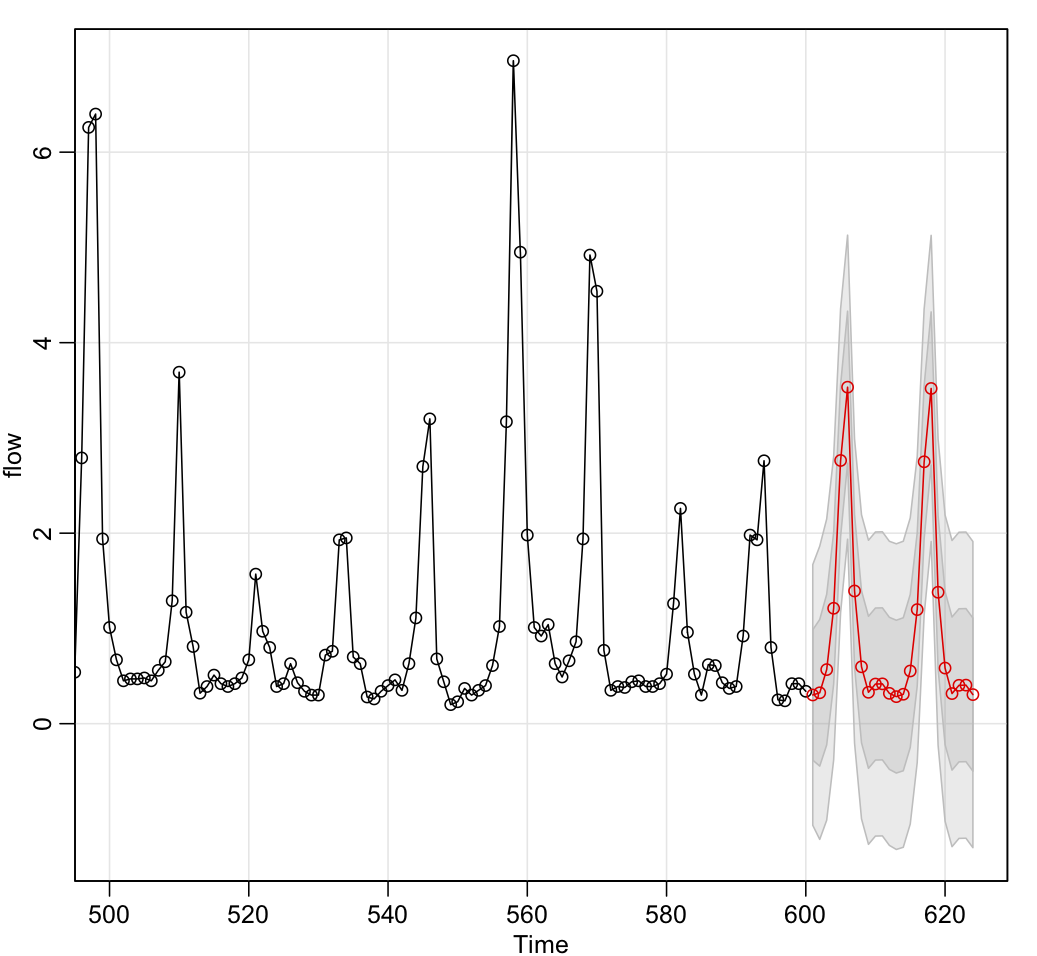
Note that the lower limits of some prediction intervals are negative - impossible for the flow of a river. In practice, we might truncate these lower limits to 0 when presenting them.
If you were to use R’s native commands to do the fit and forecasts, the commands might be:
themodel = arima(flow, order = c(1,0,0), seasonal = list(order = c(0,1,1), period = 12))
themodel
predict(themodel, n.ahead=24)
The first command does the arima and stores results in an “object” called “themodel.” The second command, which is simply themodel, lists the results and the final command generates forecasts for 24 times ahead.
