A "binary predictor" is a variable that takes on only two possible values. Here are a few common examples of binary predictor variables that you are likely to encounter in your own research:
- Gender (male, female)
- Smoking status (smoker, nonsmoker)
- Treatment (yes, no)
- Health status (diseased, healthy)
- Company status (private, public)
Example 8-2: On average, do smoking mothers have babies with lower birth weight? Section
In the previous section, we briefly investigated data (Birth and Smokers data) on a random sample of n = 32 births that allow researchers (Daniel, 1999) to answer the above research question. The researchers collected the following data:
- Response \(\left(y\right)\colon\) birth weight (Weight) in grams of baby
- Potential predictor \(\left(x_1\right)\colon\) length of gestation (Gest) in weeks
- Potential predictor \(\left(y\right)\colon\) Smoking status of mother (smoker or non-smoker)
To include a qualitative variable in a regression model, we have to "code" the variable, that is, assign a unique number to each of the possible categories. A common coding scheme is to use what's called a "zero-one-indicator variable." Using such a variable here, we code the binary predictor Smoking as:
- \(x_{i2} = 1\), if mother i smokes
- \(x_{i2} = 0\), if mother i does not smoke
In doing so, we use the tradition of assigning the value of 1 to those having the characteristic of interest and 0 to those not having the characteristic. Tradition is less important, though than making sure you keep track of your coding scheme so that you can properly draw conclusions. Incidentally, other terms sometimes used instead of "zero-one-indicator variable" are "dummy variable" or "binary variable".
A scatter plot of the data in which blue circles represent the data on non-smoking mothers \(\left(x_{2} = 0 \right)\) and red circles represent the data on smoking mothers \(\left(x_{2} = 1 \right)\colon \)
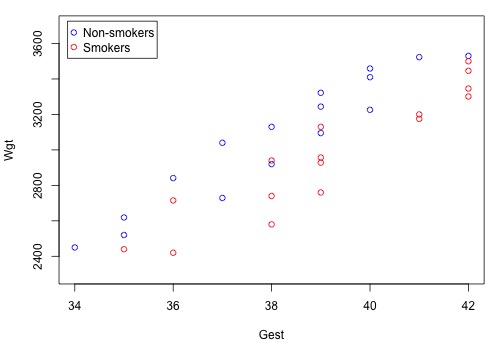
suggests that there might be two distinct linear trends in the data — one for smoking mothers and one for non-smoking mothers. Therefore, a first-order model with one binary and one quantitative predictor appears to be a natural model to formulate for these data. That is:
\(y_i=(\beta_0+\beta_1x_{i1}+\beta_2x_{i2})+\epsilon_i\)
where:
- \(y_{i}\) is the birth weight of baby i in grams
- \(x_{i1}\) is the length of gestation of baby i in weeks
- \(x_{i2} = 1\), if the mother smoked during pregnancy, and \(x_{i2} = 0\), if she did not
and the independent error terms \(\epsilon_{i}\) follow a normal distribution with mean 0 and equal variance \(\sigma^{2}\).
How does a model containing a (0,1) indicator variable for two groups yield two distinct response functions? In short, this screencast below illustrates how the mean response function:
\(\mu_Y=\beta_0+\beta_1x_{i1}+\beta_2x_{i2}\)
yields one regression function for non-smoking mothers \(\left(x_{i2} = 0\right)\colon\)
\(\mu_Y=\beta_0+\beta_1x_{i1}\)
and one regression function for smoking mothers \(\left(x_{i2} = 1\right)\colon\)
\(\mu_Y=(\beta_0+\beta_2)+\beta_1x_{i1}\)
Note that the two formulated regression functions have the same slope \(\left(\beta_1\right)\) but different intercepts \(\left(\beta_0\ \text{and}\ \beta_0 + \beta_2 \right)\) — mathematical characteristics that, based on the above scatter plot, appear to summarize the trend in the data well.
Now, given that we generally use regression models to answer research questions, we need to figure out how each of the parameters in our model enlightens us about our research problem! The fundamental principle is that you can determine the meaning of any regression coefficient by seeing what effect changing the value of the predictor has on the mean response μY. Here's the interpretation of the regression coefficients in a regression model with one (0, 1) binary indicator variable and one quantitative predictor:
- \(\beta_1\) represents the change in the mean response \(\mu_Y\) for each additional unit increase in the quantitative predictor \(x_1\) ... for both groups.
