Let's return to the skin cancer mortality example (Skin Cancer data) and investigate the research question, "Is there a (linear) relationship between skin cancer mortality and latitude?"
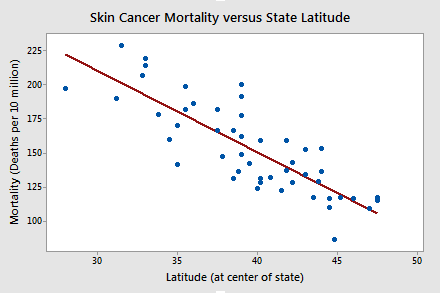
Review the following scatter plot and estimated regression line. What does the plot suggest for answering the above research question? The linear relationship looks fairly strong. The estimated slope is negative, not equal to 0.
We can answer the research question using the P-value of the t-test for testing:
- the null hypothesis \(H_{0} \colon \beta_{1} = 0\)
- against the alternative hypothesis \(H_{A} \colon \beta_{1} ≠ 0\).
As the Minitab output below suggests, the P-value of the t-test for "Lat" is less than 0.001. There is enough statistical evidence to conclude that the slope is not 0, that is, there is a linear relationship between skin cancer mortality and latitude.
There is an alternative method for answering the research question, which uses the analysis of variance F-test. Let's first look at what we are working towards understanding. The (standard) "analysis of variance" table for this data set is highlighted in the Minitab output below. There is a column labeled F, which contains the F-test statistic, and there is a column labeled P, which contains the P-value associated with the F-test. Notice that the P-value, 0.000, appears to be the same as the P-value, 0.000, for the t-test for the slope. The F-test similarly tells us that there is enough statistical evidence to conclude that there is a linear relationship between skin cancer mortality and latitude.
Analysis of Variance
| Source | DF | Adj SS | Adj MS | F-Value | P-Value |
|---|---|---|---|---|---|
| Constant | 1 | 36464 | 36464 | 99.80 | 0.000 |
| Residual Error | 47 | 17173 | 365 | ||
| Total | 48 | 53637 |
Model Summary
| S | R-sq | R-sq(adj) |
|---|---|---|
| 19.12 | 68.0% | 67.3% |
Coefficients
| Predictor | Coef | SE Coef | T-Value | P-Value |
|---|---|---|---|---|
| Constant | 389.19 | 23.81 | 16.34 | 0.000 |
| Lat | -5.9776 | 0.5984 | -9.99 | 0.000 |
Regression Equation
Mort = 389 - 5.98 Lat
Now, let's investigate what all the numbers in the table represent. Let's start with the column labeled SS for "sums of squares." We considered sums of squares in Lesson 1 when we defined the coefficient of determination, \(r^2\), but now we consider them again in the context of the analysis of variance table.
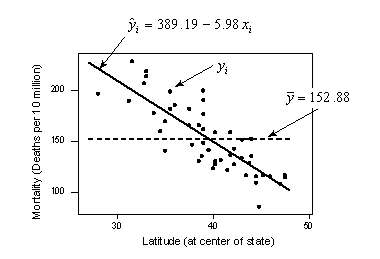
The scatter plot of mortality and latitude appears again below, but now it is adorned with three labels:
- \(y_{i}\) denotes the observed mortality for the state i
- \(\hat{y}_i\) is the estimated regression line (solid line) and therefore denotes the estimated (or "fitted") mortality for the latitude of the state i
- \(\bar{y}\) represents what the line would look like if there were no relationship between mortality and latitude. That is, it denotes the "no relationship" line (dashed line). It is simply the average mortality of the sample.
If there is a linear relationship between mortality and latitude, then the estimated regression line should be "far" from the no relationship line. We just need a way of quantifying "far." The above three elements are useful in quantifying how far the estimated regression line is from the no relationship line. As illustrated by the plot, the two lines are quite far apart.
\(\sum_{i=1}^{n}(\hat{y}_i-\bar{y})^2 =36464\)
\(\sum_{i=1}^{n}(y_i-\hat{y}_i)^2 =17173\)
\(\sum_{i=1}^{n}(y_i-\bar{y})^2 =53637\)
- Total Sum of Squares
-
The distance of each observed value \(y_{i}\) from the no regression line \(\bar{y}\) is \(y_i - \bar{y}\). If you determine this distance for each data point, square each distance, and add up all of the squared distances, you get:
\(\sum_{i=1}^{n}(y_i-\bar{y})^2 =53637\)
Called the "total sum of squares," it quantifies how much the observed responses vary if you don't take into account their latitude.
- Regression Sum of Squares
-
The distance of each fitted value \(\hat{y}_i\) from the no regression line \(\bar{y}\) is \(\hat{y}_i - \bar{y}\). If you determine this distance for each data point, square each distance, and add up all of the squared distances, you get:
\(\sum_{i=1}^{n}(\hat{y}_i-\bar{y})^2 =36464\)
Called the "regression sum of squares," it quantifies how far the estimated regression line is from the no relationship line.
- Error Sum of Squares
-
The distance of each observed value \(y_{i}\) from the estimated regression line \(\hat{y}_i\) is \(y_i-\hat{y}_i\). If you determine this distance for each data point, square each distance, and add up all of the squared distances, you get:
\(\sum_{i=1}^{n}(y_i-\hat{y}_i)^2 =17173\)
Called the "error sum of squares," as you know, it quantifies how much the data points vary around the estimated regression line.
In short, we have illustrated that the total variation in observed mortality y (53637) is the sum of two parts — variation "due to" latitude (36464) and variation just due to random error (17173). (We are careful to put "due to" in quotes in order to emphasize that a change in latitude does not necessarily cause a change in mortality. All we could conclude is that latitude is "associated with" mortality.)