So far, we have learned various measures for identifying extreme x values (high-leverage observations) and unusual y values (outliers). When trying to identify outliers, one problem that can arise is when there is a potential outlier that influences the regression model to such an extent that the estimated regression function is "pulled" towards the potential outlier, so that it isn't flagged as an outlier using the standardized residual criterion. To address this issue, deleted residuals offer an alternative criterion for identifying outliers. The basic idea is to delete the observations one at a time, each time refitting the regression model on the remaining n–1 observation. Then, we compare the observed response values to their fitted values based on the models with the ith observation deleted. This produces (unstandardized) deleted residuals. Standardizing the deleted residuals produces studentized deleted residuals, also known as externally studentized residuals.
(Unstandardized) deleted residuals
If we let:
- \(y_{i}\) denote the observed response for the \(i^{th}\) observation, and
- \(\hat{y}_{(i)}\) denote the predicted response for the \(i^{th}\) observation based on the estimated model with the \(i^{th}\) observation deleted
then the \(i^{th}\) (unstandardized) deleted residual is defined as:
\(d_i=y_i-\hat{y}_{(i)}\)
Why this measure? Well, data point i being influential implies that the data point "pulls" the estimated regression line towards itself. In that case, the observed response would be close to the predicted response. But, if you removed the influential data point from the data set, then the estimated regression line would "bounce back" away from the observed response, thereby resulting in a large deleted residual. That is, a data point having a large deleted residual suggests that the data point is influential.
Example 11-5 Section
Consider the following plot of n = 4 data points (3 blue and 1 red):
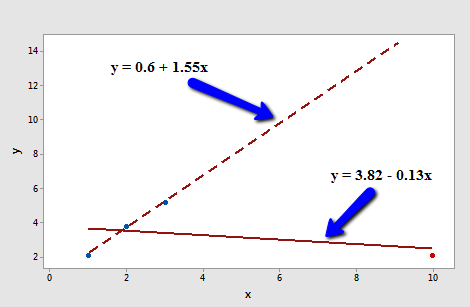
The solid line represents the estimated regression line for all four data points, while the dashed line represents the estimated regression line for the data set containing just the three data points — with the red data point omitted. Observe that, as expected, the red data point "pulls" the estimated regression line towards it. When the red data point is omitted, the estimated regression line "bounces back" away from the point.
Let's determine the deleted residual for the fourth data point — the red one. The value of the observed response is \(y_{4} \) = 2.1. The estimated regression equation for the data set containing just the first three points is:
\(\hat{y}_{(4)}=0.6+1.55x\)
making the predicted response when x = 10:
\(\hat{y}_{(4)}=0.6+1.55(10)=16.1\)
Therefore, the deleted residual for the red data point is:
\(d_4=2.1-16.1=-14\)
Is this a large deleted residual? Well, we can tell from the plot in this simple linear regression case that the red data point is clearly influential, and so this deleted residual must be considered large. But, in general, how large is large? Unfortunately, there's not a straightforward answer to that question. Deleted residuals depend on the units of measurement just as ordinary residuals do. We can solve this problem though by dividing each deleted residual by an estimate of its standard deviation. That's where "studentized deleted residuals" come into play.
Studentized deleted residuals (or externally studentized residuals) Section
A studentized deleted (or externally studentized) residual is:
\(t_i=\dfrac{d_i}{s(d_i)}=\dfrac{e_i}{\sqrt{MSE_{(i)}(1-h_{ii})}}\)
That is, a studentized deleted (or externally studentized) residual is just an (unstandardized) deleted residual divided by its estimated standard deviation (first formula). This turns out to be equivalent to the ordinary residual divided by a factor that includes the mean square error based on the estimated model with the \(i^{th}\) observation deleted, \(MSE_{ \left(i \right) }\), and the leverage, \(h_{ii} \) (second formula). Note that the only difference between the externally studentized residuals here and the internally studentized residuals considered in the previous section is that internally studentized residuals use the mean square error for the model based on all observations, while externally studentized residuals use the mean square error based on the estimated model with the \(i^{th}\) observation deleted, \(MSE_{ \left(i \right) }\).
Another formula for studentized deleted (or externally studentized) residuals allows them to be calculated using only the results for the model fit to all the observations:
\(t_i=r_i \left( \dfrac{n-p-1}{n-p-r_{i}^{2}}\right) ^{1/2},\)
where \(r_i\) is the \(i^{th}\) internally studentized residual, n = the number of observations, and p = the number of regression parameters including the intercept.
In general, externally studentized residuals are going to be more effective for detecting outlying Y observations than internally studentized residuals. If an observation has an externally studentized residual that is larger than 3 (in absolute value) we can call it an outlier. (Recall from the previous section that some use the term "outlier" for an observation with an internally studentized residual that is larger than 3 in absolute value. To avoid any confusion, you should always clarify whether you're talking about internally or externally studentized residuals when designating an observation to be an outlier.)