In Lesson 4.1, we presented a graph of the monthly means to make the case that the data are seasonal. The R commands are:
flowm = matrix(flow, ncol=12,byrow=TRUE)
col.means=apply(flowm,2,mean)
plot(col.means,type="b", main="Monthly Means Plot for Flow", xlab="Month", ylab="Mean")
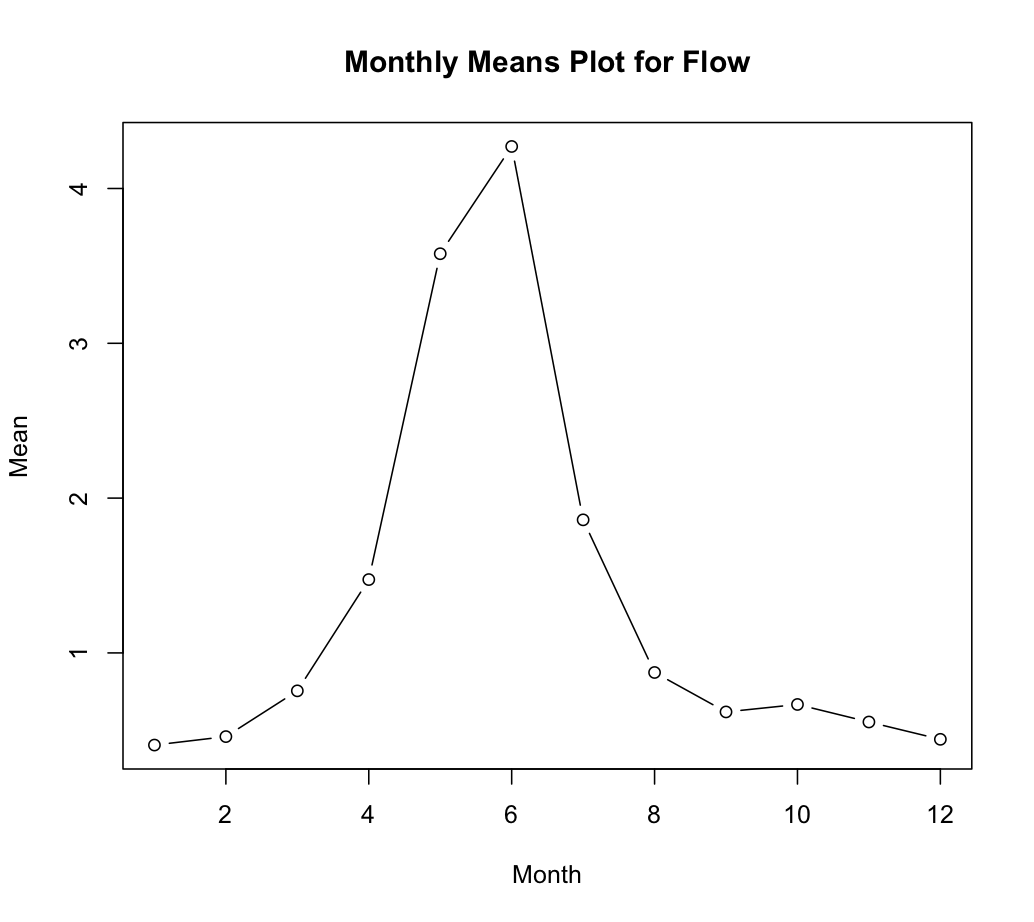
Example 4-4: Beer Production in Australia Section
In Lesson 1.1, this plot for quarterly beer production in Australia was given.
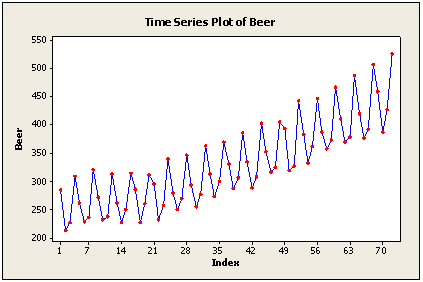
There is an upward trend and seasonality. The regular pattern of ups and downs is an indicator of seasonality. If you count points, you’ll see that the 4th quarter of a year is the high point, the 2nd and 3rd quarters are low points, and the 1st quarter value falls in between.