- \(\beta_2\) represents how much higher (or lower) the mean response function of the second group is than that of the first group... for any value of \(x_1\).
Upon fitting our formulated regression model to our data, Minitab tells us:
Regression Equation
Wgt = - 2390 + 143.10 Gest - 244.5 Smoke
Unfortunately, Minitab doesn't precede the phrase "regression equation" with the adjective "estimated" to emphasize that we've only obtained an estimate of the actual unknown population regression function. But anyway — if we set Smoking once equal to 0 and once equal to 1 — we obtain, as hoped, two distinct estimated lines:
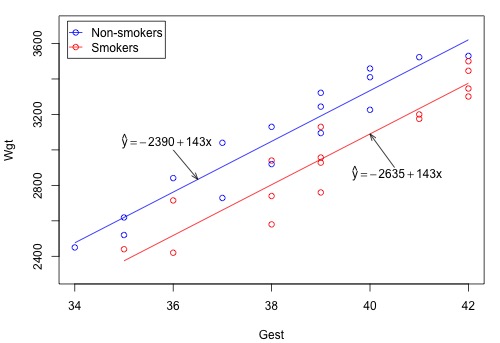
Now, let's use our model and analysis to answer the following research question: Is there a significant difference in mean birth weights for the two groups, after taking into account the length of gestation? As is always the case, the first thing we need to do is to "translate" the research question into an appropriate statistical procedure. We can show that if the slope parameter \(\beta_2\) is 0, there is no difference in the means of the two groups — for any length of gestation. That is, we can answer our research question by testing the null hypothesis \(H_0 \colon \beta_2 = 0\) against the alternative \(H_{A} \colon \beta_2 \ne 0\).
Well, that's easy enough! The Minitab output:
Model Summary
| S | R-sq | R-sq(adj) | R-sq(pred) |
|---|---|---|---|
| 115.530 | 89.64% | 88.92% | 87.60% |
Model Summary
| Term | Coef | SE Coef | T-Value | P-Value | VIF |
|---|---|---|---|---|---|
| Constant | -2390 | 349 | -6.84 | 0.000 | |
| Gest | 143.10 | 9.13 | 15.68 | 0.000 | 1.06 |
| Smoke | -244.5 | 42.0 | -5.83 | 0.000 | 1.06 |
Regression Equation
Wgt = - 2390 + 143.10 Gest - 244.5 Smoke
Reports that the P-value is < 0.001 for testing \(H_0 \colon \beta_2 = 0\). At just about any significance level, we can reject the null hypothesis \(H_0 \colon \beta_2 = 0\) in favor of the alternative hypothesis \(H_{A} \colon \beta_2 \ne 0\). There is sufficient evidence to conclude that there is a statistically significant difference in the mean birth weight of all babies of smoking mothers and the mean birth weight of babies of all non-smoking mothers, after taking into account the length of gestation.
A 95% confidence interval for \(\beta_2\) tells us the magnitude of the difference. A 95% t-multiplier with n-p = 32-3 = 29 degrees of freedom is \(t_{\left(0.025, 29\right)} = 2.0452\). Therefore, a 95% confidence interval for \(\beta_2\) is:
-244.54 ± 2.0452(41.98) or (-330.4, -158.7).
We can be 95% confident that the mean birth weight of smoking mothers is between 158.7 and 330.4 grams less than the mean birth weight of non-smoking mothers, regardless of the length of gestation. It is up to the researchers to debate whether or not the difference is meaningful.
Try it!
A model with a binary predictor Section
\(\mu_Y|(x_{i1}=x+1) = \beta_0+\beta_1(x+1)\)
\(\mu_Y|(x_{i1}=x) = \beta_0+\beta_1 x\)
Take the difference,
\(\mu_Y|(x_{i1}=x+1) - \mu_Y|(x_{i1}=x) = \beta_0+\beta_1(x+1) - (\beta_0+\beta_1 x) = \beta_1\)