Example 11-6 Section
Let's return to our example with n = 4 data points (3 blue and 1 red):
Regressing y on x and requesting the studentized deleted (or externally studentized)) residuals (which Minitab simply calls "deleted residuals"), we obtain the following Minitab output:
| x | y | RESI | TRES |
|---|---|---|---|
| 1 | 2.1 | -1.59 | -1.7431 |
| 2 | 3.8 | 0.24 | 0.1217 |
| 3 | 5.2 | 1.77 | 1.6361 |
| 10 | 2.1 | -0.42 | -19.7990 |
As you can see, the studentized deleted residual ("TRES") for the red data point is \(t_4 = -19.7990\). Now we just have to decide if this is large enough to deem the data point influential. To do that we rely on the fact that, in general, studentized deleted residuals follow a t distribution with ((n-1)-p) degrees of freedom (which gives them yet another name: "deleted t residuals"). That is, all we need to do is compare the studentized deleted residuals to the t distribution with ((n-1)-p) degrees of freedom. If a data point's studentized deleted residual is extreme—that is, it sticks out like a sore thumb—then the data point is deemed influential.
Here, n = 4 and p = 2. Therefore, the t distribution has 4 - 1 - 2 = 1 degree of freedom. Looking at a plot of the t distribution with 1 degree of freedom:
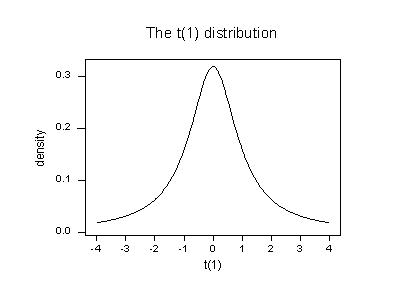
we see that almost all of the t values for this distribution fall between -4 and 4. Three of the studentized deleted residuals — -1.7431, 0.1217, and, 1.6361 — are all reasonable values for this distribution. But, the studentized deleted residual for the fourth (red) data point — -19.799 — sticks out like a very sore thumb. It is "off the chart" so to speak. Based on studentized deleted residuals, the red data point is deemed influential.
Example 11-2 Revisited Section
Let's return to Example #2 (Influence2 data set):
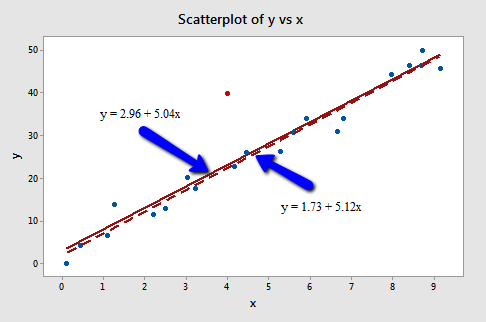
Regressing y on x and requesting the studentized deleted residuals, we obtain the following Minitab output:
| Row | x | y | RESI | SRES | TRES |
|---|---|---|---|---|---|
| 1 | 0.10000 | -0.0716 | -3.5330 | -0.82635 | -0.81917 |
| 2 | 0.45401 | 4.1673 | -1.0773 | -0.24915 | -0.24291 |
| 3 | 1.09765 | 6.5703 | -1.9166 | -0.43544 | -0.42596 |
| ... | |||||
| 19 | 8.70156 | 46.5475 | -0.2429 | -0.05562 | -0.05414 |
| 20 | 9.16463 | 45.7762 | -3.3468 | -0.77680 | -0.76838 |
| 21 | 4.00000 | 40.0000 | 16.8930 | 3.68110 | 6.69013 |
For the sake of saving space, I intentionally only show the output for the first three and last three observations. Again, the studentized deleted residuals appear in the column labeled "TRES." Minitab reports that the studentized deleted residual for the red data point is \(t_{21} = 6.69013\).
Because n-1-p = 21-1-2 = 18, to determine if the red data point is influential, we compare the studentized deleted residual to a t distribution with 18 degrees of freedom:
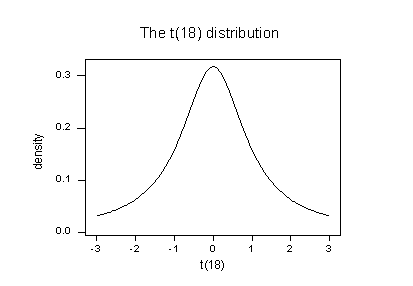
The studentized deleted residual for the red data point (6.69013) sticks out like a sore thumb. Again, it is "off the chart." Based on studentized deleted residuals, the red data point in this example is deemed influential. Incidentally, recall that earlier in this lesson, we deemed the red data point not influential because it did not affect the estimated regression equation all that much. On the other hand, the red data point did substantially inflate the mean square error. Perhaps it is in this sense that one would want to treat the red data point as influential.