With trend and quarterly seasonality we will likely need both a first and a fourth difference. The plot above was produced in Minitab, but we’ll use R for the rest of this example. The commands for creating the differences and graphing the ACF and PACF of these differences are:
diff4 = diff(beer, 4)
diff1and4 = diff(diff4,1)
acf2(diff1and4,24)
When we read the data, we called the series “beer” and also loaded the astsa library.
Let's examine the TS plot and ACF/PACF of seasonal differences, diff4, to determine whether or not first differences are also necessary.
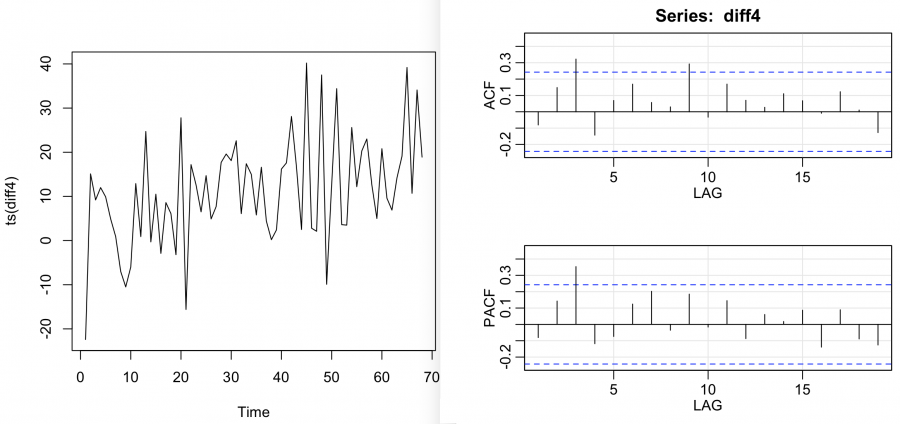
The TS plot still shows that the upward trend remains, however the ACF/PACF do not suggest the need to difference further. In this case, we could detrend by subtracting an estimated linear trend from each observation as follows:
dtb=residuals(lm (diff4~time(diff4)))
acf2(dtb)
The ACF and PACF of the detrended seasonally differenced data follow. The interpretation:
- Non-seasonal: Looking at just the first 2 or 3 lags, either a MA(1) or AR(1) might work based on the similar single spike in the ACF and PACF, if at all. Both terms are also possible with an ARMA(1,1), but with both cutting off immediately, this is less likely than a single order model. With S=4, the nonseasonal aspect can sometimes be difficult to interpret in such a narrow window.
- Seasonal: Look at lags that are multiples of 4 (we have quarterly data). Not much is going on there, although there is a (barely) significant spike in the ACF at lag 4 and a somewhat confusing spike at lag 9 (in ACF). Nothing significant is happening at the higher lags. Maybe a seasonal MA(1) or MA(2) might work.
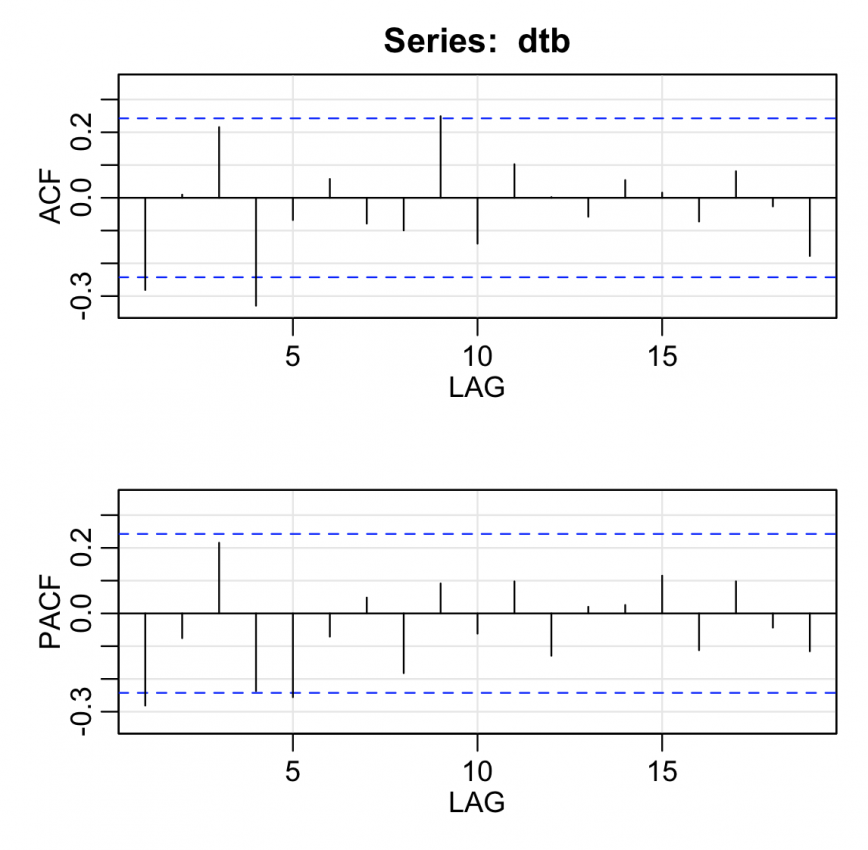
We tried a few models. An initial guess was ARIMA(0,0,1)×(0,1,1)4, which wasn’t a bad guess. We also tried ARIMA(1,0,0)×(0,1,1)4, ARIMA(1,0,1)×(0,1,1)4, and ARIMA(1,0,0)×(0,1,2)4.
The commands for the 4 models are:
sarima (dtb, 0,0,1,0,0,1,4)
sarima (dtb, 1,0,0,0,0,1,4)
sarima (dtb, 0,0,0,0,0,1,4)
sarima (dtb, 1,0,0,0,0,2,4)
A summary of the results:
| Model | MSE | Sig. of coefficients | AIC | ACF of residuals |
|---|---|---|---|---|
| ARIMA(0,0,1)×(0,1,1)4 | 89.03 | Only the Seasonal MA is sig. | 508.25 | OK |
| ARIMA(1,0,0)×(0,1,1)4 | 88.73 | Only the Seasonal MA is sig. | 507.97 | OK |
| ARIMA(0,0,0)×(0,1,1)4 | 92.17 | Only the Seasonal MA is sig. | 509.19 | Slight concern at lag 1, though not significant |
| ARIMA(1,0,0)×(0,1,2)4 | 86.93 | Only the Seasonal MA is sig. | 509.05 | OK |
All models are quite close, though the second model is the best in terms of AIC and residual autocorrelation and might be worth keeping the marginally significant AR(1) term. The fourth model surprisingly comes through with a slightly lower MSE than the second, though the AIC and simplicity of the second model seems the best choice.
There are a number of tests to help assess the need for differencing because it is not always obvious. The augmented Dickey-Fuller (ADF) test and the KPSS test are two common choices. The ADF tests the null hypothesis that the data are not stationary, more specifically that the process contains a unit root. When we fail to reject the null, then this suggests the need to difference. The KPSS test reverses the null and alternative hypothesis of the ADF test. If the KPSS test rejects, then the alternative would be to conclude that the data are not stationary and to take first differences. Both tests are available in the R package tseries.
You may wish to examine this model with first and fourth differences. Differencing twice usually removes any drift from the model and so sarima does not fit a constant when d=1 and D=1. In this case you may difference within the sarima command, e.g. sarima(x,1,1,1,0,1,1,S). However there are cases, when drift remains after differencing twice and so you must difference outside of the sarima command to fit a constant. It seems the safest choice is to difference outside of the sarima command to first verify that the drift is gone.